{kind=link}
{kind=link}

Understanding the role of windowing in streaming applications
By Laura Funderburk & Jonas Best
Stream processing transforms data in motion within continuous, unbounded data streams. In our previous blog post, we explored the differences between stateful and stateless operators in stream processing. While stateless transformations handle each event independently, stateful transformations consider the context surrounding each event during processing.
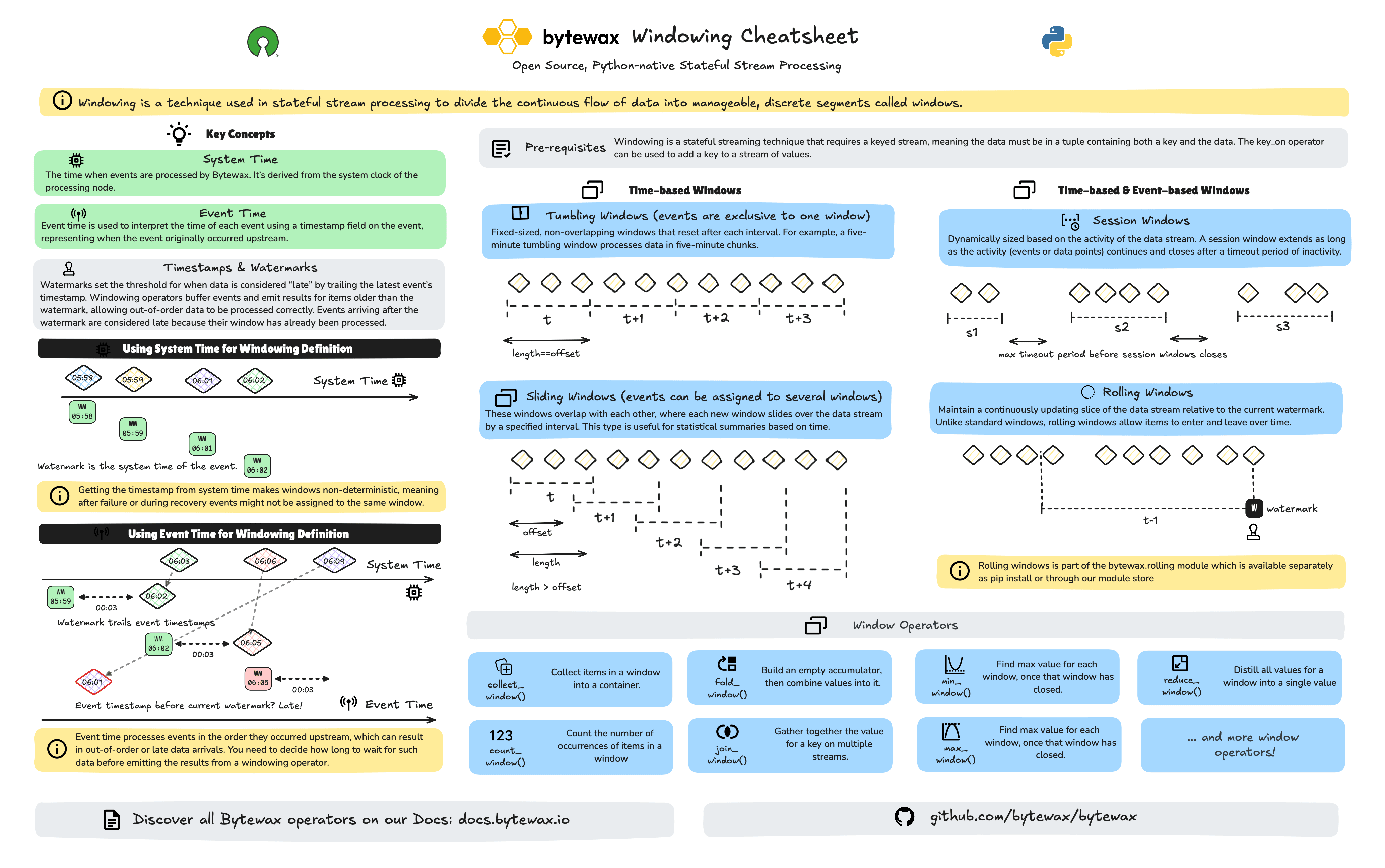
Windowing is a fundamental concept in stateful stream processing. It divides continuous data streams into defined batches called windows. By specifying a window size, events are accumulated within each window and processed collectively once the window closes. This approach enables statistical computations—such as counts, aggregations, and averages—on data streams, which were traditionally only feasible with batch processing.
In this blog, we introduce our latest windowing cheatsheet for Bytewax focusing on how to efficiently process and analyze data streams in motion, leveraging Bytewax’s windowing capabilities.
Key Concepts: watermarks and clocks
Before we get started building code, let's unpack the key assumptions and building blocks of applications that enable this approach.
