

We're excited to share with our readers a comprehensive and insightful piece by Matt Palmer originally published on newsletter.casewhen.xyz.
Before we jump into the blog, please do us a favor - take this survey. As the landscape of streaming data and the needs of our current and future users evolve and scale, so should the features and integrations that Bytewax supports. We’d like to understand what technologies are important to you as we improve our product. 💛
Disclaimer: This was assembled through a hodgepodge of personal research, conferences, and chatting with industry professionals. This was my best attempt at understanding wtf is going on with streaming, which must be pretty difficult even for streaming aficionados, given how hard it was. A special thank you goes out to Zander Matheson of Bytewax for his help!
Background
The landscape of streaming data has seen a rapid evolution in the past decade, driven by increasing data volumes and the necessity for real-time processing (IoT, sensor data, real-time consumer applications). This has given rise to complex platforms and tools that, while powerful, often carry a steep learning curve.
Streaming was once thought of as a low-latency and inaccurate solution, characterized by the popularity of the Lambda Architecture, a system where batch and streaming solutions run in parallel with the batch output "correcting" the streaming output.
Today, well-designed streaming systems commonly provide the same quality of output as their batch counterparts in no small part thanks to the robust development and community around stream platform & processing. Before we jump in, a quick note on what streaming data is.
Bounded and Unbounded Data
There are two types of data that typically lend themselves to the terms "batch" and "streaming," while we commonly use those terms to describe the underlying data, they actually refer to the processing of data.
Any data can be processed as a batch or stream, but we are commonly referring to the characteristics of data that we would like to stream. More appropriate terms are bounded and unbounded data.
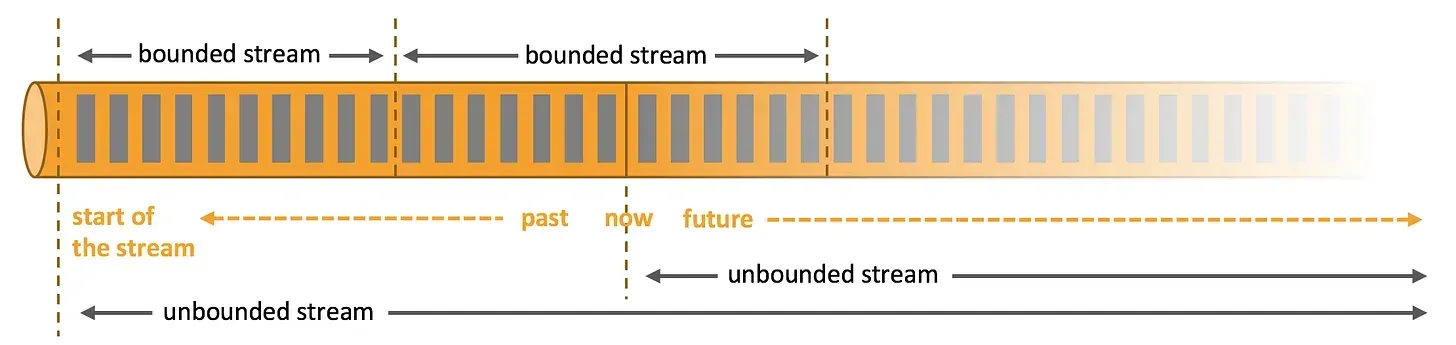 Source: Apache Flink
Source: Apache Flink
Bounded data.
Bounded data describes a finite pool of resources that is transformed from one state to another. We extract, load, and transform it in our desired system. Easy, manageable, finite.
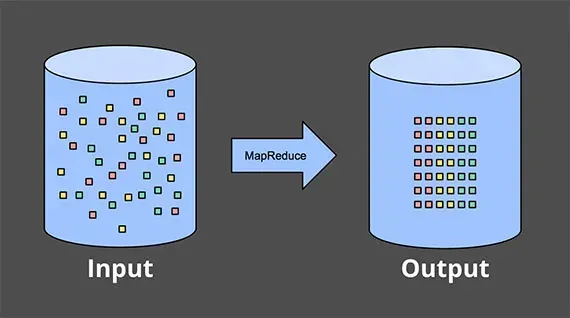 Bounded data is nice and tidy (sometimes). Source: Streaming 101
Bounded data is nice and tidy (sometimes). Source: Streaming 101
Unbounded data
Unbounded data represents most datasets. While unnerving, the data never really ends, does it? Transactions and sensor data will continue to flow (so long as the lights remain on). Today, unbounded data is the norm. There are a number of ways to process unbounded data:
- Windowing: Segmenting a data source into finite chunks based on temporal boundaries.
- Fixed windows: Data is essentially “micro-batched” and read in small fixed windows to a target.
- Sliding windows: Similar to fixed windows, but with overlapping boundaries.
- Sessions: Dynamic windows in which sequences of events are separated by gaps of inactivity— in sessions, the “window” is defined by the data itself.
- Time-agnostic: Suitable for data where time isn't crucial, often utilizing batch workloads.
