

Real-time feature pipelines are a critical part of real-time machine learning where we extract information (features) from data to get better inferences from our machine learning model. Real-time feature pipelines aren’t possible without stream processing because of the need to do things like aggregating events, windowed calculations, and joining multiple streams together.
I recently presented at the Feature Store Summit on how you can get started building real-time feature pipelines with Bytewax. The recording is available here. Let’s summarize what the presentation covered below!
Can I build impactful real-time ML-powered experiences?
Yes, and you can do it in Python! 🐍
No need for Apache Flink, Spark, or other complicated streaming data processing tools, Bytewax can be used to build real-time feature pipelines to power machine learning.
Why should I care about real-time ML?
- The advent of real-time ML has opened new horizons for businesses to leverage streaming data for immediate insights, thereby elevating customer satisfaction, operational efficiency, and ultimately, revenue margins.
- The significance of latency or timeliness in data processing cannot be overstated, and its impact on a company's revenue is substantial, regardless of the scale of operations.
The Genesis of Bytewax
- Before founding Bytewax, I worked across many different areas of Data from Data Science and ML Infrastructure at GitHub and Heroku. These experiences were the basis behind what bytewax has now become, pinned to a vision to simplify the complex landscape of real-time ML.
- Bytewax, an open-source Python stream processor, was conceived to provide a seamless conduit for handling streaming data, a cornerstone for enabling real-time ML specifically in feature extraction.
Navigating Stream Processing with Bytewax
- Streaming data, analogous to an infinite Python generator, necessitates proficient processing tools to manage, batch, and keep a tab on the data. Stream processors like Bytewax are designed to provide the requisite semantics for such endeavors. You can try running the code below to get comfortable with how generators work in Python and the idea of how a stream processor is constantly requesting more data.
def my_stream():
num = 0
while True:
yield num
num += 1
stream = my_stream()
print(stream)
print(next(stream))
print(next(stream))
Example: Crafting a Real-Time Feature Pipeline
If you want to show your support for what Bytewax is building, give the repo a ⭐.
In the presentation, I tried to highlight the importance of splitting data capture and feature extraction into two separate parts with a durable storage layer in between and how Kafka or Redpanda are great tools for this because you can take advantage of the replayability and publish-subscribe pattern. This will enable resiliency in your system for recovery and so you can have multiple feature pipelines consuming from the same data.
The presentation covers in more depth how to build feature pipelines with Bytewax, Redpanda and Hopsworks following an architecture like the diagram below.
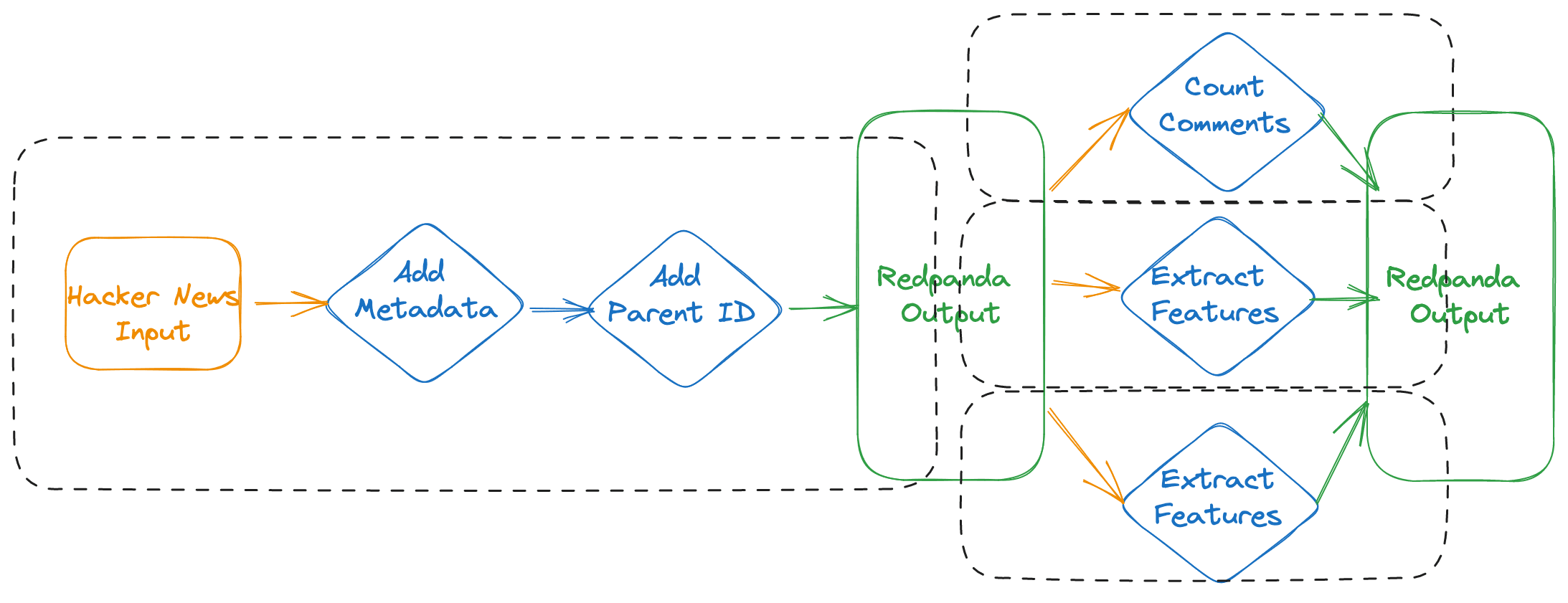
Let's take a peek at the code used to make the ingestion pipeline from the Hacker News API.
