
Cooking up real-time pizza order analytics
Join our workshop on Mar 19th with Startree, Streamlit. We'll create a real-time 🍕 analytics dashboard in just 2 hours.
Written by Oli Makhasoeva & Anastasia Khomyakova
On February 16th at 9:00 AM PST, Bytewax and Soflandia will conduct a collaborative online workshop, hosted by AIcamp. This free workshop, focusing on the intersection of AI and real-time communication, is scheduled to last approximately 2 hours. Participants will learn how to build a RAG-enhanced Slackbot.
Your takeaway from this workshop will be a RAG supercharged slackbot.
We'll start with a brief introduction of the technologies we will use.
We will also go through the agenda and pre-shared materials.
Bytewax currently supports the following versions of Python: 3.8, 3.9, 3.10 and 3.11.
We recommend creating a virtual environment for your project when installing Bytewax. For more information on setting up a virtual environment, see the Python documentation.
Once you have your environment set up, you can install Bytewax. We recommend that you pin the version of Bytewax that you are using in your project by specifying the version of Bytewax that you wish to install:
pip install bytewax==0.18.1
Read more about installing Bytewax in our documentation.
Get the Python client with
pip install 'qdrant-client[fastembed]'
The client uses an in-memory database. You can even run it in Colab or Jupyter Notebook, no extra dependencies required. See an example.
This step is to build a basic data stream. The central concept of Bytewax is a dataflow, which provides the necessary building blocks for choreographing the flow of data. Within Bytewax, a dataflow is a Python object that outlines how data will flow from input sources, the transformations it will undergo, and how it will eventually be passed to the output sinks.
Here, we will be using Slack as an input source, and StdOutSink as a sink.
Bytewax connects to a variety of input sources and output sinks, check out our Getting Started example, Polling Input Example, and more in the blog.
The central part of the workshop covers LLM and RAG. We'll track what the conversation is about using LLM. We'll branch our stream to separate messages that contain a query. To generate responses to the queries, we will use LLM and RAG techniques.
Let's take a look at the diagram:
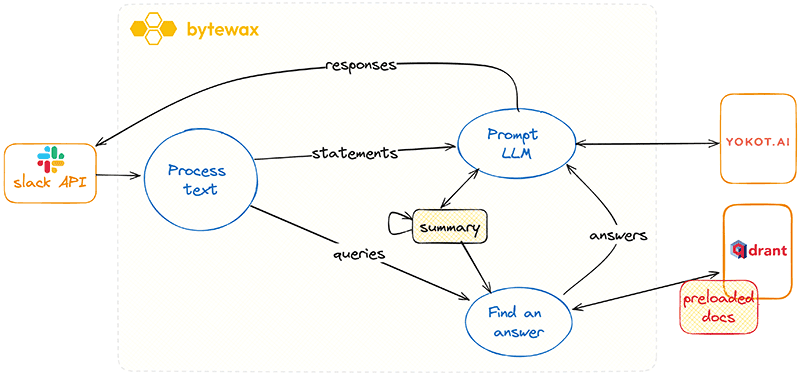
StdOutSink and switch to the Slack API if time allows.Once we build our pipeline, we can ask questions and receive RAG-enriched responses. But so far, we've been using the StdOutSink. In this step, we replace it and will see how to push responses back to a Slack channel.
We'll wrap up with a demo! And discuss what we learned and where to go next.

Henrik Nyman, Co-Founder & Senior Software Architect at Softlandia Oy. Henrik is a distinguished software architect and co-founder of Softlandia Ltd. His expertise spans the design of complex systems such as fully automated factory lines and state-of-the-art measurement devices. The practical experience is paired with a proficiency in Python, C/C++, Rust, and hardware integration, together with a field knowledge in optics, robotics and metrology.
Mikko Lehtimäki, Co-Founder & Data Scientist at Softlandia Oy. Mikko is a data scientist, researcher and software engineer and one of the founders of Softlandia Ltd. He has a long background in working with data in all ways possible. Mikko has contributed to Llama-index and Guardrails-AI, two of the leading open-source initiatives in the LLM space. He is also the beloved host of our Data Science Infrastructure meetups.
Zander Matheson, Founder & CEO at Bytewax. Zander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.
No problem!
We have the entire session recorded for you 👇


