
Analyzing Prolific Hacker News Commenters and Trending Stories in real-time
By Zander Matheson

If you are like me, you eventually get tired of whatever algorithm is serving you your media. Whether it is Twitter (oops, I mean X) or Reddit, or Hacker News (HN). My recent work with the Hacker News API for a conference talk on RAG for AI sparked a new curiosity. After the RAG pipelines for AI work using Hacker News with Bytewax, I was curious about a new challenge: creating a customizable dashboard to serve up my HN stories in a personal way.
In this blog post, I'll share how I (with support from Jove Zhong from Timeplus) combining different technologies (Bytewax, Proton, and Grafana) to create such a personalized dashboard. The combination of the products is really fun (My opinion 🙂); You get the flexibility of imperative programming with Python (Bytewax) and the power of declarative data processing through SQL (Proton).
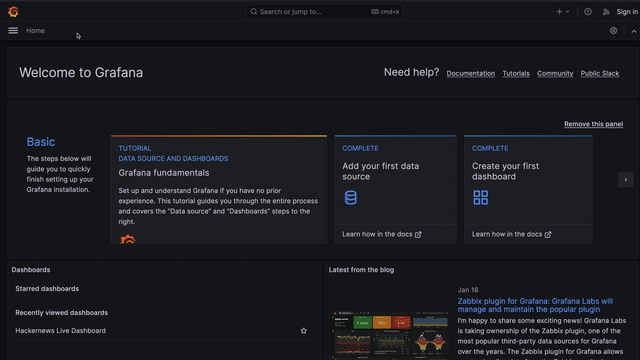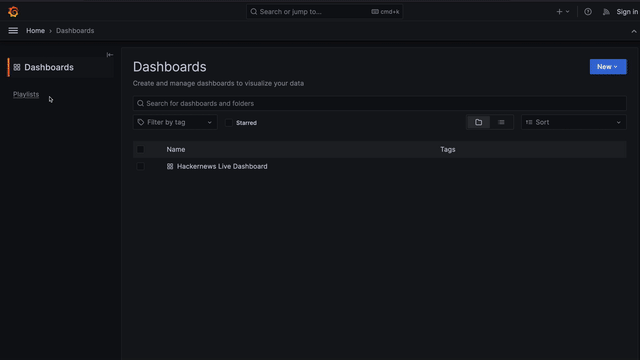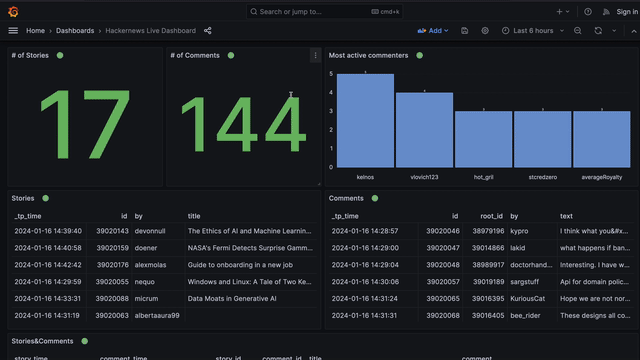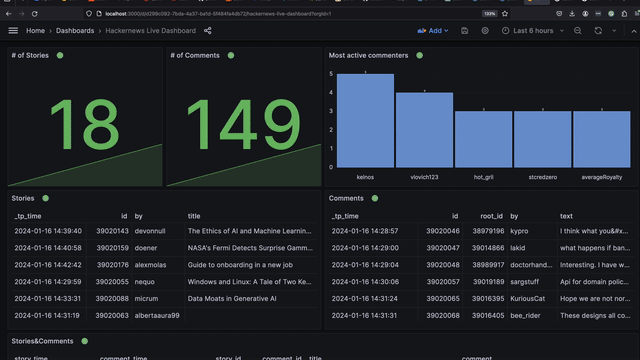
I sketched out the result below. At the end, you'll see a Grafana dashboard that dynamically shows your personalized news. It is powered by a Bytewax pipeline streaming HN stories and comments into Proton where I join and analyze the data in real time.
