
Data Parallel, Task Parallel, and Agent Actor Architectures
Exploring the Landscapes of Data Processing Architectures: Mechanisms, Advantages, Disadvantages, and Best Use Cases.
Written by Zander Matheson, Konrad Sienkowski & Oli Makhasoeva
To skip the words and go straight to the code check out the jupyter notebook you can customize.
ChatGPT and other Generative AI chatbots are amazing, they can write blog posts, emails, fix bugs, document code and have been shown to complete tasks like planning trips all based off of natural language prompts. Despite all of the capabilities they fall short with respect to the most recent information of the world, out-of-domain knowledge or might provide incorrect information without the right prompting.
The solution to helping the language model with those areas that it falls short is sophisticated prompt templating and injecting information into the context. For example, if I were to ask chatGPT,
"What happened with Meta in the news today?"
I would get the response:
"I'm sorry, but my training data only goes up until September 2021, and I'm unable to provide real-time news updates. To find out the latest news about Meta (formerly known as Facebook), please visit a reliable news website or search for "Meta news" in your preferred search engine."
But I could solve this problem by providing more information as context and the right prompt. For example I could copy and paste an article and change the prompt to something like:
"Given this article from today:
Article about META in the news today. Answer the following: What happened with Meta in the news today?"
I now get the response:
"In the news today, Elon Musk, the CEO of Tesla and owner of Twitter, has accused Meta's messaging app, WhatsApp, of being untrustworthy. The accusation was based on a tweet by a Twitter engineer, Foad Dabiri, who claimed that WhatsApp had been using the microphone in the background without their knowledge. Musk pointed out that WhatsApp cannot be trusted and reminded people that WhatsApp is owned by Meta (previously Facebook) and that its founders left Meta in disagreement over its policies and decisions, particularly regarding personal data processing. This news may have an impact on Meta's public image and its platforms, as trust and privacy are crucial factors for users of social media and messaging apps."
This is basic and over simplified, but the idea is that we can help the language model provide what we ultimately want with a little bit of work asking the right things and giving it the right information as context.
Since we understand that this works for our one-off use case, how can we make something that will scale to many questions about different subjects? This is where vector databases and embeddings come into play.
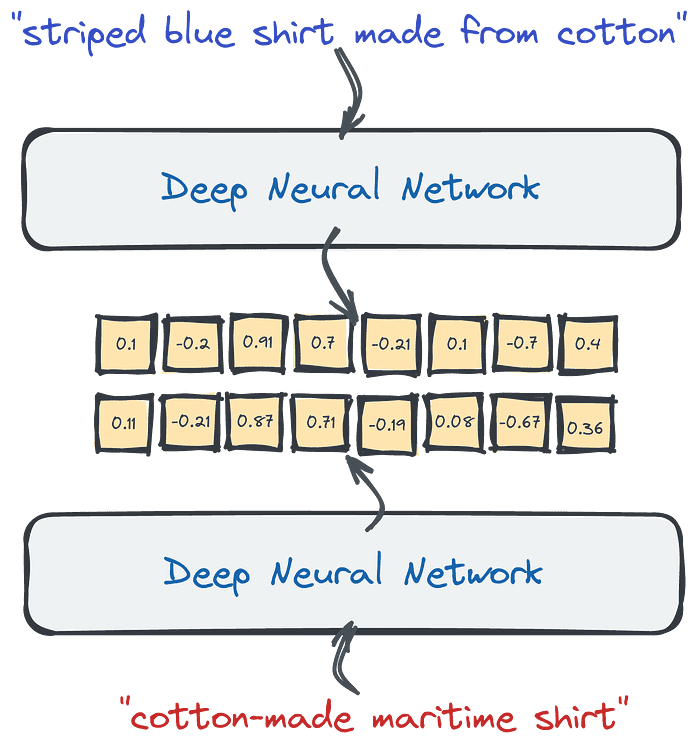
An Introduction to the Power of Vector Search for Beginners. (2022, Dec 6). In Hackernoon.