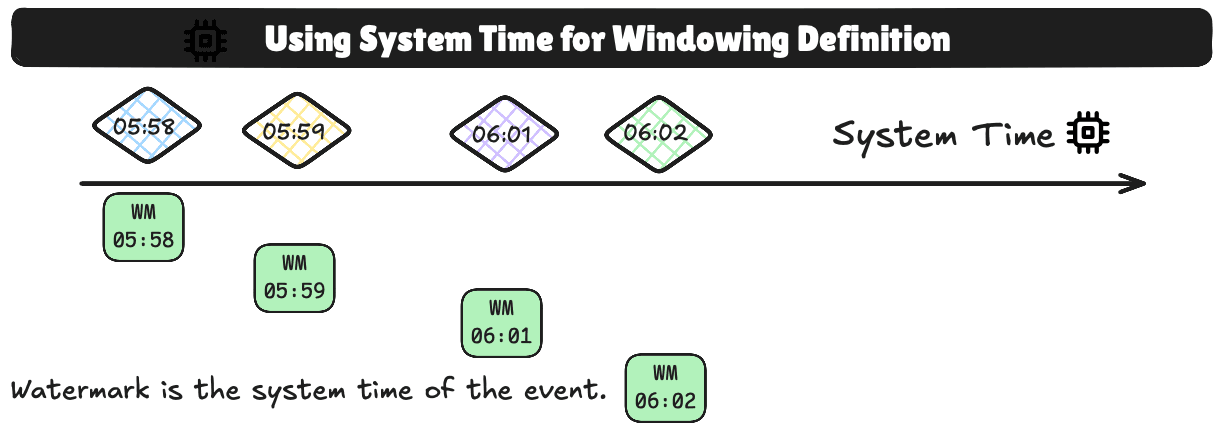
Watermarks and Late Data in Bytewax
When dealing with streaming data, it’s common to face challenges like handling out-of-order or late-arriving events. Since Bytewax processes streams of data, we need a way to manage how long to wait for late-arriving data before finalizing the calculations for a window. This is where watermarks come in.
A watermark represents a timestamp beyond which the system assumes no more data with earlier timestamps will arrive. It allows Bytewax to process windows and send results downstream without having to wait indefinitely for late data. Events that arrive with timestamps earlier than the current watermark are considered late and will not be assigned to any window.
Clocks: Defining Time in Windowing Operations
A clock is responsible for defining the notion of time within the windowing system. For each clock type, Bytewax needs to answer two important questions:
- What is the timestamp for a value?
- What is the current watermark?
Bytewax supports two main clock types: System Time, using the SystemClock class, and Event Time using the EventClock class.
When implementing windowing in Bytewax, you need to decide whether to use System Time or Event Time for your stream processing. The decision largely depends on how you handle the timing of events and whether you need to account for late or out-of-order data.
System Time: For Real-Time Processing Without Late Data
If your data stream is live, and events arrive in real-time without the possibility of late or out-of-order data, or you don't care about late or out-of-order data, using System Time is the most straightforward approach. In this mode, each event is assigned the system's current time, and the watermark is always the current system time.
Advantages:
- No need to handle out-of-order or late data.
- It's simple: No need to parse records and event time.
- Windowing happens as soon as the data arrives, making it highly efficient for real-time scenarios.
- All timestamps and watermarks are generated in UTC, ensuring consistency across the data flow.
Drawbacks:
- Not possible to differentiate between ordered data and out-of-order data.
- This method is unsuitable for historical or backlogged event streams, where out-of-order events may occur.
- Non-determinism: Recovery will not function properly and the behavior will change between different runs of the data.
Bytewax class:SystemClock
- Watermark: The watermark is based on the current system time, and all timestamps and watermarks are generated in UTC.
- No Out-of-Order Events: This method doesn’t handle out-of-order events because the data is processed immediately.
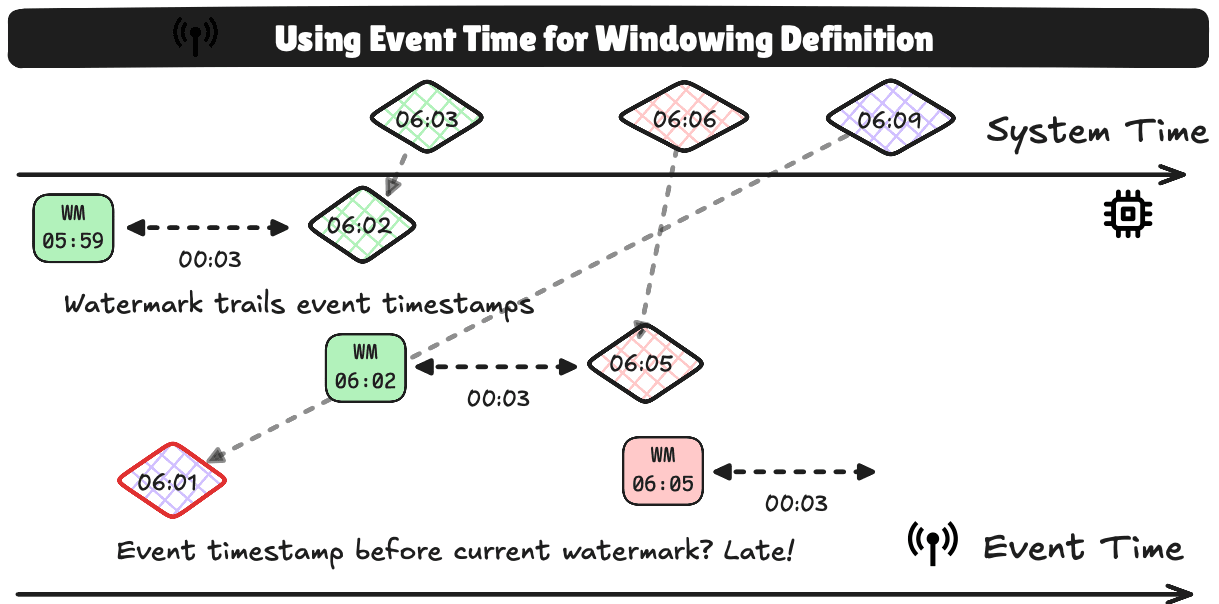
Event Time: For Handling Out-of-Order or Late Data
If your events carry embedded timestamps (such as from devices or sensors), and you need to account for out-of-order or late-arriving data. The watermark is based on the largest timestamp seen so far, adjusted by the waiting duration and the system time since the event was observed.