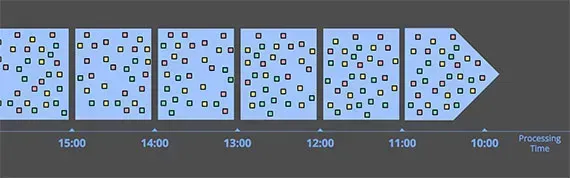 Unbounded data can seem overwhelming, but is often managed through windowing. Source: Streaming 101
Unbounded data can seem overwhelming, but is often managed through windowing. Source: Streaming 101
It's crucial to differentiate between the actual event time and the processing time, since discrepancies often arise.
This demonstrates an important point:
- Most solutions described above are actually batch solutions! We should think about most problems as batch problems, as complexity grows geometrically as we require "real-time" solutions, for now at least.
- Even streaming unbounded data technically involves processing finite chunks through windowing.
With that in mind, we can continue onto streaming platforms.
Streaming Platform
When we say "platforms," we refer to "transportation layers" or systems for communicating and transporting streaming data.
- Kafka: Originated at LinkedIn in 2011, Apache Kafka started as a message queue system but quickly evolved into a distributed streaming platform. While Kafka's design allows for high throughput and scalability, its inherent complexity remains a hurdle for many.
- Redpanda: Developed as an alternative to Kafka, Redpanda boasts similar performance but with simplified configuration and setup. Redpanda is based on C++ rather than Java and compatible with Kafka APIs. The company recently raised a $100M Series C, if venture capital is any indication of value (meh 🙄).
- Pulsar: Initiated by Yahoo and now under the Apache Software Foundation, Pulsar is a multi-tenant, high-performance solution for server-to-server messaging.
- Gazette: Often used in scenarios where high performance and durability are required, Gazette provides an append-only log system that is ideal for event sourcing, data storage, and analytics.
Stream Processing
Stream processing is about analyzing and acting on real-time data (streams). Given Kafka's longevity, the two most popular and well known stream processing tools are:
- Flink: an open-source, distributed engine for processing unbounded and bounded data sets. Stream processing applications are designed to run continuously, with minimal downtime, and process data as it is ingested. Apache Flink is designed for low latency processing, performing computations in-memory, for high availability, removing single point of failures, and to scale horizontally.
- Spark Structured Streaming: Spark Structured Streaming is a component of the Apache Spark ecosystem, designed to handle real-time data processing. It brings the familiarity and power of Spark's DataFrame and DataSet APIs to the realm of streaming data. While technically a micro-batch service, Sparks low latencies make it streaming in our eyes.
- Kafka Streams: A library that provides stateful processing capabilities, but its tie to Java and Scala can be limiting.
Simplifying Stream Processing
Several newcomers are attempting to simplify stream processing by offering Python-native, open-source streaming clients, with a focus on performance and simple development cycles.
- Confluent-Kafka: An attempt to bring Kafka capabilities to Python, although it remains rudimentary compared to its Java counterpart. Confluent-Kafka is simply a client-library in the same way psycopg2 is a Postgres client library.
- Bytewax: Aims to bridge the gap by offering a more intuitive, Pythonic way of dealing with stream processing, making it more accessible to a wider range of developers. Built on Rust, Bytewax is highly performant, simpler than Flink, and boasts shorter feedback-loops and easy deployment/scalability.
- Spark Streaming: I would argue that Spark Streaming also reduces the complexity of streaming. Though technically “micro-batch” in nature, the ability to stream in SparkSQL & PySpark with UDFs is much simpler than alternatives.
- Platforms: platforms, like Databricks or Snowflake, can provide useful abstractions to complicated streaming logic. Delta Live Tables a nice example of an embedded technology that can make streaming seem almost simple.
Unification of Stream Models
Several streaming services seek to unify stream models, buy providing an API or platform for creating a model compatible across these technologies:
- Apache Beam: Developed by Google, Apache Beam provides a unified API for batch and stream processing. Beam is a programming model, API, and portability layer not a full stack with an execution engine. Beam's goal is to abstract away the complexities of underlying systems like Apache Flink, Apache Spark, or Google Cloud Dataflow.
- Estuary Flow: While Beam focuses on "per-key-and-window" models, Flow presents a more holistic approach with its per-key register concept, allowing more complex real-world modeling.
Streaming DBs
Also seeking to simplify the complexity of streaming data stacks, streaming databases attempt to combine stream processing and storage.
They're built to handle real-time data and offer continuous insights without the need to transfer data to another processing system. Streaming databases are particularly attractive for:
- Streaming ETL: ingesting and processing data from online transaction processing databases and message queues to data warehouses and lakes.
- Streaming Analytics: real-time monitoring, alerting, automation, and analytics capabilities. This data can be directly queried through a SQL API, making it compatible with all existing business intelligence solutions.
Streaming databases are particularly attractive for reducing dependencies and improving ease-of-use. RisingWave & Materialize are examples of modern streaming databases.
Wrap
The streaming landscape, while complex, has seen strides in simplification and user-friendliness. As the demand for real-time data processing continues to grow, we can anticipate even more tools and platforms that cater to a broader range of users and use-cases.
I’m pretty excited to see what the future of streaming looks like— I anticipate systems that abstract away the complexity of streaming data will continue to proliferate to the point where, one day, all data will be streamed.
Data Pipelines: Streams to Parquet

Matt Palmer
Data Engineer & WriterMatt is a data engineer and writer. He is the author of Understanding ETL, O'Reilly Media. Subscribe to his newsletter with a focus on quality content in the data + AI space https://newsletter.casewhen.xyz/