An embedding is simply a representation of something like a word as a vector in a multi-dimensional space. In other words a list of numbers like [.89, .65, .45, ...]. It is a way to intelligently turn categorical things into numerical representations so that we can reason about them in different ways, like determine how similar they are by grouping them in multi-dimensional space.
A vector database is a database that allows us to store our embeddings as vectors and index them in a way so that we can efficiently retrieve them based on similarity. Since the vectors can be compared for similarity, our query against the database will be able to return the most similar items.
Putting together the pieces, in theory, if we can represent the most recent news as vectors in a vector database, we should be able to ask questions of a chatbot about the most recent news articles. In order to do this, we will need to consume news from a real-time source, process them to turn the articles into embeddings and then store them in a vector database. Then when we receive a question, we can use the vector database to pull articles similar to what has been asked and inject that information infront of the language model to receive up-to-date responses from the model.
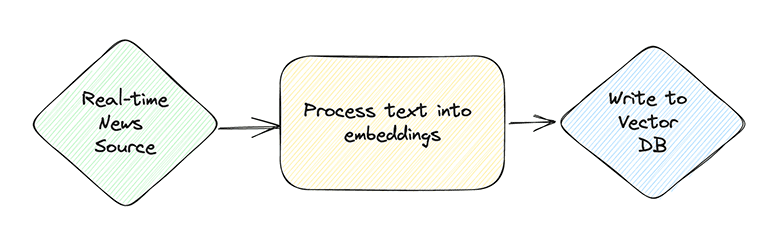
To support the ingestion, we will need to make a pipeline that is capable of ingesting data in real-time, processing it, running it against an ML model to create an embedding and then write it to a vector database. We can use Bytewax as the real-time processing framework.
We are going to leverage Bytewax to create a real-time embedding pipeline from a live news source, in this case it is a financial news source via Alpaca. This pipeline could be scaled to consume many different news sources and aggregate them all into a vector database like Qdrant shown below.
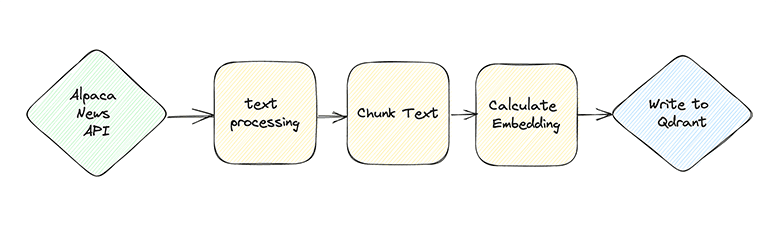
We are using Bytewax to build our pipeline. Bytewax is a framework for data processing that is easily parallelized and well suited for streaming data with capabilities like windowing functions and aggregations.
With Bytewax we can define custom input classes based off of the Bytewax classes DynamicInput and StatelessSource to wrap up a variety of input sources outside of what is available in the core library. The DynamicInput is the entrypoint for our input, this is where we establish what will happen on each worker. A handler to the StatelessSource is returned when the build method is called. While the dataflow is running, the next method of the StatelessSource will be called continually. Note that this input design is explicitly stateless and will not be able to recover lost data in the case of a crash because the websocket does not provide a way for us to request old data. For our pipeline we are going to define a custom input based off of the Alpaca real-time financial news API which is exposed as a websocket.
import json
import logging
from bytewax.dataflow import Dataflow
from bytewax.inputs import DynamicInput, StatelessSource
from websocket import create_connection
API_KEY = os.getenv("API_KEY")
API_SECRET = os.getenv("API_SECRET")
# Creating an object
logger=logging.getLogger()
# Setting the threshold of logger to DEBUG
logger.setLevel(logging.DEBUG)
class AlpacaSource(StatelessSource):
def __init__(self, worker_tickers):
# set the workers tickers
self.worker_tickers = worker_tickers
# establish a websocket connection to alpaca
self.ws = create_connection("wss://stream.data.alpaca.markets/v1beta1/news")
logger.info(self.ws.recv())
# authenticate to the websocket
self.ws.send(
json.dumps(
{"action":"auth",
"key":f"{API_KEY}",
"secret":f"{API_SECRET}"}
)
)
logger.info(self.ws.recv())
# subscribe to the tickers
self.ws.send(
json.dumps(
{"action":"subscribe","news":self.worker_tickers}
)
)
logger.info(self.ws.recv())
def next(self):
return self.ws.recv()
class AlpacaNewsInput(DynamicInput):
"""Input class to receive streaming news data
from the Alpaca real-time news API.
