

I recently had the opportunity to speak at the Unstructured Data meetup, where I discussed the steps for creating real-time ingestion pipelines for RAG apps using Bytewax. You can find the session recording here. Below is a summary of what was covered in the presentation.
❗️If you are not sure what RAG is please go check out = this post + our workshop + Zander's talk → inspired my presentation.
What are the key steps in the RAG for improving query responses?
Let's tackle this together 💪
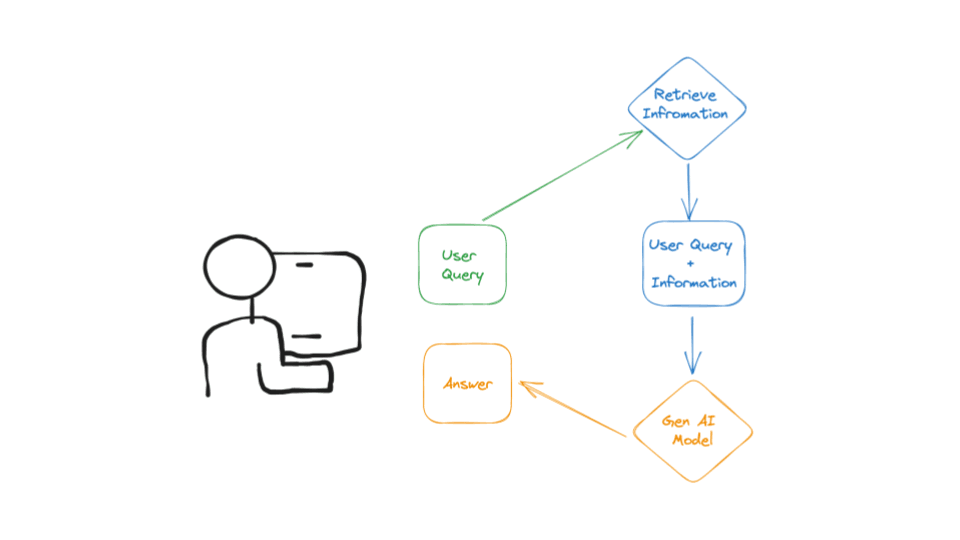
Above is a high-level architecture diagram of a RAG application. It always starts with a user query, followed by fetching additional context from external sources such as Google, Bing, or internal storages. This context is combined with the original query and processed by the GenAI model to generate context-informed answers.
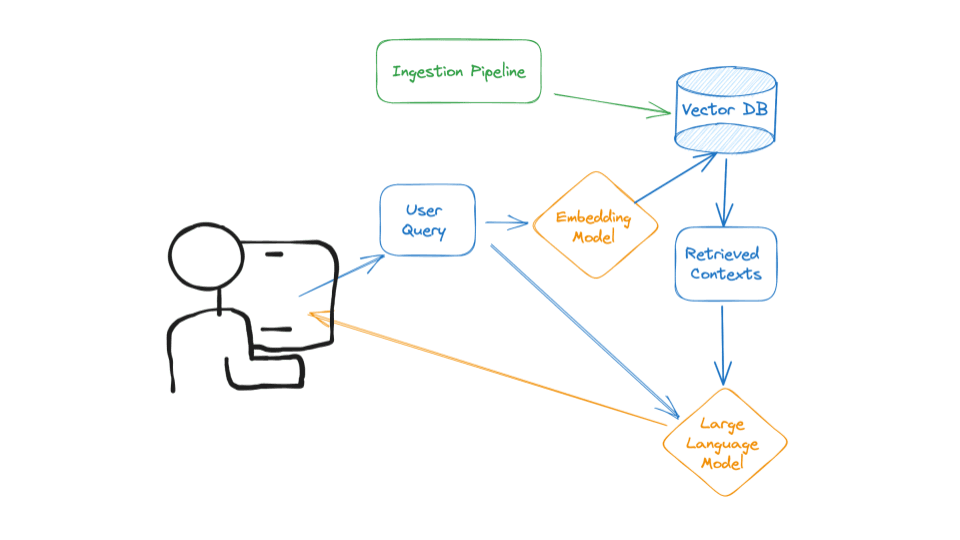
The goal 🎯 is to develop an asynchronous pipeline to store real-time or near-real-time context in a storage, in our case, we will use a vector database. This involves creating an ingestion pipeline for collecting data from live data sources and storing it in a vector database. This setup will then support the AI application in processing user queries by creating embeddings and comparing them with stored data to find relevant information.
