

Uses Bytewax Version 0.18
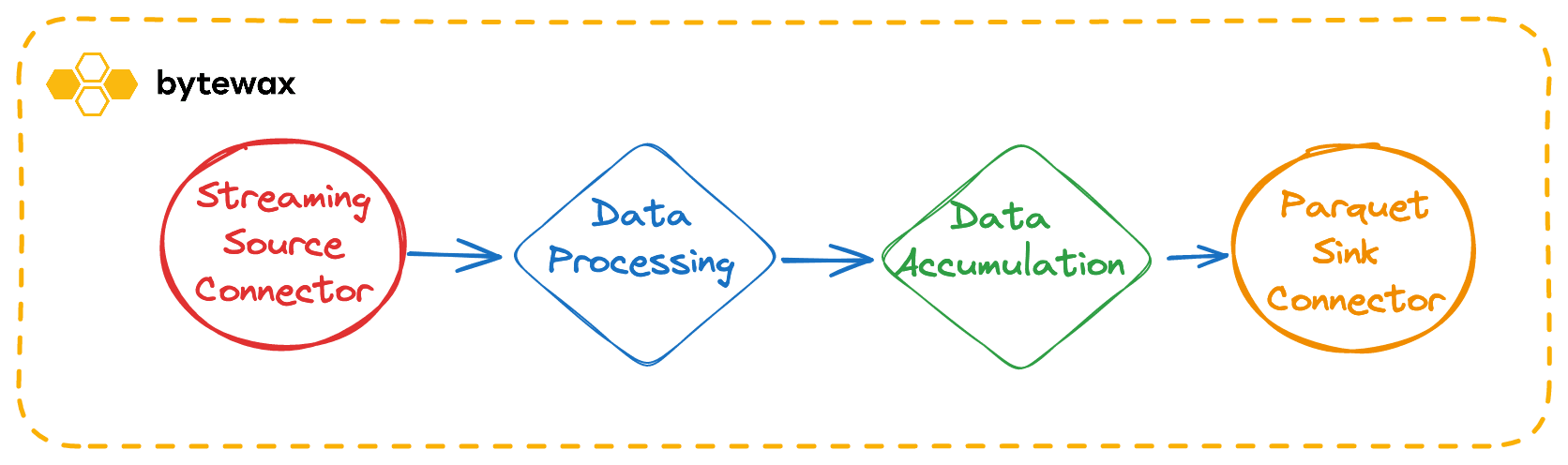
One of the most common use cases for stream processing is to take a stream(s) of data, modify it, and transform it into another format that can be used for other purposes. This could be for a variety of reasons, maybe the downstream system using the data requires a different format, maybe the infrastructure used internally cannot handle streams of data or maybe the consumer of the final data product needs the data to be aggregated at a different level than individual streaming records. Whatever the reason, one of the most common patterns is to use a stream processor to take streams of records and format them into parquet files that can be written to long-term storage like a datawarehouse, datalake or lakehouse.
In this blog post, we will use Bytewax to take simulated streaming web event data and put it in partitioned Parquet files in 5 second intervals by taking the following steps:
- Define a custom data source connector to our fake web events simulator.
- Deserialize the data and reformat it.
- Batch the records into a list and convert to an Apache Arrow Table.
- Write the events to partitioned Parquet Files.
Want to skip and go straight to the code? -> repo
What is Bytewax?
Bytewax is an open source Python stream processing framework that allows you to process data in real-time with Python. Bytewax provides a framework for describing how you connect to data sources, how you transform data, and where you output data. The input connectors are called sources, and the output connectors are sinks. In this example, we will write a custom source and a custom sink. Bytewax’s strengths include customizability and extensibility so there are a lot of use cases. One of which, is streaming ELT which we will look at here.
⭐Don’t forget to give us a star! ⭐- https://github.com/bytewax/bytewax
In addition to the open source project, there is a Bytewax Platform offering available that provides additional capabilities to support running in production with features like a management UI, authentication, monitoring, and disaster recovery.
Prerequisites
Before getting started, make sure you have the following Python packages installed as defined in the requirements.txt file shown below. We recommend using a new Python virtual environment when getting started with Python 3.7 or greater.
bytewax==0.18.0
fake-web-events==0.2.5
pandas==2.1.4
pyarrow==14.0.1
Writing a Custom Connector for Bytewax
For this blog post, we will simulate a stream of events happening on a website. To do this, we are going to make a custom connector for the data source using the Bytewax API and the fake_web_events package.
