New recovery system, enhanced rescaling and other updates in Bytewax v0.17.0
By Oli Makhasoeva

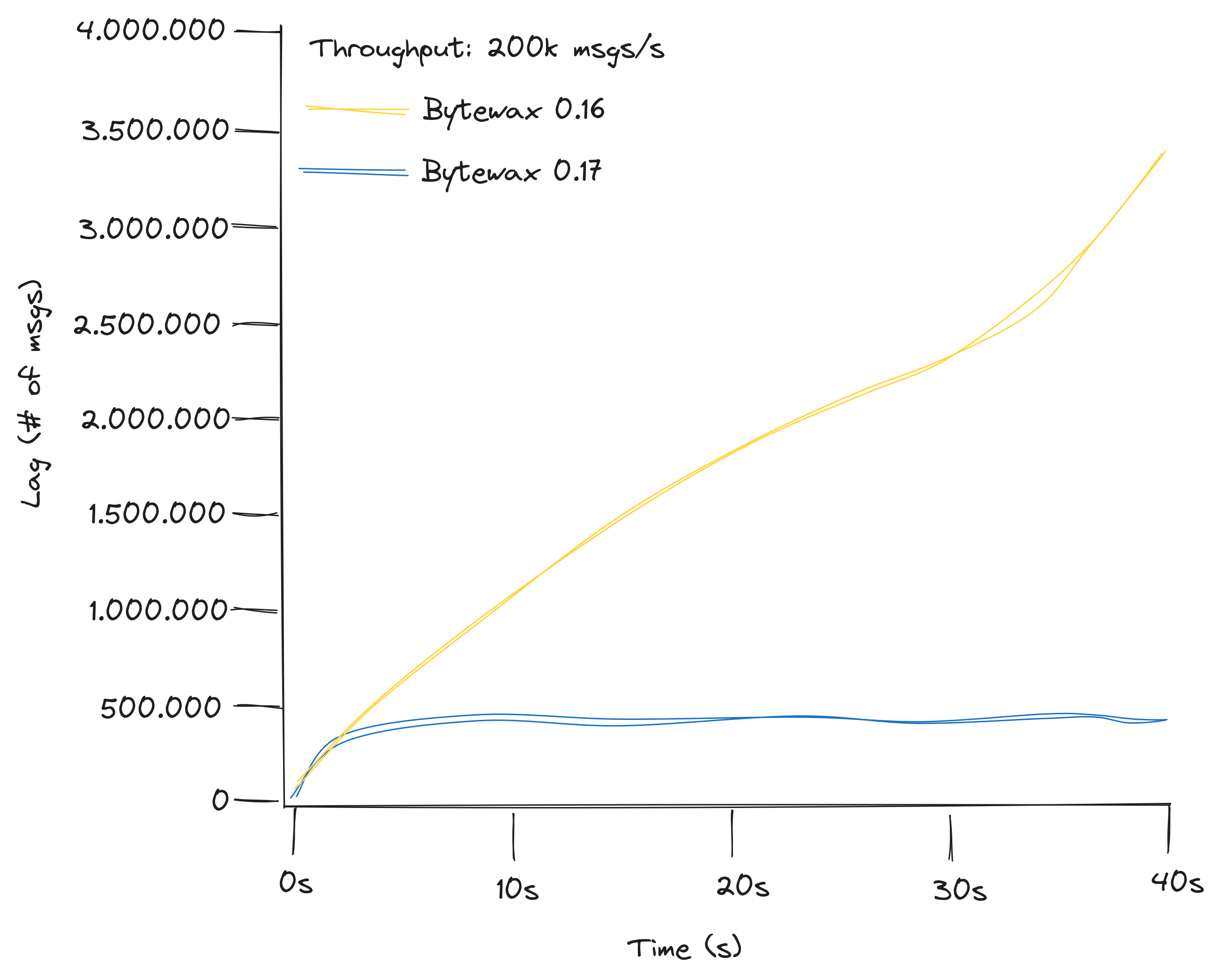
We are excited to announce the release of Bytewax v0.17, which brings performance boosts and major changes to the recovery system and rescaling mechanism. With this update, you can stop the dataflow execution, adjust the number of workers, and safely resume. To help you navigate the new features and breaking changes, we have prepared a migration guide (with code examples!) that covers the updates made to our API for upgrading to v0.17. Please find it here. Jump on and see the release on our GitHub!
What's Changed
Features:
- SQLite recovery to support rescaling: Recovery has been updated to support rescaling the number of workers in a dataflow. In v0.17, the number of workers in a cluster can now be changed by stopping the dataflow execution and specifying a different number of workers on resume. Creating recovery stores has been moved to a separate step from running your dataflow. For more information, see the Bytewax migration guide.
AsyncBatcher: We've included a newbytewax.inputs.batcher_asyncto help you use async Python libraries in Bytewax input sources. This lets you play nicely with Bytewax's cooperative multitasking but still use async APIs. To see an example of it's use, check out our wikistream example.next_awake: Adds a new method in input sources:next_awake. Input sources now have an optionalnext_awakemethod which you can use to schedule when thenext_batchcall should occur. You can use this to "sleep" the input operator for a fixed amount of time while you are waiting for more input. The default behavior uses a simple heuristic to prevent a spin loop when there is no input. Always usenext_awakerather than using atime.sleepin an input source. See periodic_input.py in the examples directory for an implementation that uses this functionality.- Support for additional platforms: Bytewax is now available for linux/aarch64 and linux/armv7! 🎉
Code Improvements:
- Restructures input and output to support batching: Changes the API of input sources from
nexttonext_batchwhich should return a list of elements rather than a single item. Changing input sources to operate over a batch has which has improved the throughput of Dataflows. Our built-in input classes have been updated to accept abatch_sizeparameter, which configures the maximum number of messages to request from an input source at a time. - Builds exception messages only on error: Adds {re,}raise_with (to parallel {re,}raise) and has it take a closure that produces the error message. This causes the error handling code to only attempt to format the exception message string when an error has occurred.
- Run clippy on pre-commit: Runs the Clippy linting tool on pre-commit on all the files. Additional pre-commit improvements can be found here.
Bug Fixes:
- [Corrects the docs](https://github.com/bytewax/bytewax/pull/ 255): External contribution! Rob de Wit made a change in our docs 💛 Every Contribution Counts! In the world of OSS, there's no such thing as a "small" contribution. Each PR, no matter how minor, is a step towards improving the project. Thank you, Rob!
- Fixes a typo: Another external contribution! Thanks, Ryan Abernathey!💛
- Fix kafka input error message: Bugfix for the issue #285: AttributeError: error getting next input item from partition source.
Summing up, Bytewax v0.17 brings important modifications to the recovery process to accommodate rescaling and many other improvements.
Given the nontrivial nature of the changes, we will post more detailed tech dives about our recovery system and performance. Please stay tuned!
Excited about Bytewax? Consider joining our Slack and giving our GitHub repository a star. As a community-driven open-source endeavor, we deeply value your participation in shaping our future 💛
top-kat and Streaming Algorithms in Bytewax

Oli Dinov
Director of Developer Relations and OperationsOli is a passionate technologist with a background in engineering, consulting, and community building. On a break from creating content, she loves to network online & in person at meetups, conferences, and forums.
M12 invests in the Future of Stream Processing with Bytewax
Other posts you may find interesting
View all articles
top-kat and Streaming Algorithms in Bytewax
A tech dive from our intern, Isaac Milstein
Written by Oli Makhasoeva & Isaac Milstein