

I couldn’t be more excited to announce the Bytewax platform - the next phase in our plan to simplify stream processing. In this post we are going to start with how we got here today (the Python Bytewax library) before we share details of what the future holds (the Platform and beyond).

We created Bytewax because leveraging streaming data is incredibly difficult. Despite the potential impact of streaming data processing, developers resort to suboptimal batch processing methods. Existing solutions, require expertise in distributed systems and specialized knowledge of complex & hard to maintain infrastructure. These systems predate things like kubernetes, containerization and cloud storage and as a result, they rely on schedulers and task managers that have proven to be redundant. In addition, the current trends in language adoption for data workloads often make for a difficult multiple-language situation. We could have solved these problems by providing a hosted solution, or adding an additional SDK abstracting the complexities, but we fundamentally didn’t agree that these are the right answers as it felt like the wrong abstraction for a cohesive developer experience.
Today there are hundreds of developers using Bytewax
And we get feedback like:
“It's dead simple to work with.”,
“Super easy, lean framework to use.”,
“By using Bytewax, we have the freedom to perform almost anything we want using Python in a streaming context. While Spark and Flink were considered, they presented steeper learning curves. Bytewax allowed us to get started within minutes using code we had previously written for micro-batching with basic Kafka-Python consumers/producers.”,
“I wrote quite a few connectors, for aribyte, for meltano, for kafka connect, for datapm, I have to say bytewax is the easiest one.”
We are amazed by the quality of the community growing around the project and the overwhelmingly positive feedback.
This has opened up the question: Where does Bytewax go next?
Collectively, our team has spent many decades building internal tooling and platforms around open source software at organizations like GitHub, Yelp, Simple, and Heroku. There is a lot of toil and distraction associated with these efforts that can take away from shipping the work that will ultimately impact the business. Although it can be fun to build internal platforms at first, as time goes on, it really detracts from what we ultimately enjoy, building and shipping features.
Step 1 of our vision for Bytewax was to invent a new library that enabled a single engineer to create a stream processing job in bytewax in a single afternoon.
Step 2 is to build a platform that eliminated the overhead of multiple teams running multiple workloads across the organization.
Drawing on our past experience building data platforms, we wanted a solution that you would feel good about paying for or recommending internally. We've built and will continue to build the bytewax platform around a simple yet crucial goal: to eliminate the overhead of deploying and scaling bytewax stream processing jobs and to facilitate embedding Bytewax within your internal or external facing platforms.
The Bytewax platform is based on 5 core pillars:
- Eliminate deployment headaches: The platform includes CI/CD integration & deployment tooling (waxctl)
- No more pager duty nightmare: Built-in monitoring, an intuitive UI, and tracing & debugging tooling
- Use your existing stack: Built-on K8s and leverages common open source projects
- No scalability and reliability frustrations: Disaster recovery, and rescaling out-of-the-box
- Keep it customizable and extensible: Comprehensive platform API, and UI customization
Sneak peek of the platform 👇👀
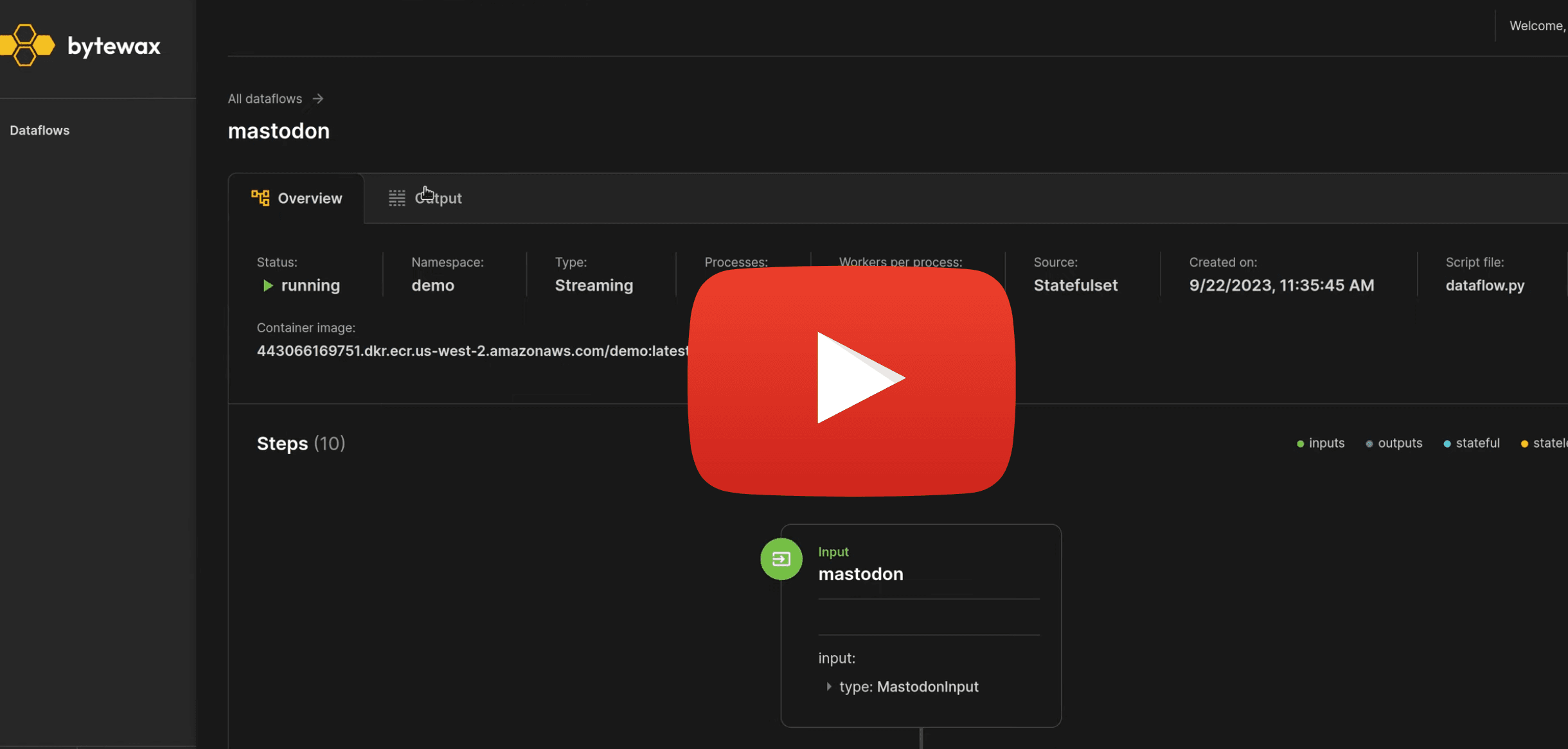
Thank you for being a part of our community! If you’re using Bytewax and are interested in the platform, sign up here.
♥️ The Bytewax Team 🐍
🤓 Data Explained: The State of Streaming

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