Advantages:
- Can handle out-of-order or late events within a bounded delay by using the
wait_for_system_durationparameter. - Allows for customization of system time handling via now_getter and can adapt to non-UTC time zones if needed.
- Useful for both real-time and batch data processing, ensuring the correct ordering of events even when they arrive out of sequence.
- Determinism: Recovery and replaying of the stream will result in the same output from the dataflow.
Drawbacks:
- There may be slight delays in processing due to waiting for late data.
- The watermark can only move forward, meaning once it has advanced, any data arriving with a timestamp before the watermark is discarded.
- Requires careful tuning of the
wait_for_system_durationto balance timeliness with the tolerance for out-of-order events.
Bytewax class:EventClock
- Watermark: The watermark is calculated based on the largest timestamp seen, adjusted by the waiting duration and system time elapsed.
- Late Events: It allows handling of late events within a specific delay using the
wait_for_system_duration. - Time Zones: You can specify custom system time handling through
now_getterandto_system_utcto support different time zones or non-UTC settings.
Let's now take a look at window types.
Window Types
Windowing is a stateful streaming technique used to divide the continuous flow of data into manageable, discrete segments. It requires a keyed stream, meaning the data must be in a tuple containing both a key and the data. The key_on operator can be used to add a key to a stream of values.
Bytewax differentiates between three key windowing techniques:
- Tumbling Windows: Tumbling windows are fixed-size, non-overlapping intervals that reset after a specified duration. For example, a five-minute tumbling window processes data in five-minute segments. A key characteristic of tumbling windows is that each event is assigned to only one window. In Bytewax, tumbling windows can be created using the