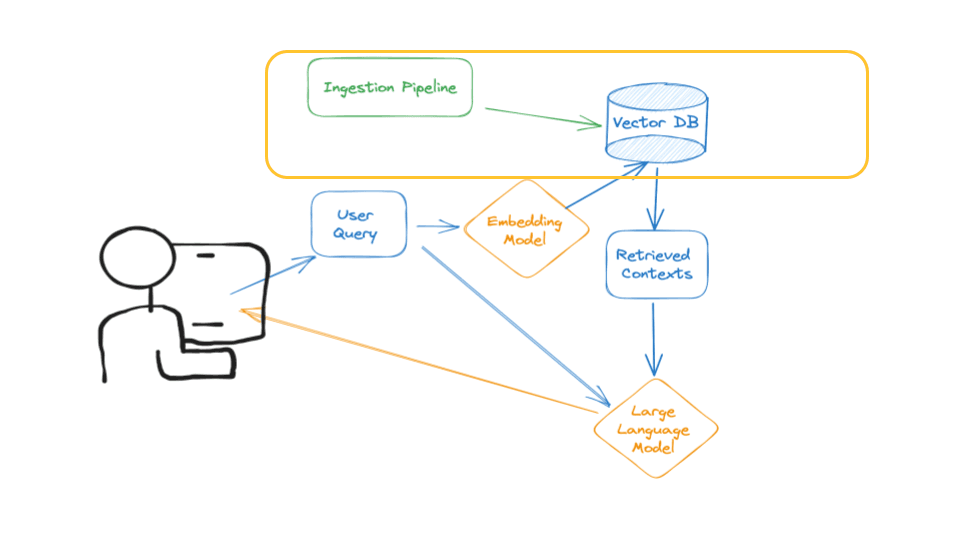
Note: The focus of my presentation and this blog is the construction of the ingestion pipeline, emphasizing the integration of live contextual data into the system to enhance query responses. 🔄
Go play with the repo and don’t forget to ⭐️ 😉

Ingestion pipeline overview
Next, we'll pause to review the overall pipeline diagram.
At the highest level, creating a dataflow with Bytewax involves:
→ defining an input → applying transformations via operators → defining an output
Effectively, it forms a Directed Acyclic Graph (DAG). Let's take a look at our example:
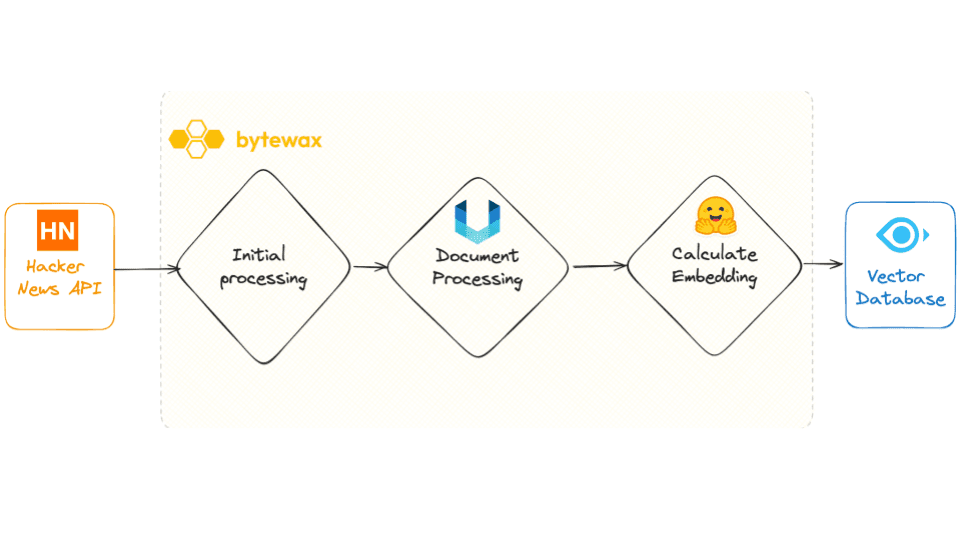
This directed graph represents a dataflow that:
→ fetches a set of IDs from Hacker News every 15 seconds → processes them and retrieves associated metadata such as titles and URLs → subsequently, fetches the HTML content from these URLs → processes using the the Unstructured library, a notable tool from the 🐍 ecosystem. → generates embeddings with a model from Hugging Face → writes the results to a Milvus sink.
The essence of Bytewax lies in its role as a ⇔ connector, facilitating the seamless flow of these steps. Bytewax's API offers a variety of operators that manage the dataflow, allowing the use of Python code within these operators for data transformations, including splitting (↦), joining (⨝), windowing (⊞), or mapping (↦).
This streamlined approach not only simplifies complex data processing tasks but also ensures that the process is accessible and comprehensible.
Example: Hacker News API embeddings in real-time
To get a clear understanding, head over to the repository, and for an in-depth explanation, check out my 🎥 presentation.
We'll bypass the sections already discussed in other articles (here & here and jump straight to the pipeline's final segment.