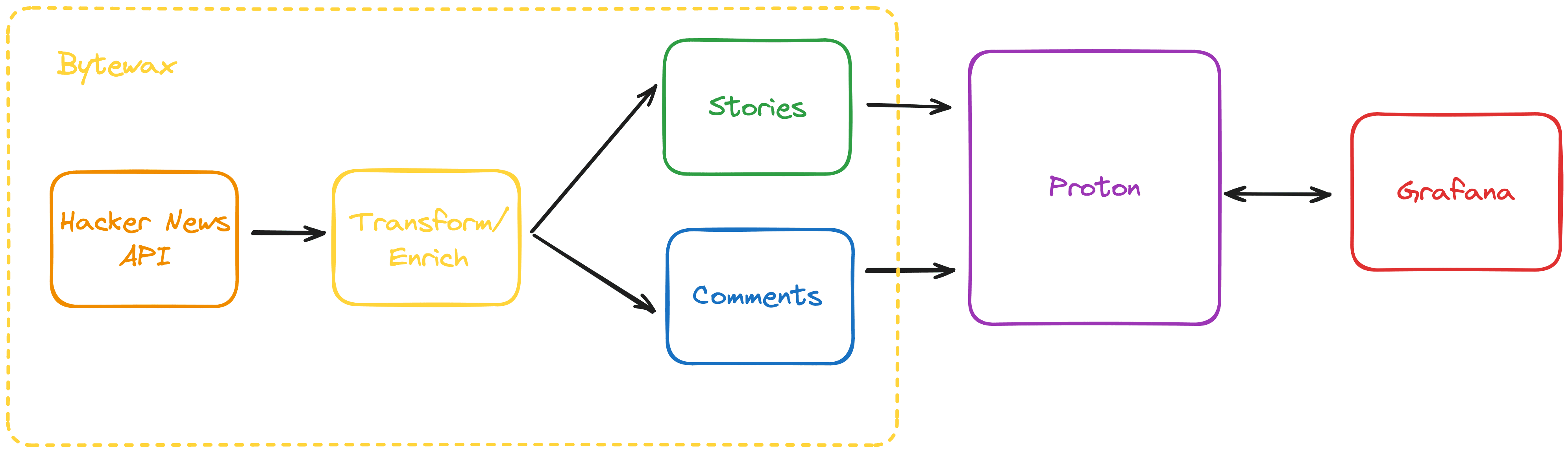
Want to skip to running the code → Run the full pipeline and dashboard with docker compose up.
Introducing Bytewax
Jove Zhong (one of Proton's creators) and I met for a Streaming Caffeine podcast before, I shared why I started Bytewax, and Jove talks about why they started Timeplus/Proton. Watch the whole episode here!
Bytewax is an open-source project known for facilitating custom connections to many data sources. The often complex task of processing streaming data is much more manageable with it. For many of us, its input and output API will look friendly and familiar. The ability to run Python native code and re-use the Python libraries you already know also lowers the learning barrier. In this post, I will showcase these advantages while building a custom input connector that will read Hacker News (yes, the Hacker News) updates to keep track of trending posts and prolific commenters.
Timeplus and Proton
Proton is a really cool open source project built on top of the much-loved project, Clickhouse. The company behind the project, Timeplus was started by Splunk engineers out of their experience and learnings while building streaming engines at Splunk.
As described on their website and marketing materials:
Timeplus is a unified platform tailored for both streaming and historical data processing. At the heart of Timeplus is Proton, an open source project that functions as a streaming SQL engine, a fast and lightweight alternative to Apache Flink in a single binary, powered by ClickHouse. Proton is heralded for its ability to unlock streaming data value using SQL, offering a powerful end-to-end capability for processing streaming and historical data quickly and intuitively.
With Proton, even on a single commodity machine, you can get 4-millisecond end-to-end latency and a benchmark of 10+ million events per second. This powerful core engine is now open-sourced under Apache 2.0 License, providing flexible deployment options with no external service dependencies.
A Harmonious Partnership
The unique capability to easily ingest a variety of data sources with Python in Bytewax and the power of SQL based processing of Proton is a match made in heaven!