# imports excluded for brevity
class HNInput(SimplePollingInput):
def __init__(self, interval: timedelta, align_to: Optional[datetime] = None, init_item: Optional[int] = None):
super().__init__(interval, align_to)
logger.info(f"received starting id: {init_item}")
self.max_id = init_item
def next_item(self) -> list:
'''
Get all the items from hacker news API between
the last max id and the current max id
'''
if not self.max_id:
self.max_id = requests.get("https://hacker-news.firebaseio.com/v0/maxitem.json").json()
new_max_id = requests.get("https://hacker-news.firebaseio.com/v0/maxitem.json").json()
logger.info(f"current id: {self.max_id}, new id: {new_max_id}")
ids = [int(i) for i in range(self.max_id, new_max_id)]
self.max_id = new_max_id
return ids
def download_metadata(hn_id: int) -> dict:
# Given an hacker news id returned from the api, fetch metadata
req = requests.get(
f"https://hacker-news.firebaseio.com/v0/item/{hn_id}.json"
)
if not req.json():
logger.warning(f"error getting payload from item {hn_id} trying again")
time.sleep(0.5)
return download_metadata(hn_id)
return req.json()
def recurse_tree(metadata: dict, og_metadata=None) -> tuple:
if not og_metadata:
og_metadata = metadata
try:
parent_id = metadata["parent"]
parent_metadata = download_metadata(parent_id)
return recurse_tree(parent_metadata, og_metadata)
except KeyError:
return (metadata["id"],{**og_metadata,"root_metadata":metadata})
def key_on_parent(metadata: dict) -> tuple:
key, metadata = recurse_tree(metadata)
return (str(key), metadata)
def serialize_with_key(key_payload: tuple) -> tuple:
key, payload = key_payload
return json.dumps(key).encode("utf-8"), json.dumps(payload).encode("utf-8")
def run_hn_flow(init_item=None):
flow = Dataflow()
flow.input("in", HNInput(timedelta(seconds=15), None, init_item)) # skip the align_to argument
flow.flat_map(lambda x: x)
# If you run this dataflow with multiple workers, downloads in
# the next `map` will be parallelized thanks to .redistribute()
flow.redistribute()
flow.map(download_metadata)
flow.inspect(logger.info)
# We want to keep related data together so let's build a
# traversal function to get the ultimate parent
flow.map(key_on_parent)
flow.map(serialize_with_key)
flow.output("rp-out", RedpandaOutput(["localhost:19092"], "hacker-news-raw"))
return flow
The example elucidates the following aspects:
- real-time polling and processing of Hacker News data,
- connecting to different data sinks, and
- building a horizontally scalable pipeline that can run across multiple workers with no changes to the code needed.
All that is done through the magic of Bytewax!:
- Bytewax is a Python-centric framework, so it's super-easy to extend it and create custom inputs
- The lower-level abstraction caters to the necessary flexibility of your unique needs
- Thanks to the extensive Python community, you can plug in any data source via Python clients
- Your data is transformed, analyzed, and polled in real-time with an easy-to-scale model.
Building Feature Pipelines from Redpanda
- The versatility of Bytewax facilitates the decoupling of data ingestion from computation tasks, thus nurturing a more robust and scalable real-time ML infrastructure.
- Downstream of Bytewax and Redpanda, in a complete ML platform, you would add a feature store like Hopsworks or Feast to register your features and make them available for low-latency retrieval.
What Next
This was an intro into how you can build streaming pipelines to support real-time machine learning. For a more in depth example of how you can specifically do this with Bytewax, Kafka and Hopsworks, check out the tutorial available from Hopsworks in their GitHub repo
—
We hope you enjoyed this post about real-time feature pipelines with Bytewax. This post was based off of a presentation at Feature Store Summit 2023. If you want to follow the development of Bytewax, star ⭐ the repo and reach out to us in Slack if you are building something cool with Bytewax!
Start with Open Source, Scale with the Platform

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

