

Bytewax is an open source Python framework that leverages Timely Dataflow as the execution/runtime for enabling vast scalability for data processing. You can use it to build fast and scalable data processing applications all with the ease-of-use of Python. The Bytewax framework makes it straightforward to apply a series of real-time data transformations for user session analytics, fraud detection, inline transformations, and more.
A few Bytewax use cases include analyzing a stream of tweets in real time, maintaining updates from SSE events, and analyzing the stock market in real time. In this tutorial, we will use Bytewax to perform real-time analysis using natural language processing techniques on a data stream from Twitter's API.
Real-Time Data Processing and Analysis
Real-time data processing and analysis involves processing and getting insights from raw data as it is received. The processed data contains trends that communicate meaningful patterns in the data. With real-time analytics, you can query the processed data and make informed decisions immediately after it's received.
Many companies make use of real-time data analysis to get an immediate understanding of their data before making some actions. Take, for instance, a news station using Twitter as their users' interaction point. They give a specific hashtag for users to interact with the news anchor. On the backend, an algorithm can group correlated questions in real time. This can be useful to ensure the news anchor addresses questions that are more prevalent in the viewership. However, manually combing through hundreds of tweets at a time would be slow and impractical.
Another example is analyzing stock market or exchange data in real-time to inform buying or selling decisions. For example, in performing a correlation analysis between the Apple and the Samsung stocks, the algorithm can stake accordingly based on the results.
These are just a few real-time use cases leveraging Bytewax.
Natural Language Processing and Sentiment Analysis on Twitter Data with Bytewax
A software, data, or ML engineer can use Bytewax to process data from Twitter's API, for example, when performing sentiment analysis on tweets.
Sentiment analysis determines whether a tweet is positive, negative, or neutral. Sentiment analysis is heavily used in automated trading when major news is released. For example, news about Elon Musk's offer to buy Twitter pumped up Twitter's share price. Trading bots can use the sentiment analysis of the tweets after the announcements and use that as a cue for buying Twitter stock. In this tutorial, we will first use a Python library called TextBlob to extract the sentiment of a tweet and then we are going to output the most commonly used words in the tweets over a window of time for each sentiment (Positive, Neutral and Negative). This additional step can help understand more about why the sentiment is the way it is and some of the concepts, actors, places, things contributing to the sentiment.
To run this tutorial, you'll need the following:
- Python and pip installed on your computer
- A Twitter developer account
- An IDE
- To clone the official GitHub repository
Twitter Setup
To obtain your Twitter API key, follow the steps below:
Log in to the Twitter developer account.
Create a new project and give it a name, use case, and description.
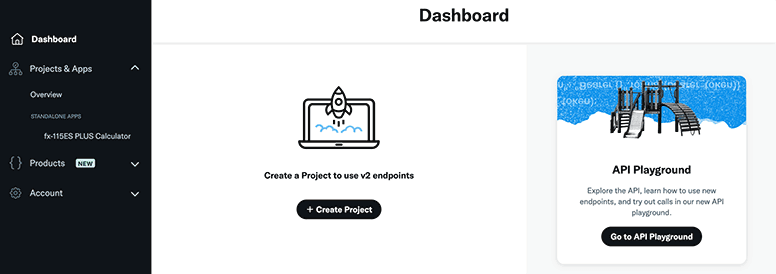
Create a new app.
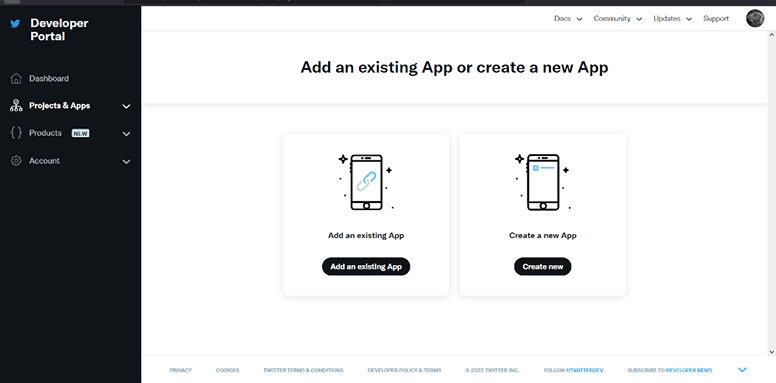
Select Development as your app environment.