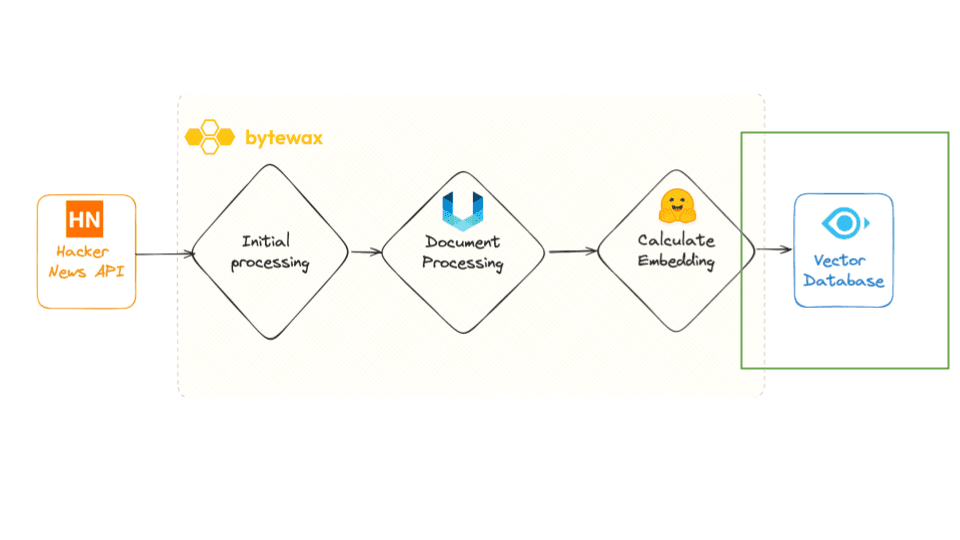
At this point, we've progressed from IDs to URLs, then from HTML to text chunks, and finally from text chunks to vectors. The next step** is inserting our vectors into the vector database.**
To achieve this, we need to furnish the database with details about the data we intend to store, including metadata and the vectors. Our storage strategy aims to enable the retrieval of comprehensive information related to each text chunk. Considering that a chunk may not fully represent the entire document, and we might require access to the complete document for additional insights, we'll store our data in Milvus with a unique ID. This ID will link each piece to its respective document part, facilitating the retrieval of all related segments.
*N.B. I used Milvus Lite for this project. You can find more information about it here. Check out Milvus CLI as well!*
Milvus output connector
This code highlights the Milvus connector. I utilized the pymilvus library for seamless integration with Python.
from pymilvus import ...
class MilvusOutput(DynamicSink):
def __init__(self, collection_name, schema, host="localhost", port="19530"):
self.collection_name = collection_name
connections.connect("default", host=host, port=port)
logger.info(f"List connections: {connections.list_connections()}")
if utility.has_collection(collection_name):
collection = Collection(collection_name)
collection.drop()
logger.info(f"Drop collection: {collection_name}")
self.collection = Collection(collection_name, schema)
def build(self, worker_index, worker_count):
return _MilvusSink(self.collection, self.collection_name)
Configuring a worker is an essential first step:
- Initiate a connection to Milvus using
connections.connectand specify the host and the port. - Check for the existence of a collection by name using
utility.has_collection. If it's present, drop the existing collection. - Create a new collection with the specified schema and name.
After the initial configuration, let's outline the process of inserting data into the database.
class _MilvusSink(StatelessSinkPartition):
def __init__(self, collection, collection_name):
self.collection = collection
self._collection_name = collection_name
def write_batch(self, documents):
logger.info(f"Start inserting")
self.collection.insert(list(chain.from_iterable(documents)))
self.collection.flush()
index = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
self.collection.create_index("doc_embedding", index)
How can incoming data batches be managed in the stream and inserted into the vector database? 3 simple steps! While this example covers Milvus, you could write your own output sink with minimal changes!
For each new batch of text chunks received:
- Execute the
self.collection.insert - Ensure consistency with a
self.collection.flush. It's crucial that the data matches the format specified by the schema. - Create the index
self.collection.create_index(it is not strictly necessary for Milvus, though)
And our Milvus output connector is done!
Conclusion
Bytewax is user-friendly in RAG environments and easily integrates with various systems. We've now demonstrated its integration with Milvus in just a few lines!
Explore further:
- Blog 🔓: Hacking Hacker News with Proton and Grafana
- Repo 👨💻: Redis for real time embeddings
- Workshop 🤖: Supercharge Slackbots with RAG in real-time using Slack API, YOKOT.AI, and Qdrant* Join us in Slack 💬:
- Use our Bitly link 🔗: the one-stop for all things Bytewax - https://bit.ly/m/bytewax
Cooking up real-time pizza order analytics

Oli Dinov
Director of Developer Relations and OperationsOli is a passionate technologist with a background in engineering, consulting, and community building. On a break from creating content, she loves to network online & in person at meetups, conferences, and forums.
Celebrating 1000 stars on GitHub ⭐️
Other posts you may find interesting
View all articles

Cooking up real-time pizza order analytics
Join our workshop on Mar 19th with Startree, Streamlit. We'll create a real-time 🍕 analytics dashboard in just 2 hours.
Written by Oli Makhasoeva & Anastasia Khomyakova