TumblingWindower.
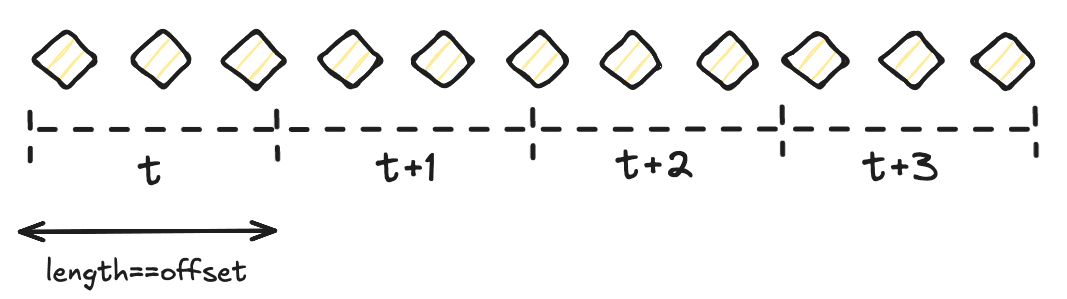
- Sliding Windows: These windows overlap with each other, where each new window slides over the data stream by a specified interval called
offsetand is open for a specific duration calledlength. Overlapping windows mean that events can be part of several windows. Sliding windows can be created using theSlidingWindower.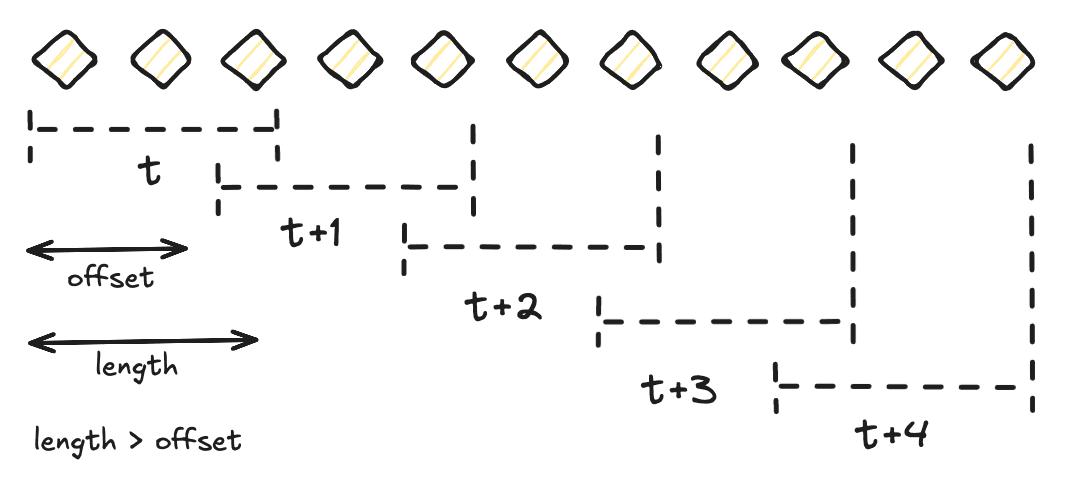
- Session Windows: Dynamically sized based on the activity of the data stream. A session window extends as long as the activity (events or data points) continues and closes after a timeout period of inactivity called
gap. Session windows can be created usingSessionWindower.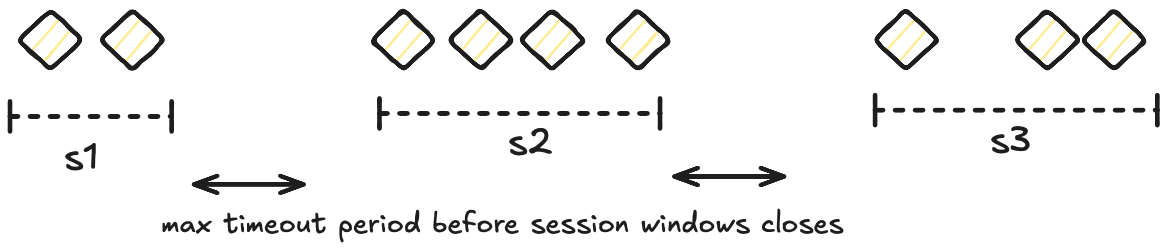
Computations over windows: Windowing operators
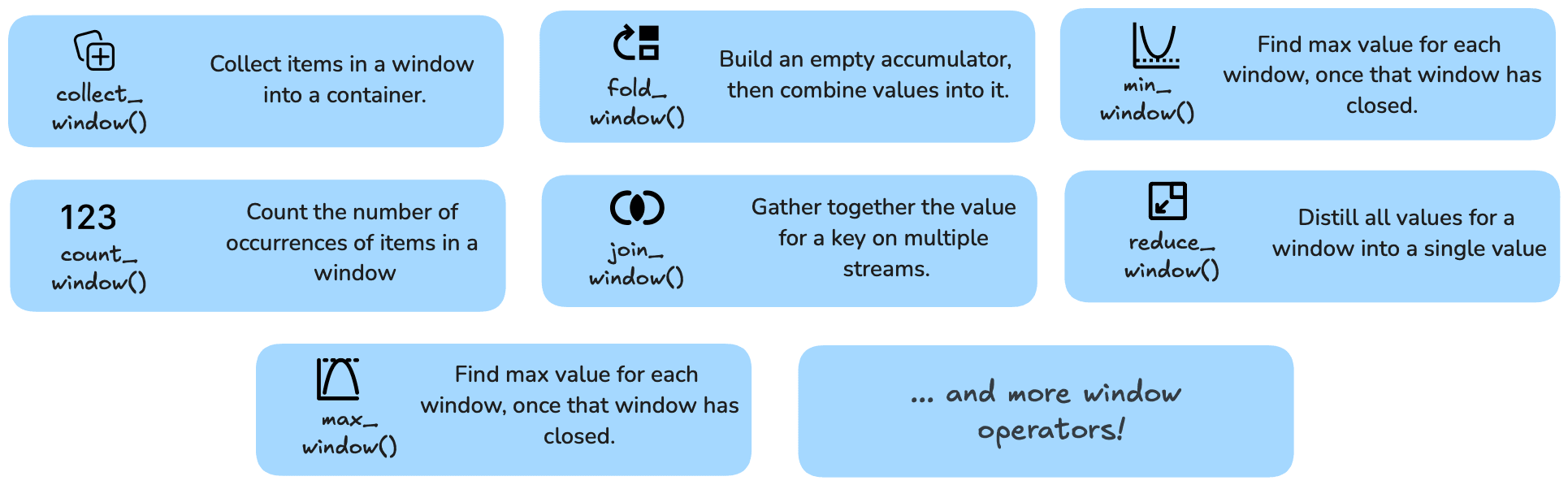
Once you’ve established your windowing strategy, Bytewax provides a suite of windowing operators that facilitate a wide range of real-time computations within each window. These operators enable tasks such as aggregating data, counting events, calculating averages, and performing complex event processing directly on the segmented data streams. For instance, operators like count_window and fold_window allow you to efficiently tally events and accumulate values, while join_window enables the merging of data from multiple streams for enriched analysis.
We're now going to showcase how to combine these elements using Python.
Combining all elements - counting fruits in different windows
In this example, we will create a Bytewax dataflow that will count the number of instances of a given fruit in each of the windows.
We'll start by installing Bytewax:
python -m venv venv
./venv/bin/activate
pip install bytewax==0.21.0
In the example below, we will create a tumbling window of 10 minutes that starts at 12:00. We can think of the windows as follows.