Source connectors are created from two classes, a partitioned source class and a source partition class. Combined they describe the behavior of the input connector. How the data is split amongst workers and how each worker consumes the data.
The partitioned source class is used by Bytewax when you run your Python file and is instantiated on each worker. The class has methods describing how to split the data so it can be parallelized with a list of the partitions (list_parts) and then what happens on the partition (build_part). Not every source can be partitioned so you can describe the ideal behavior when creating the source class which will inherit from the FixedPartitionSource.
class FakeWebEventsSource(FixedPartitionedSource):
def list_parts(self) -> List[str]:
return ["singleton"]
def build_part(self, now: datetime, for_part: str, resume_state: Optional[int]) -> SimulatedPartition:
assert for_part == "singleton"
assert resume_state is None
return SimulatedPartition()
Next, the individual Source Partition class is used to describe the behavior of each worker. This is where you describe how your data will be consumed. Will it be chunked? is there an asynchronous API that needs to be dealt with? Is it eager or is there a polling delay?
To describe the behavior we want, there are class methods next_batch, next_awake, snapshot, and close.
next_batchdescribes what to do with the handle of your streamnext_awakeis used instead ofsleepto prevent eagerly requesting the next batch.snapshotdescribes how to save your progress.closeprovides a way to gracefully exit on EOF or something else.
These methods will be used by the bytewax execution when you run your dataflow. Below we have built a simulation that will use the library fake_web_events. Notice how we wrap our single item into a list in this instance because our Simulation handle, self.events, only returns one item for each next() call.
class SimulatedPartition(StatefulSourcePartition):
def __init__(self):
self.events = Simulation(user_pool_size=5, sessions_per_day=100).run(
duration_seconds=10
)
def next_batch(self, sched: datetime) -> List[Any]:
return [json.dumps(next(self.events))]
def snapshot(self) -> Any:
return None
Constructing a Bytewax Dataflow to Convert to Parquet
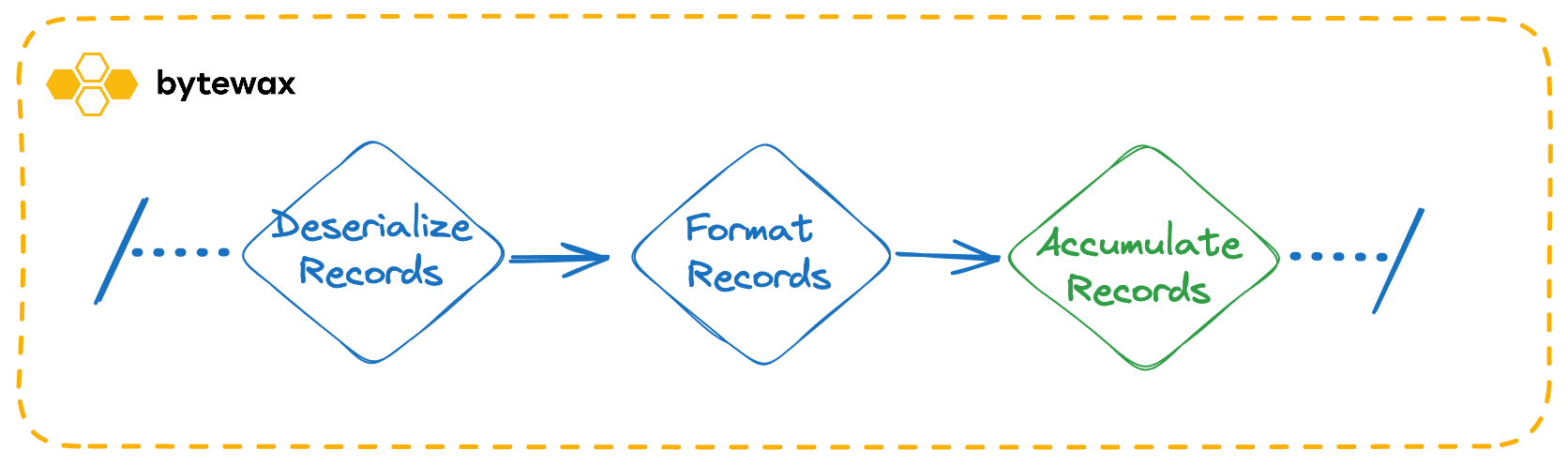
With our input connector written, we can build the dataflow to take the input, format it correctly, group the data into key-based windows, convert it into the Apache Arrow format, and then write it out into parquet files. We will write the following steps for our dataflow.