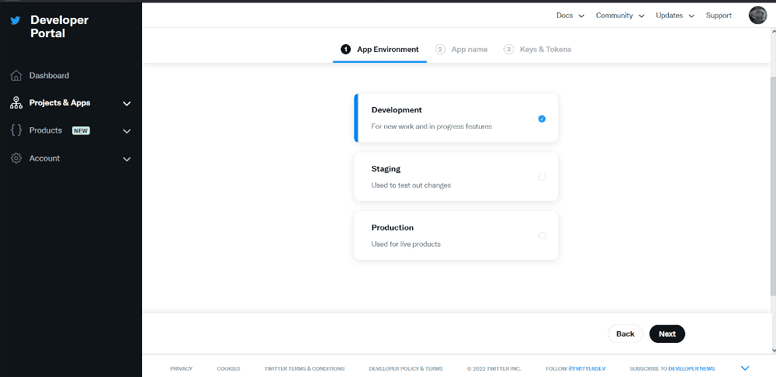
Give your app a unique name.
You'll obtain your API key, secret key, and bearer token. Copy them to a secure place.
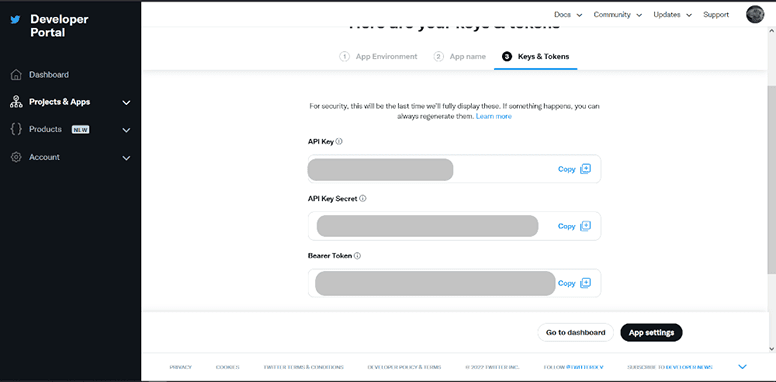
Project Setup
Your folder structure will look like this:
TWITTER-BYTEWAX
└───twitter.py
└───dataflow.py
└───requirements.txt
└───search_terms.txt
To set your Bearer Token as an env variable for use, in your terminal, export the variable.
export TWITTER_BEARER_TOKEN=<YOUR TWITTER TOKEN>
The requirements.txt file has the following dependencies:
bytewax==0.11.2
textblob==0.17.1
requests==2.28.1
spacy==3.4.1
- bytewax: our dataflow library
- texblob: used for sentiment analysis
- requests: make API calls to Twitter
- spacy: natural language processing library
To install the project dependencies, run the following command in your current directory:
pip install -r requirements.txt
Using the following command, you also need to download and install the TextBlob corpora containing all the necessary words in the sentiment analysis and the spacy stop words:
python3 -m textblob.download_corpora
python -m spacy download en_core_web_sm
Analyzing Twitter Data with Bytewax
Now that we have the project set up, let’s analyze some tweets! The diagram below illustrates the steps used to analyze Twitter data up to the sentiment analysis step with Bytewax.
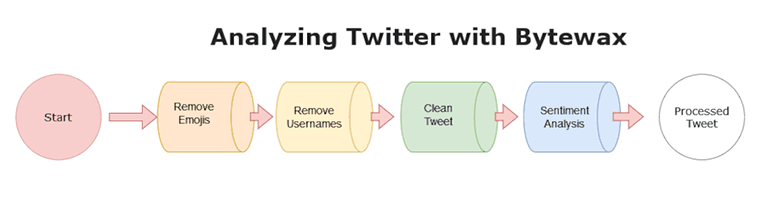
To start, we connect to a stream of tweets using the Twitter API and then we will use Bytewax to transform the tweets in real time by doing the following:
- Removing emojis
- Removing usernames from the tweet
- Cleaning the tweet by removing spaces, special characters, and links
- Performing a sentiment analysis on the tweet
For the purposes of this tutorial, we will focus on the details of our dataflow and omit some of the detail on how to set, delete and update the filter rules, but you can find the full code in the GitHub Repository. It should be noted that the environment variable we are using will be loaded in the this file and is described later in this tutorial.