Let’s dive into the code!
Building a Custom Input Connector with Bytewax
First things first, I need to connect to the data source. Bytewax is flexible, and I can tailor data ingestion according to my application's needs. In this case, I would like to poll data from the Hacker News API at regular time intervals. Let me walk you through a code snippet that demonstrates how to do that using Bytewax.
Imports skipped for brevity
class HNSource(SimplePollingSource):
def next_item(self):
return (
"GLOBAL_ID",
requests.get("https://hacker-news.firebaseio.com/v0/maxitem.json").json(),
)
_HNSource uses the built-in SimplePollingSource to effectively poll the HN API for the most recent ID.
By following a similar pattern, you can create custom input connectors to a wide variety of APIs. See an example of a coinbase websocket custom input here and a wikimedia SSE stream here.
Writing the dataflow
With our custom connector, now we can write a dataflow to describe the processing after we receive new items from the Hacker News API:
Helper Functions:
The following functions will be used inside of Bytewax operators. Operators are dataflow class methods that control the flow of data.
- Creating the stream with
get_id_stream
def get_id_stream(old_max_id, new_max_id) -> Tuple[str,list]:
if old_max_id is None:
# Get the last 150 items on the first run.
old_max_id = new_max_id - 150
return (new_max_id, range(old_max_id, new_max_id))
download_metadata:
def download_metadata(hn_id) -> Optional[Tuple[str, dict]]:
# Given an hacker news id returned from the api, fetch metadata
# Try 3 times, waiting more and more, or give up
data = requests.get(
f"https://hacker-news.firebaseio.com/v0/item/{hn_id}.json"
).json()
if data is None:
logger.warning(f"Couldn't fetch item {hn_id}, skipping")
return None
return (str(hn_id), data)
- This function is designed to fetch metadata for a specific Hacker News item using its ID. If the request fails to retrieve the data, it logs a warning and retries after a 0.5-second delay.
- Recursing the comment tree:
def recurse_tree(metadata, og_metadata=None) -> any:
if not og_metadata:
og_metadata = metadata
try:
parent_id = metadata["parent"]
parent_metadata = download_metadata(parent_id)
return recurse_tree(parent_metadata[1], og_metadata)
except KeyError:
return (metadata["id"],
{
**og_metadata,
"root_id":metadata["id"]
}
)
def key_on_parent(key__metadata) -> tuple:
key, metadata = recurse_tree(key__metadata[1])
return (str(key), metadata)
- In the stream, we will receive both the top-level stories and then their comments. We want to be able to attribute them properly to the top level, so we need to recurse up the comment tree to get the story data associated with the comment.
- Formatting our Data Correctly
def format(id__metadata):
id, metadata = id__metadata
return json.dumps(metadata)
- In order to output our data to Proton, we need to pass a JSON string of the metadata dictionary so it can be parsed with Proton SQL functions.
Defining the dataflow
With the code for transformations and enrichment defined, we can move on to defining the dataflow. A dataflow is a series of steps that define the flow and transformation of data in a directed graph.
- Creating the Dataflow:
flow = Dataflow("hn_scraper")
- A new
Dataflowinstance is created which acts as a blueprint for the data processing pipeline.
- Setting up Input:
max_id = op.input("in", flow, HNSource(timedelta(seconds=15)))
- The
inputmethod is utilized to set up the data source for the dataflow. In this case, an instance ofHNInputis created with a specified polling interval, and is tagged with the identifier "in".
- Data Redistribution:
id_stream = op.stateful_map("range", max_id, lambda: None, get_id_stream).then(
op.flat_map, "strip_key_flatten", lambda key_ids: key_ids[1]).then(
op.redistribute, "redist")
- Building our stream and redistributing the data. In order to make our dataflow stateful and recoverable, we use a stateful our stateful function
get_id_streamto keep track of the max_id. In that function we return a range of ids and we flat map these in order to send them downstream as a stream. - With a stream of IDs. We use the
redistributemethod to ensure that if the dataflow is run with multiple workers, the downloads in the subsequentmapwill be parallelized, enhancing the efficiency of the data processing. If you remember back to our Hacker News Input connector, we ran with only a single partition to avoid duplicate IDs. Now we need to redistribute these so we can more efficiently make a network call at the next step.