Args:
tickers: list - should be a list of tickers, use "*" for all
"""
def __init__(self, tickers):
self.TICKERS = tickers
# distribute the tickers to the workers. If parallelized
# workers will establish their own websocket connection and
# subscribe to the tickers they are allocated
def build(self, worker_index, worker_count):
prods_per_worker = int(len(self.TICKERS) / worker_count)
worker_tickers = self.TICKERS[
int(worker_index * prods_per_worker) : int(
worker_index * prods_per_worker + prods_per_worker
)
]
return AlpacaSource(worker_tickers)
flow = Dataflow()
flow.input("input", AlpacaNewsInput(tickers=["*"]))
flow.inspect(print)
In the code shown above we are defining the AlpacaNewsInput as a class inheriting from the Bytewax DynamicInput class with an initialization function that assigns a list of tickers and then a build function which splits the tickers over the workers. This is designed purposefully in order to parallelize the requests.
The AlpacaNewsInput build method returns a AlpacaSource class which will subscribe to the mebsocket and then we have a AlpacaSource.next method defined which receives data from the websocket. Bytewax will continually check if new data has been received and progress accordingly.
It is important to note that the API_KEY and API_SECRET need to be set in order for this to be set properly. To setup credentials in Alpaca, you can follow their documentation.
With our input configured, we will move on to processing our data. We will use pydantic to define a model for our document and then use unstructured to process the text. Finally, to finish preparing the data we will chunk the text into the appropriate lengths.
import json
from unstructured.partition.html import partition_html
from unstructured.cleaners.core import clean, replace_unicode_quotes, clean_non_ascii_chars
from unstructured.staging.huggingface import chunk_by_attention_window
from unstructured.staging.huggingface import stage_for_transformers
import hashlib
from pydantic import BaseModel
from typing import Any, Optional
class Document(BaseModel):
id: str
group_key: Optional[str] = None
metadata: Optional[dict] = {}
text: Optional[list]
chunks: Optional[list]
embeddings: Optional[list] = []
flow.flat_map(lambda x: json.loads(x))
# Clean the code and setup the dataclass
def parse_article(_data):
document_id = hashlib.md5(_data['content'].encode()).hexdigest()
document = Document(id = document_id)
article_elements = partition_html(text=_data['content'])
_data['content'] = clean_non_ascii_chars(replace_unicode_quotes(clean(" ".join([str(x) for x in article_elements]))))
_data['headline'] = clean_non_ascii_chars(replace_unicode_quotes(clean(_data['headline'])))
_data['summary'] = clean_non_ascii_chars(replace_unicode_quotes(clean(_data['summary'])))
document.text = [_data['headline'], _data['summary'], _data['content']]
document.metadata['headline'] = _data['headline']
document.metadata['summary'] = _data['summary']
document.metadata['url'] = _data['url']
document.metadata['symbols'] = _data['symbols']
document.metadata['author'] = _data['author']
document.metadata['created_at'] = _data['created_at']
return document
flow.map(parse_article)
# chunk the news article and summary
def chunk(document):
chunks = []
for text in document.text:
chunks += chunk_by_attention_window(text, tokenizer, max_input_size=384)
document.chunks = chunks
return document
flow.map(chunk)
To calculate an embedding we can use a pretrained transformer model from Hugging Face. In order to get the vector from the transformer we return the last layer of the computed values which represents the normalized computed vector.