Now, to start, in our dataflow.py file, we can get the imports out of the way :
import re
from datetime import timedelta
from collections import defaultdict
from bytewax.dataflow import Dataflow
from bytewax.inputs import ManualInputConfig
from bytewax.outputs import StdOutputConfig, ManualOutputConfig
from bytewax.execution import run_main
from bytewax.window import TumblingWindowConfig, SystemClockConfig
from textblob import TextBlob
import spacy
from twitter import get_rules, delete_all_rules, get_stream, set_stream_rules
Next we will write a series of functions that will follow the steps outlined in the previous diagram from removing emojis to determining sentiment.
We can use regex to strip out emojis and other artifacts (this is a simplification and you might want to augment the sentiment analysis to use these).
def remove_emoji(tweet):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', tweet)
Next, we use regex again to eliminate all the usernames in a tweet (usernames are identified by their tag (@) sign) since these won’t be included in the model doing the sentiment analysis:
def remove_username(tweet):
return re.sub('@[\w]+', '', tweet)
Now we will remove the tweet's spaces, links, and special characters, in order to get clean data to TextBlob for sentiment analysis:
def clean_tweet(tweet):
return ' '.join(re.sub("(@[A-Za-z0-9]+)|([^0-9A-Za-z \t])|(\w+:\/\/\S+)", " ", tweet).split())
Lastly, we will perform a sentiment analysis on the tweets using the TextBlob library. The polarity of a tweet determines its sentiment—greater than zero for positive, less than zero for negative, and zero for neutral. These polarities are defined using the following code:
def get_tweet_sentiment(tweet):
# create TextBlob object
get_analysis = TextBlob(tweet)
# get sentiment
if get_analysis.sentiment.polarity > 0:
return 'positive', tweet
elif get_analysis.sentiment.polarity == 0:
return 'neutral', tweet
else:
return 'negative', tweet
With that, you are ready to integrate Bytewax with a stream of tweets.
Connecting to the Twitter API
The Twitter version 2 API requires us to use a bearer token retrieved from the Twitter developer dashboard. The requests made to the Twitter API will require an authorization header containing the bearer token and a user agent of type v2FilteredStreamPython.
The header requirement has been defined as its own function in twitter.py and can be used when calling the Twitter API. This function will take in a request object, add the required two headers, and then return the modified request.
Setting Filtering Rules
Before we can receive data from the Twitter API we will need to set some filtering rules. Which we have defined in search_terms.txt. To set the rules as shown below, we first delete the existing rules and then set ours as seen below. For more details on the code for interacting with this part of the Twitter API, see the repositories code.
rules = get_rules()
delete = delete_all_rules(rules)
# get search terms
with open("search_terms.txt", "+r") as f:
search_terms = f.read().splitlines()
## set stream rules
set_stream_rules(search_terms)
Now that you have a set of rules for the stream, We are ready to define the input and the sequence of the dataflow steps. To specify how we receive input, we first define a dataflow object and then we can use Bytewax operators to specify the input and the sequence in which we will transform the data.
Our dataflow.input operator will call the twitter API via our input_builder function which is defined in.
flow = Dataflow()
flow.input("input", ManualInputConfig(input_builder))
And the corresponding input_builder function:
def input_builder(worker_index, worker_count, resume_state):
return get_stream()
The get_stream function is imported from our twitter.py along with functions to set rules and delete rules. These functions will look after authenticating, connecting to the API and returning the correct data.
# twitter.py
def get_stream():
response = requests.get(
"https://api.twitter.com/2/tweets/search/stream", auth=add_bearer_oauth, stream=True,
)
print(response.status_code)
if response.status_code != 200:
raise Exception(
"Cannot get stream (HTTP {}): {}".format(
response.status_code, response.text
)
)
tweetnbr=0
for response_line in response.iter_lines():
if response_line:
json_response = json.loads(response_line)
json_response = json.dumps(json_response, indent=4, sort_keys=True)
print("-" * 200)
json_response = json.loads(json_response)
tweet = json_response["data"]["text"]
tweetnbr+=1
yield tweetnbr, str(tweet)
Putting it all together, we can define the sequence of our Dataflow up to the sentiment analysis step.
flow = Dataflow()
flow.input("input", ManualInputConfig(input_builder))
flow.map(remove_emoji)
flow.map(remove_username)
flow.map(clean_tweet)
flow.map(get_tweet_sentiment)
flow.inspect(print)
The code snippet above initializes the data flow object from Bytewax then adds your four functions that transform the tweet in the flow.map(). After every transformation, the map operator will emit a downstream copy of the tweet in the four instances.