- Mapping to metadata function:
id_stream = op.filter_map("meta_download", id_stream, download_metadata)
- The
filter_mapmethod applies thedownload_metadatafunction to each item in the stream. This stage is where the actual data processing (metadata downloading) occurs and if None is returned, that item is skipped and won’t be sent downstream.
- Splitting stories and comments:
split_stream = op.branch("split_comments", id_stream, lambda item: item[1]["type"] == "story")
story_stream = split_stream.trues
story_stream = op.map("format_stories", story_stream, format)
comment_stream = split_stream.falses
comment_stream = op.map("key_on_parent", comment_stream, key_on_parent)
comment_stream = op.map("format_comments", comment_stream, format)
- We split the stream based on the type and then we can act on the different types (comments and stories) differently as needed.
- The stories are ready to be formatted in the map step to prep the data for output.
- In the comment stream, we can find the story ID, which is the ultimate parent of the comment tree. We want this for our SQL analysis in Proton. Once we have the story ID we can format the comment stream for output as well.
- Setting up Output:
op.inspect("stories", story_stream)
op.inspect("comments", comment_stream)
op.output("stories-out", story_stream, ProtonSink("hn_stories_raw", os.environ.get("PROTON_HOST","127.0.0.1")))
op.output("comments-out", comment_stream, ProtonSink("hn_comments_raw", os.environ.get("PROTON_HOST","127.0.0.1")))
- First, we log our streams to the console/terminal, this is purely for debugging purposes and should be removed for production environments.
- The
outputmethod is utilized to specify the output destination for the processed data. Here, aProtonSinkconnector is utilized to output both streams to Proton. In Bytewax you can have multiple outputs in parallel with branching, you can also have multiple outputs in series if you wanted to write the same data to different locations.
Let’s take a look at what writing a custom sink connector for Proton looks like.
The ProtonSink will connect to a running Proton instance and create the stream if it doesn't exist. This connector uses the raw type, but could be modified to use a schema. The _ProtonSinkPartition is based on the Bytewax class StatelessSinkPartition which is used to define what happens on each worker at startup and for each batch of records in the stream that it receives.
class _ProtonSinkPartition(StatelessSinkPartition):
def __init__(self, stream: str, host: str):
self.client=client.Client(host=host, port=8463)
self.stream=stream
sql=f"CREATE STREAM IF NOT EXISTS `{stream}` (raw string)"
logger.debug(sql)
self.client.execute(sql)
def write_batch(self, items):
logger.debug(f"inserting data {items}")
rows=[]
for item in items:
rows.append([item]) # single column in each row
sql = f"INSERT INTO `{self.stream}` (raw) VALUES"
logger.debug(f"inserting data {sql}")
self.client.execute(sql,rows)
To initialize the _ProtonSinkPartition, we define a ProtonSink class based on the Dynamic Sink. This defines the behavior of Bytewax on startup and how data is split across partitions. Build is called with information about the worker and this can be used to logically divide work and IO.
class ProtonSink(DynamicSink):
def __init__(self, stream: str, host: str):
self.stream = stream
self.host = host if host is not None and host != "" else "127.0.0.1"
"""Write each output item to Proton on that worker.
Items consumed from the dataflow must look like a string. Use a
proceeding map step to do custom formatting.
Workers are the unit of parallelism.
Can support at-least-once processing. Messages from the resume
epoch will be duplicated right after resume.
"""
def build(self, worker_index, worker_count):
"""See ABC docstring."""
return _ProtonSinkPartition(self.stream, self.host)
With our dataflow written, move on to using proton to analyze the data.