Time Axis (UTC):
|-----------------|-----------------|-----------------|
12:00 12:10 12:20 12:30
Window 0 Window 1 Window 2
We can define the clock, window and operator as follows:
from bytewax.operators.windowing import (EventClock,
TumblingWindower,
count_window)
# Initialize clock
clock = EventClock(
ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0),
)
# Define the windowing strategy
windower = TumblingWindower(
length=timedelta(minutes=15),
align_to=datetime(2023, 1, 1, 12, 0, tzinfo=timezone.utc),
)
# Use count_window to count occurrences of each item in each window
windowed = count_window(
step_id="count_window",
up=up,
clock=clock,
windower=windower,
key=lambda x: x[0], # Use the item name as the key
)
Here is a complete dataflow.
from datetime import datetime, timedelta, timezone
from bytewax.dataflow import Dataflow
import bytewax.operators as op
from bytewax.operators.windowing import (EventClock,
TumblingWindower,
count_window)
from bytewax.testing import TestingSource, run_main
# Create a new dataflow
flow = Dataflow("count_window_example")
# Sample data with timestamps
data = [
("apple", datetime(2023, 1, 1, 12, 0, tzinfo=timezone.utc)),
("banana", datetime(2023, 1, 1, 12, 5, tzinfo=timezone.utc)),
("apple", datetime(2023, 1, 1, 12, 10, tzinfo=timezone.utc)),
("banana", datetime(2023, 1, 1, 12, 15, tzinfo=timezone.utc)),
("apple", datetime(2023, 1, 1, 12, 20, tzinfo=timezone.utc)),
("cherry", datetime(2023, 1, 1, 12, 25, tzinfo=timezone.utc)),
]
# Input stream
up = op.input("input", flow, TestingSource(data))
# Define the clock using event timestamps
def extract_timestamp(x):
return x[1]
# Initialize clock
clock = EventClock(
ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0),
)
# Define the windowing strategy
windower = TumblingWindower(
length=timedelta(minutes=15),
align_to=datetime(2023, 1, 1, 12, 0, tzinfo=timezone.utc),
)
# Use count_window to count occurrences of each item in each window
windowed = count_window(
step_id="count_window",
up=up,
clock=clock,
windower=windower,
key=lambda x: x[0], # Use the item name as the key
)
# Format and output the results
def format_output(item):
key, (window_id, count) = item
return f"Item '{key}' occurred {count} times in Window {window_id}"
formatted = op.map("format_output", windowed.down, format_output)
# Inspect the output
op.inspect("output", formatted)
# Run the dataflow
run_main(flow)
Executing the dataflow assuming our code is stored in a file named dataflow.py then returns
python -m bytewax.run dataflow:flow
count_window_example.output: "Item 'apple' occurred 1 times in Window 0"
count_window_example.output: "Item 'banana' occurred 1 times in Window 0"
count_window_example.output: "Item 'apple' occurred 1 times in Window 1"
count_window_example.output: "Item 'apple' occurred 1 times in Window 2"
count_window_example.output: "Item 'banana' occurred 1 times in Window 1"
count_window_example.output: "Item 'cherry' occurred 1 times in Window 2"
Let's take a look at a more realistic example. In the next example, we will look at smoothie orders data.
Processing smoothie orders with windowing
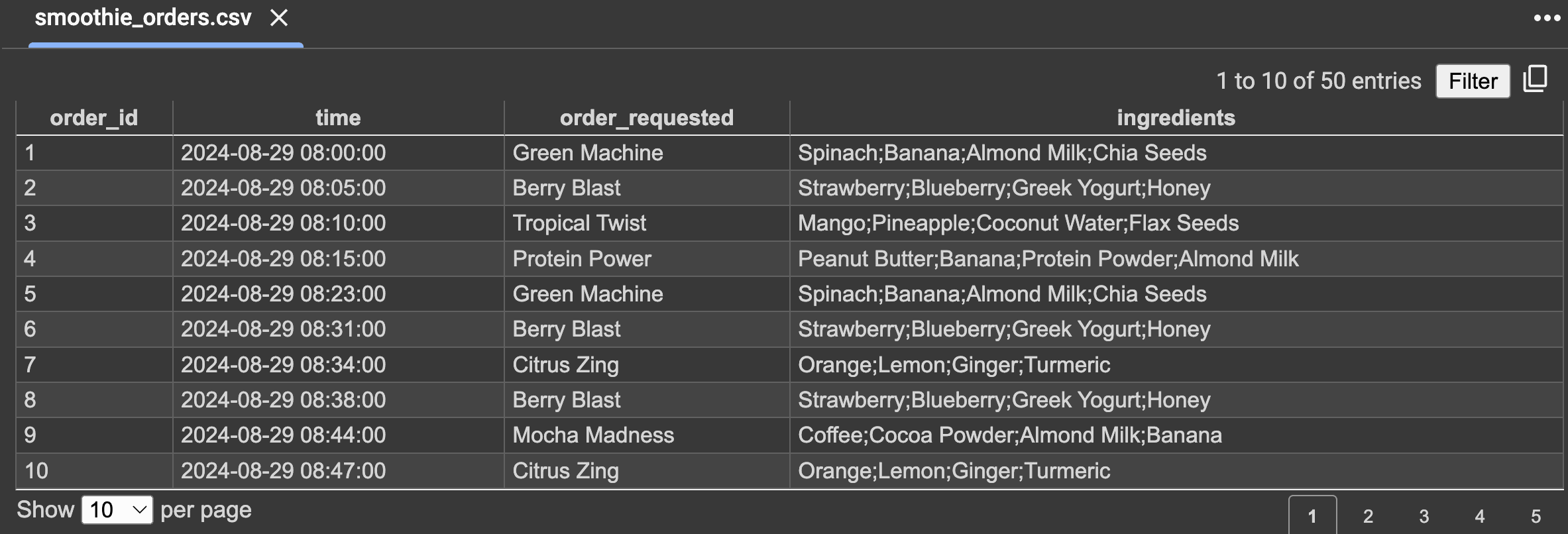
Here is a mock dataset containing smoothie order data. Let's apply windowing techniques on this data to answer specific questions.