Understanding the Sentiment
We wanted to go one step further with our dataflow to get an understanding of why the sentiment was labeled as positive, negative or neutral. To do this in a simplified way we will take a look at the most commonly occurring words for the different sentiment tags. To do this, we are going to introduce the concept of a window operator. A window operator will allow us to gather data over a window of time and operate on it. We will need to take our tweet phrases, tokenize them, remove stop words and then count them. Let’s look at the code we can do to do that.
en = spacy.load('en_core_web_sm')
sw_spacy = en.Defaults.stop_words
def tokenize(sentiment__text):
key, text = sentiment__text
tokens = re.findall(r'[^\s!,.?":;0-9]+', text)
data = [(key, word.lower()) for word in tokens if word.lower() not in sw_spacy]
return data
flow.flat_map(tokenize)
Here we used the flat map operator with a tokenize function to take our tweets and return a series of tuples that are in the format of (sentiment, word) and are cleaned of stop words
Now we can use the fold_window operator to count the occurrences of the words, grouped by sentiment, over a window of time.
# Add a fold window to capture the count of words
# grouped by positive, negative and neutral sentiment
# over 1 minute period and then write them to a file
cc = SystemClockConfig()
wc = TumblingWindowConfig(length=timedelta(seconds=60))
def count_words():
return defaultdict(lambda:0)
def count(results, word):
results[word] += 1
return results
def sort_dict(key__data):
key, data = key__data
return (key, sorted(data.items(), key=lambda k_v: k_v[1], reverse=True)[:10])
flow.fold_window(
"count_words",
cc,
wc,
builder = count_words,
folder = count)
flow.map(sort_dict)
Finally, the last part of our dataflow will capture the output somewhere that we can make sense of it. For this we will use the Bytewax capture operator, which we will specify the function that writes our output to a file. To run our dataflow, we will use the run_main execution call, which instructs how we are going to run this dataflow.
def output_builder2(worker_index, worker_count):
def write_to_file(key__data):
sentiment, data = key__data
with open(f"outfile_{sentiment}.txt", 'w') as f:
f.seek(0)
for key, value in data:
f.write(f"{key}, {value}\n")
return write_to_file
flow.capture(ManualOutputConfig(output_builder2))
run_main(flow)
We are ready to go! Run the code and after a certain amount of time you will start to see the sentiment and tweet printing out because of the flow.inspect(print) step in our dataflow.
('negative', 'When your economic base spent the last 30 years investing in backwater countries to embed them in your supply chain and now you realize that mistake Yeah it s not going to be painless')
('positive', 'RT Is White House saying that they disagree with CPI as measure if inflation Absolutely right CPI most likely understat')
('positive', 'RT BITCOIN TOOK A HUGE DUMP AFTER US INFLATION DATA CAME OUT')
('positive', 'The Chancellor has compounded the problem for the UK Inflation is made by Russia and China We are having a trade war with China and no one is trying to stop the war in Ukraine The world has gone mad We more than most')
('positive', 'RT Inflation this past year of 8 2 AGAIN near a 40 yr high Fuel oil 58 6 Electricity 15 5 Pet food 14 0 Airf')
('positive', 'RT Two months ago Democrats passed the INFLATION REDUCTION ACT Today Inflation surges and rises to a 40 year high')
Maybe we need a better sentiment analysis model for this particular topic :/
If we look in our main directory, we can see that as well as scoring the utterances, we have also written the top ten most commonly occurring words to our corresponding sentiment outfiles (positive_outfile.txt, negative_outfile.txt, neutral_outfile.txt). And we can now analyze which words correspond to which sentiment, whether correctly or not.
Despite the so-so results, following this guide and doing some model tweaking yourselves, you will be able to successfully analyze Twitter data with Bytewax!
Conclusion
This article introduced Bytewax and the Twitter API. You learned to process tweets in real time by determining the sentiment of a tweet using Bytewax. All the code in this article is available on GitHub.
Bytewax can help you perform real-time analysis on data and much more. The library is robust and allows for parallelism, iterations, and scalability. Bytewax has a very well-documented API that can be found here. Get started today!
Give us a star on GitHub to support the project!
Wax On Wax Off - Deploying Dataflows on AWS with GitHub Actions

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.
Comparison of Stream Processing Frameworks Part 2
Other posts you may find interesting
View all articles
Online Machine Learning for IoT
A look at how to analyze IoT Sensors with Machine Learning
Written by Zander Matheson