Real-time Hacker News Analysis
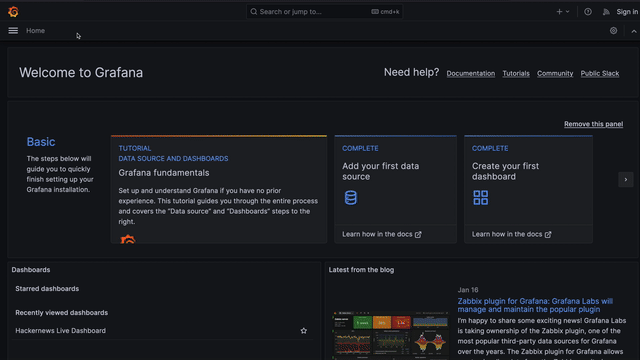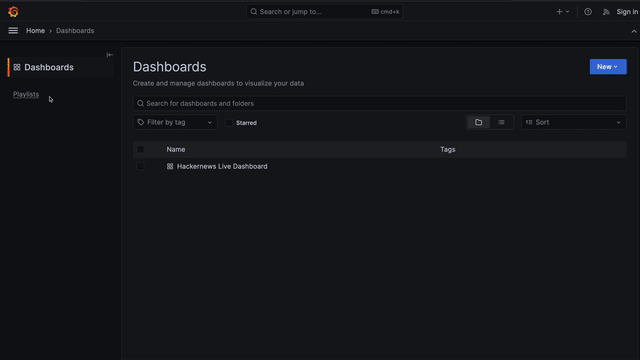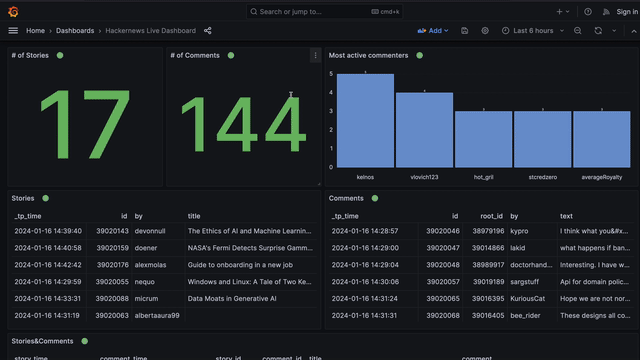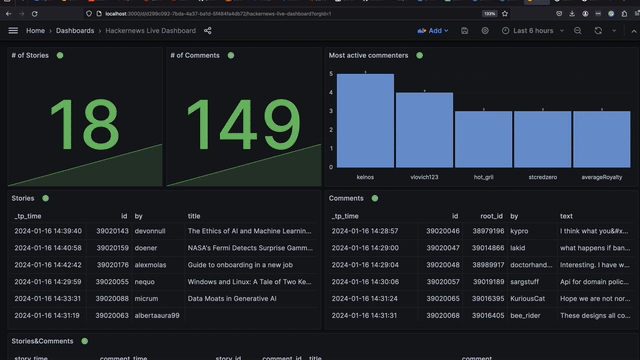
Proton comes with some awesome integrations out of the box! One of those is Grafana. We will outline how you can write some queries to take the raw json strings and create some Grafana visualizations like the dashboard below.
As shown in our Proton sink we are writing a batch of JSON strings as values. In our dataflow we have two streams and we will end up with two table streams in Proton. In order to use the values downstream, we need to create tables to receive the streaming data. We can do this by executing the following statements in Proton.
CREATE STREAM hn_stories_raw(raw string);
CREATE STREAM hn_comments_raw(raw string);
Once we start to convert those raw strings into columns in materialized views with the following queries executed on Proton. These will be executed as part of the docker compose start if you are using it that way.
CREATE MATERIALIZED VIEW hn_stories AS
SELECT
to_time(raw:time) AS _tp_time,
raw:id::int AS id,
raw:title AS title,
raw:by AS by,
raw
FROM hn_stories_raw;
CREATE MATERIALIZED VIEW hn_comments AS
SELECT
to_time(raw:time) AS _tp_time,
raw:id::int AS id,
raw:root_id::int AS root_id,
raw:by AS by,
raw
FROM hn_comments_raw;
In the SQL queries above, the raw command is used to parse the JSON fields.
Once we have the views we can query the tables individually:
SELECT * FROM hn_stories WHERE _tp_time>earliest_ts();
We can also make a view of the query above for both the stories and the comments. You can execute these directly in Proton and again this is done for you if using docker compose.