Example 1: Using TumblingWindower to Count Smoothie Orders per 30-Minute Interval
Objective: Count the number of smoothie orders every 30 minutes starting from 08:00 AM until 12:30 PM.
Dataflow Setup: We define the input data from a CSV file containing smoothie orders, where each order has a timestamp. The TumblingWindower is used to create fixed, non-overlapping 30-minute windows. We use an event clock to ensure that the windowing is based on the event's timestamp i.e., when the smoothie order was placed.
We can define the type of windower, clock and operator as follows:
from bytewax.operators.windowing import (EventClock,
TumblingWindower,
count_window)
# Create a tumbling window for every 30 minutes
windower = TumblingWindower(length=timedelta(minutes=30))
# Clock based on event timestamps
clock = EventClock(ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0))
# Count the number of orders in each window
windowed = count_window(
step_id="count_orders",
up=parsed,
clock=clock,
windower=windower,
key=lambda x: "total_orders", # Use a constant key to aggregate all orders
)
The complete dataflow that incorporates functionality to count the number of orders is as follows:
from datetime import datetime, timedelta, timezone
from bytewax.dataflow import Dataflow
import bytewax.operators as op
from bytewax.operators.windowing import (EventClock,
TumblingWindower,
count_window)
from bytewax.testing import TestingSource, run_main
from bytewax.connectors.files import CSVSource
from pathlib import Path
# Create a new dataflow
flow = Dataflow("tumbling_window_example")
# Input stream
csv_file_path = Path("smoothie_orders.csv")
up = op.input("orders", flow, CSVSource(csv_file_path))
# Parse the CSV data
def parse_order(row):
order_id = int(row["order_id"])
time = datetime.strptime(row["time"],\
"%Y-%m-%d %H:%M:%S").replace(tzinfo=timezone.utc)
order_requested = row["order_requested"]
ingredients = row["ingredients"]
return (order_id, time, order_requested, ingredients)
parsed = op.map("parse_order", up, parse_order)
# Define the clock using event timestamps
def extract_timestamp(x):
return x[1] # Extract the timestamp from the data
clock = EventClock(
ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0),
)
# Define the tumbling window of 30 minutes starting at 08:00
windower = TumblingWindower(
length=timedelta(minutes=30),
align_to=datetime(2024, 8, 29, 8, 0, 0, tzinfo=timezone.utc),
)
# Count the number of orders in each window
windowed = count_window(
step_id="count_orders",
up=parsed,
clock=clock,
windower=windower,
key=lambda x: "total_orders", # Use a constant key to aggregate all orders
)
# Format and output the results
def format_output(item):
key, (window_id, count) = item
window_start = windower.align_to + timedelta(minutes=30 * window_id)
window_end = window_start + timedelta(minutes=30)
return f"Window {window_id}\
({window_start.strftime('%H:%M')}\
- {window_end.strftime('%H:%M')}): {count} orders"
formatted = op.map("format_output", windowed.down, format_output)
# Inspect the output
op.inspect("output", formatted)
# Run the dataflow
run_main(flow)
Executing this yields:
tumbling_window_example.output: 'Window 0 (08:00 - 08:30): 5 orders'
tumbling_window_example.output: 'Window 1 (08:30 - 09:00): 7 orders'
tumbling_window_example.output: 'Window 2 (09:00 - 09:30): 6 orders'
tumbling_window_example.output: 'Window 3 (09:30 - 10:00): 5 orders'
tumbling_window_example.output: 'Window 4 (10:00 - 10:30): 5 orders'
tumbling_window_example.output: 'Window 5 (10:30 - 11:00): 4 orders'
tumbling_window_example.output: 'Window 6 (11:00 - 11:30): 6 orders'
tumbling_window_example.output: 'Window 7 (11:30 - 12:00): 4 orders'
tumbling_window_example.output: 'Window 8 (12:00 - 12:30): 8 orders'
Key steps:
- Reading from CSV: We use
CSVSourceto read data fromsmoothie_orders.csv. - Parsing CSV Data: The
parse_orderfunction parses each row into a tuple containingorder_id,time,order_requested, andingredients. - Clock Definition: We define an
EventClockusing the parsed timestamp. - Windowing Strategy: We use a
TumblingWindowerto create 30-minute non-overlapping windows starting at 08:00. - Counting Orders: We use the
count_windowwindowing operator to count the total number of orders in each window. - Formatting Output: We format the results to display the window time range and the number of orders.
- Running the Dataflow: We execute the dataflow using
run_main(flow).
Let's take a look at a sliding window example next.
Example 2: Using Sliding Windows to Track Orders Across Overlapping Windows
Objective: Track smoothie orders using overlapping windows to smooth fluctuations in order rates and calculate moving averages.
Dataflow Setup In this example, we create sliding windows that overlap with each other. This type of windowing is useful when you want to smooth the data or calculate rolling statistics like a moving average.