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# create embedding and store in vector db
def embedding(document):
for chunk in document.text:
inputs = tokenizer(chunk, padding=True, truncation=True, return_tensors="pt", max_length=384)
result = model(**inputs)
embeddings = result.last_hidden_state[:, 0, :].cpu().detach().numpy()
lst = embeddings.flatten().tolist()
document.embeddings.append(lst)
return document
flow.map(embedding)
flow.inspect(print)
Now that we have our embeddings, we will use Bytewax to create an output into a vector database. There are a number of vector databases available on the market ranging from addons to commond relational databases like SQLite and Postgres to purpose built vector databases like Pinecone and Qdrant. For this tutorial we are using Qdrant (pronounced Quadrant) because of its simple in-memory development version, straightforward API and performant rust engine.
To use Qdrant with Bytewax we will build on the DynamicOutput and StatelessSink class. The way that these work in Bytewax we will overwrite the DynamicOutput.build method with a QdrantVectorOutput version that will return _QdrantVectorSink that inherits from the StatelessSink class and we will overwrite the StatelessSink.write method.
import datetime
from bytewax.outputs import DynamicOutput, StatelessSink
from qdrant_client.http.models import Distance, VectorParams
from qdrant_client.models import PointStruct
from qdrant_client.http.api_client import UnexpectedResponse
def build_payloads(doc):
payloads = []
for chunk in doc.chunks:
payload = doc.metadata
payload.update({"text":chunk})
payloads.append(payload)
return payloads
class _QdrantVectorSink(StatelessSink):
def __init__(self, client, collection_name):
self._client=client
self._collection_name=collection_name
def write(self, doc):
_payloads = build_payloads(doc)
self._client.upsert(
collection_name=self._collection_name,
points=[
PointStruct(
id=idx,
vector=vector,
payload=_payload
)
for idx, (vector, _payload) in enumerate(zip(doc.embeddings, _payloads))
]
)
class QdrantVectorOutput(DynamicOutput):
"""Qdrant.
Workers are the unit of parallelism.
Can support at-least-once processing. Messages from the resume
epoch will be duplicated right after resume.
"""
def __init__(self, collection_name, vector_size, host='localhost', port=6333, client=None):
self.collection_name=collection_name
self.vector_size=vector_size
if client:
self.client = client
else:
self.client=QdrantClient(host, port=port)
try:
self.client.get_collection(collection_name="test_collection")
except (UnexpectedResponse, ValueError):
self.client.recreate_collection(
collection_name="test_collection",
vectors_config=VectorParams(size=self.vector_size, distance=Distance.COSINE),
schema=self.schema
)
def build(self, worker_index, worker_count):
return _QdrantVectorSink(self.client, self.collection_name)
flow.output("output", QdrantVectorOutput("test_collection", 384, client=client))
The QdrantVectorOutput will be initialized on the Bytewax worker and then for each additional Document, the write method will be called.
In the write method we are formating the data correctly and then inserting it into our collection in Qdrant.
To run our pipeline in the notebook, we use the bytewax method run_main which allows us to execute in the same process.
from bytewax.testing import run_main
run_main(flow)
Alternatively, you could run Bytewax as a python module
python -m bytewax.run embedding_pipeline:flow
The process to use the information retrieved from our vector database is to "inject" context into the prompt and instruct openAI's GPT or another similar generative model to answer questions. So once we run our pipeline (you will have to keyboard interupt Bytewax since we are using the in-memory Qdrant), we can test it out by asking some questions and retrieving the most similar data in the database.
query_string = "what is new on META"
inputs = tokenizer(query_string, padding=True, truncation=True, return_tensors="pt", max_length=384)
result = model(**inputs)
embeddings = result.last_hidden_state[:, 0, :].cpu().detach().numpy()
lst = embeddings.flatten().tolist()
query_vector = lst
hits = client.search(
collection_name="test_collection",
query_vector=query_vector,
limit=5 # Return 5 closest points
)
You could now expand on the chatbot interface we wrote earlier to plug into our vector database and inject the context into the prompt.
Like this content? Give us a star @bytewax/bytewax.