- Deserialize the records in the stream
- Format the records
- Batch the records into a list
- Convert the list into an Arrow Table
The Dataflow can be explained with a directed graph like the image below.
- To start with, we will define the dataflow object, add our input, and then use the
mapoperator to convert the JSON event from the input source into a Python object we can work with. If we had any other processing like flattening, we could do that following or in this step.
flow = Dataflow("events_to_parquet")
stream = op.input("input", flow, FakeWebEventsSource())
stream = op.map("load_json", stream, json.loads)
At this point, we would see records like the following if we were to print out our stream:
{"page_url_path": "/path", "event_timestamp": "2022-01-02 03:04:05", ...}
- In the next two steps, we are going to reformat our data using the Bytewax
mapoperator and then change the shape of the record with thekey_onoperator. In themapoperator, we will add additional columns to our dataset that we will eventually use to partition the data when we write it to Parquet files. In thekey_onoperator we will reformat it into a tuple of the format (key,DataFrame) that we can use to accumulate the records in the batch step.
We first define the functions that will run in the map operators:
def add_date_columns(event: dict) -> dict:
timestamp = datetime.fromisoformat(event["event_timestamp"])
event["year"] = timestamp.year
event["month"] = timestamp.month
event["day"] = timestamp.day
return event
And then define the steps in the dataflow:
stream = op.map("add_date_columns", stream, add_date_columns)
keyed_stream = op.key_on(
"group_by_page", stream, lambda record: record["page_url_path"]
)
The shape of our data has now changed to include additional fields and the key has been pulled out:
("/path", {"page_url_path": "/path", "year": 2022, "month": 1, ...})
- In the next step in our dataflow we will use the
collectoperator to collect records into a list. Thecollectoperator will group records by the key provided in the tuple(key, record)into a list and return(key, [records]). The length of the list is specified by themax_sizeunless the operator times out waiting for the max number of records. This is based on thetimeoutargument.
collected_stream = op.collect(
"collect_records", keyed_stream, max_size=50, timeout=timedelta(seconds=2)
)
- Now that we have collected records into a list, we can then use Pyarrow's
Table.from_pylistto convert it into an Arrow Table. This will allow us to easily write the table as a parquet file in the sink.
arrow_stream = op.map(
"arrow_table",
collected_stream,
lambda keyed_batch: (keyed_batch[0], Table.from_pylist(keyed_batch[1]))
)
Custom Output Sink
Now that our data is being reduced into Arrow Tables, we can create an output sink that will take those Tables and write them out as Parquet. Since there isn’t currently an off-the-shelf connector, let’s look at how we have built a custom connector using the Bytewax API.
Output connectors, or Sinks have many of the same functionalities as the input connectors. They have a Partitioned Sink and then a Sink Partition class that describes the build and run behavior, similar to the input source we developed earlier. The FixedPartitionClass will be used as the parent of our ParquetSink class to define the behavior for each partition. Since we are not enabling parallelized writes for this dataflow, we limit to a single partition and then we return the ParquetPartition class when Bytewax builds each partition sink on each worker with build_part.
The ParquetPartition class inherits from the StatefulSinkPartition and similarly to the StatefulSourcePartition this is used to describe what to do with each batch of data received in the write_batch method.
Our ParquetParition object will be an Arrow Table in the write_batch method, and we will write those as parquet files to the “parquet_demo_out” path with the partitions we described.
class ParquetPartition(StatefulSinkPartition):
def write_batch(self, batch: List[Table]) -> None:
for table in batch:
parquet.write_to_dataset(
table,
root_path="parquet_demo_out",
partition_cols=["year", "month", "day", "page_url_path"],
)
def snapshot(self) -> Any:
return None
class ParquetSink(FixedPartitionedSink):
def list_parts(self):
return ["singleton"]
def assign_part(self, item_key):
return "singleton"
def build_part(self, for_part, resume_state):
return ParquetPartition()
🎉 Putting it all together! 🎉
Now that we have written our dataflow, we can run our file using the bytewax run module, as we would run a Python module. This is just like you might do with Flask or FastAPI. 🎉
> python -m bytewax.run event_to_parquet.py
Takeaway
While there are many ways to turn streaming events into parquet files, the simplicity of Bytewax is unique as is the ability to leverage the Python tools a lot of developers already know.
This template can be expanded to do additional processing on these events or you could join multiple event streams together into a single table.
Interested in more streaming solutions, check out our guides on our website.
Welcome to 2024!

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