We can define the type of windower, clock and operator as follows:
from bytewax.operators.windowing import (EventClock,
SlidingWindower,
count_window)
# Create a sliding window with an offset of 15 minutes and length of 30 minutes
windower = SlidingWindower(offset=timedelta(minutes=15),
length=timedelta(minutes=30))
# Define clock based on event timestamps
clock = EventClock(ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0))
# Count the number of orders in each window
windowed = count_window(
step_id="count_orders_sliding",
up=parsed,
clock=clock,
windower=windower,
key=lambda x: "total_orders",
)
The complete dataflow that incorporates sliding window functionality to count the number of orders is as follows:
from datetime import datetime, timedelta, timezone
from bytewax.dataflow import Dataflow
import bytewax.operators as op
from bytewax.operators.windowing import EventClock, SlidingWindower, count_window
from bytewax.testing import TestingSource, run_main
# Create a new dataflow
flow = Dataflow("sliding_window_example")
# Input stream
up = op.input("orders", flow, CSVSource(csv_file_path))
# Parse the CSV data
def parse_order(row):
order_id = int(row["order_id"])
time = datetime.strptime(row["time"],\
"%Y-%m-%d %H:%M:%S").replace(tzinfo=timezone.utc)
order_requested = row["order_requested"]
ingredients = row["ingredients"]
return (order_id, time, order_requested, ingredients)
parsed = op.map("parse_order", up, parse_order)
# Define the clock using event timestamps
def extract_timestamp(x):
return x[1]
clock = EventClock(
ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0),
)
# Define the sliding window: length of 1 hour, slides every 15 minutes
windower = SlidingWindower(
length=timedelta(hours=1),
offset=timedelta(minutes=15),
align_to=datetime(2024, 8, 29, 8, 0, 0, tzinfo=timezone.utc),
)
# Count the number of orders in each window
windowed = count_window(
step_id="count_orders_sliding",
up=parsed,
clock=clock,
windower=windower,
key=lambda x: "total_orders",
)
# Format and output the results
def format_output(item):
key, (window_id, count) = item
window_start = windower.align_to + timedelta(minutes=15 * window_id)
window_end = window_start + windower.length
return f"Window {window_id}\
({window_start.strftime('%H:%M')} -\
{window_end.strftime('%H:%M')}): {count} orders"
formatted = op.map("format_output", windowed.down, format_output)
# Inspect the output
op.inspect("output", formatted)
# Run the dataflow
run_main(flow)
This yields:
sliding_window_example.output: 'Window -3 (07:15 - 08:15): 3 orders'
sliding_window_example.output: 'Window -2 (07:30 - 08:30): 5 orders'
sliding_window_example.output: 'Window -1 (07:45 - 08:45): 9 orders'
sliding_window_example.output: 'Window 0 (08:00 - 09:00): 12 orders'
sliding_window_example.output: 'Window 1 (08:15 - 09:15): 12 orders'
sliding_window_example.output: 'Window 2 (08:30 - 09:30): 13 orders'
sliding_window_example.output: 'Window 3 (08:45 - 09:45): 11 orders'
sliding_window_example.output: 'Window 4 (09:00 - 10:00): 11 orders'
sliding_window_example.output: 'Window 5 (09:15 - 10:15): 11 orders'
sliding_window_example.output: 'Window 6 (09:30 - 10:30): 10 orders'
sliding_window_example.output: 'Window 7 (09:45 - 10:45): 10 orders'
sliding_window_example.output: 'Window 8 (10:00 - 11:00): 9 orders'
sliding_window_example.output: 'Window 9 (10:15 - 11:15): 8 orders'
sliding_window_example.output: 'Window 10 (10:30 - 11:30): 10 orders'
sliding_window_example.output: 'Window 11 (10:45 - 11:45): 10 orders'
sliding_window_example.output: 'Window 12 (11:00 - 12:00): 10 orders'
sliding_window_example.output: 'Window 13 (11:15 - 12:15): 12 orders'
sliding_window_example.output: 'Window 14 (11:30 - 12:30): 12 orders'
sliding_window_example.output: 'Window 15 (11:45 - 12:45): 10 orders'
sliding_window_example.output: 'Window 16 (12:00 - 13:00): 8 orders'
sliding_window_example.output: 'Window 17 (12:15 - 13:15): 4 orders'
- Windowing Strategy: We use a
SlidingWindowerwith a window length of 1 hour, sliding every 15 minutes. - Usage: We count the number of orders in each window to calculate a moving average.
- Formatting Output: We adjust the window start and end times based on the sliding window.
Let's not take a look at an example using session windows.
Example 3: Using Session Windows to Group Orders by Activity
Objective: Group smoothie orders that occur closely together in time into dynamic session windows, which close after a period of inactivity.
Dataflow Setup: Unlike fixed or sliding windows, session windows are dynamically sized. They group events (smoothie orders) that occur within a short time of each other, and they close after a period of inactivity.