CREATE VIEW IF NOT EXISTS story AS SELECT * FROM hn_stories WHERE _tp_time>earliest_ts();
CREATE VIEW IF NOT EXISTS comment AS SELECT * FROM hn_comments WHERE _tp_time>earliest_ts()
With our views in hand, we can make a streaming query. You could do this in the Grafana explore query editor:
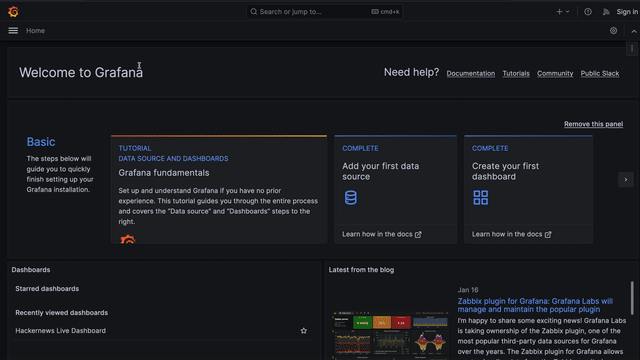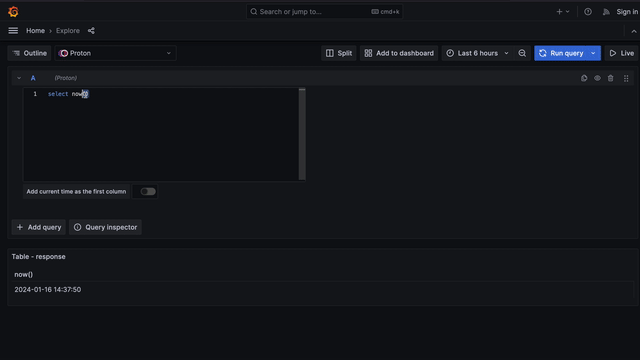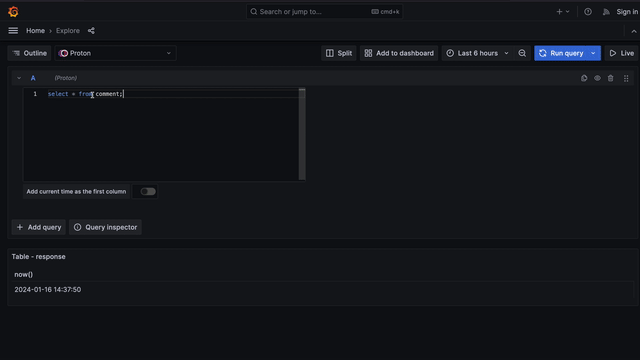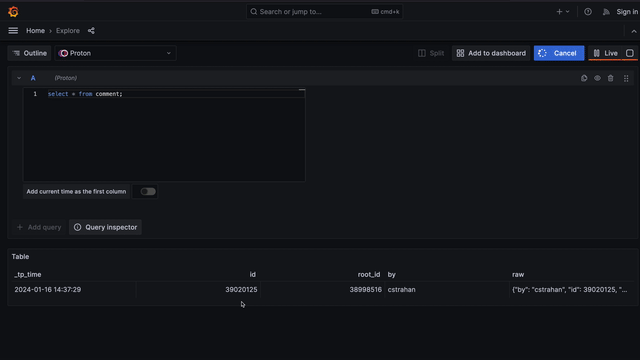
select * from comment;
select
story._tp_time as story_time,comment._tp_time as comment_time,
story.id as story_id, comment.id as comment_id,
substring(story.title,1,20) as title,substring(comment.raw:text,1,20) as comment
from story join comment on story.id=comment.root_id;
The docker compose file creates a dashboard for you that you can view in the grafana dashboard locally. You can modify this and make your own.
Have you made something interesting with this? We would love to see it! Share it on Reddit, Hacker News or your favorite social media platform and let us know 🐝.
If you think Bytewax and Proton are cool, show your support on GitHub with a star.
⭐ Bytewax
⭐ Proton
A Closer Look at Arroyo and Bytewax

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