We can define the type of windower, clock and operator as follows:
from bytewax.operators.windowing import (EventClock,
SessionWindower,
collect_window)
# Create a session window that closes after 10 minutes of inactivity
windower = SessionWindower(gap=timedelta(minutes=10))
# Define clock based on event timestamps
clock = EventClock(ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0))
windowed = collect_window(
step_id="collect_sessions",
up=keyed,
clock=clock,
windower=windower,
)
The complete dataflow looks as follows:
# assumes previous imports
from bytewax.operators.windowing import (EventClock,
SessionWindower,
collect_window)
# Create a new dataflow
flow = Dataflow("session_window_example")
# Input stream
up = op.input("orders", flow, CSVSource(csv_file_path))
# Parse the CSV data
def parse_order(row):
order_id = int(row["order_id"])
time = datetime.strptime(row["time"],\
"%Y-%m-%d %H:%M:%S").replace(tzinfo=timezone.utc)
order_requested = row["order_requested"]
ingredients = row["ingredients"]
return (order_id, time, order_requested, ingredients)
parsed = op.map("parse_order", up, parse_order)
# Key the stream by a constant key since we want to group all orders together
keyed = op.key_on("key_on", parsed, lambda x: "all_orders")
# Define the clock using event timestamps
def extract_timestamp(x):
return x[1]
clock = EventClock(
ts_getter=extract_timestamp,
wait_for_system_duration=timedelta(seconds=0),
)
# Define the session window with a gap of 5 minutes
windower = SessionWindower(
gap=timedelta(minutes=5),
)
# Collect orders into sessions
windowed = collect_window(
step_id="collect_sessions",
up=keyed,
clock=clock,
windower=windower,
)
# Format and output the results
def format_output(item):
key, (window_id, orders) = item
order_ids = [order[0] for order in orders]
timestamps = [order[1] for order in orders]
session_start = min(timestamps).strftime('%H:%M')
session_end = max(timestamps).strftime('%H:%M')
return f"Session {window_id}\
({session_start} - {session_end}): Order ID {order_ids}"
formatted = op.map("format_output", windowed.down, format_output)
# Inspect the output
op.inspect("output", formatted)
# Run the dataflow
run_main(flow)
This returns:
session_window_example.output: 'Session 0 (08:00 - 08:15): Order ID [1, 2, 3, 4]'
session_window_example.output: 'Session 1 (08:23 - 08:23): Order ID [5]'
session_window_example.output: 'Session 2 (08:31 - 08:38): Order ID [6, 7, 8]'
session_window_example.output: 'Session 3 (08:44 - 08:56): Order ID [9, 10, 11, 12]'
session_window_example.output: 'Session 4 (09:02 - 09:22): Order ID [13, 14, 15, 16, 17]'
session_window_example.output: 'Session 5 (09:28 - 09:28): Order ID [18]'
session_window_example.output: 'Session 6 (09:36 - 09:39): Order ID [19, 20]'
session_window_example.output: 'Session 7 (09:45 - 09:45): Order ID [21]'
session_window_example.output: 'Session 8 (09:51 - 09:51): Order ID [22]'
session_window_example.output: 'Session 9 (09:58 - 09:58): Order ID [23]'
session_window_example.output: 'Session 10 (10:05 - 10:14): Order ID [24, 25, 26]'
session_window_example.output: 'Session 11 (10:20 - 10:20): Order ID [27]'
session_window_example.output: 'Session 12 (10:28 - 10:33): Order ID [28, 29]'
session_window_example.output: 'Session 13 (10:41 - 10:41): Order ID [30]'
session_window_example.output: 'Session 14 (10:48 - 10:48): Order ID [31]'
session_window_example.output: 'Session 15 (10:56 - 10:56): Order ID [32]'
session_window_example.output: 'Session 16 (11:02 - 11:02): Order ID [33]'
session_window_example.output: 'Session 17 (11:09 - 11:09): Order ID [34]'
session_window_example.output: 'Session 18 (11:16 - 11:19): Order ID [35, 36]'
session_window_example.output: 'Session 19 (11:25 - 11:28): Order ID [37, 38]'
session_window_example.output: 'Session 20 (11:36 - 11:41): Order ID [39, 40]'
session_window_example.output: 'Session 21 (11:48 - 11:48): Order ID [41]'
session_window_example.output: 'Session 22 (11:56 - 12:29): Order ID [42, 43, 44, 45, 46, 47, 48, 49, 50]'
In this example, we can observe times where more orders are placed in each of the sessions and also observe the gaps in between. This dataflow implemented a session window of 10 minutes to identify order IDs and formats the result for easier review.
Conclusion
Windowing is essential in stream processing, allowing us to efficiently handle large-scale data streams by segmenting them into manageable windows. In this blog, we explored how to apply different kinds of windowing techniques to a smoothie shop scenario by combining clocks, windowing technique and operators within a Bytewax dataflow to gain insights from the data.
Real-time Data Processing from MongoDB to Bytewax Using Estuary Flow

Jonas Best
Chief of StaffJonas brings extensive experience from Accenture and Monitor Deloitte, where he managed projects at the intersection of technology and business. Before joining Bytewax, he attended business school at the University of St. Gallen and HEC Paris. He is crucial in coordinating Bytewax's strategic efforts and ensuring seamless operations.
Laura Funderburk
Senior Developer AdvocateLaura Funderburk holds a B.Sc. in Mathematics from Simon Fraser University and has extensive work experience as a data scientist. She is passionate about leveraging open source for MLOps and DataOps and is dedicated to outreach and education.
Introducing the Bytewax InfluxDB Connector
Other posts you may find interesting
View all articles
Bytetalks Ep. 1: Real-Time Analytics with Bytewax & ClickHouse
Discover use cases like clickstream and financial data processing with ClickHouse and Bytewax integration.
Written by Zander Matheson & Laura Funderburk