

One true adage in our current era is that we generate more data every year. This year, we are expected to produce 147 zettabytes of data—a twelve-fold increase in just a decade.1 An increasing share of this data is now produced in real time.
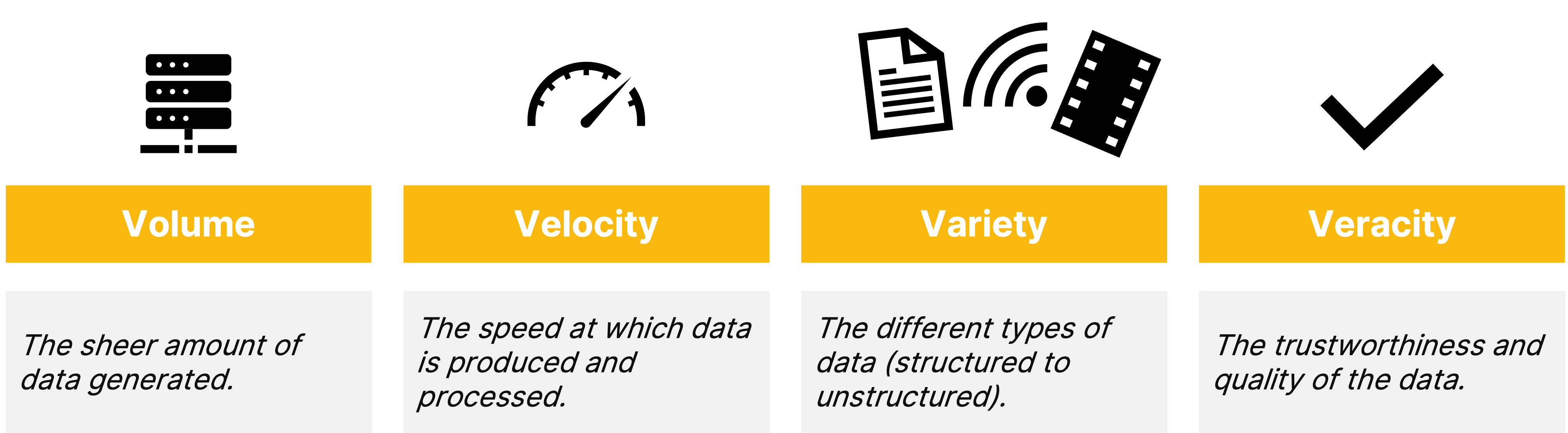
To handle the increasing volume, variety, and velocity of data—generated from connected devices, applications, websites, e-commerce, AI, and more, Data Lakes and Data Lakehouses have become essential to modern data architectures. These systems are designed not only to store, process, and analyze vast amounts of diverse data but also need to ensure the accuracy and reliability of that data (veracity). Balancing these four key aspects - also referred to as the 4 Vs of data - is essential for organizations keep up with the rapid pace of data generation, ensuring they can derive meaningful, trustworthy insights efficiently.
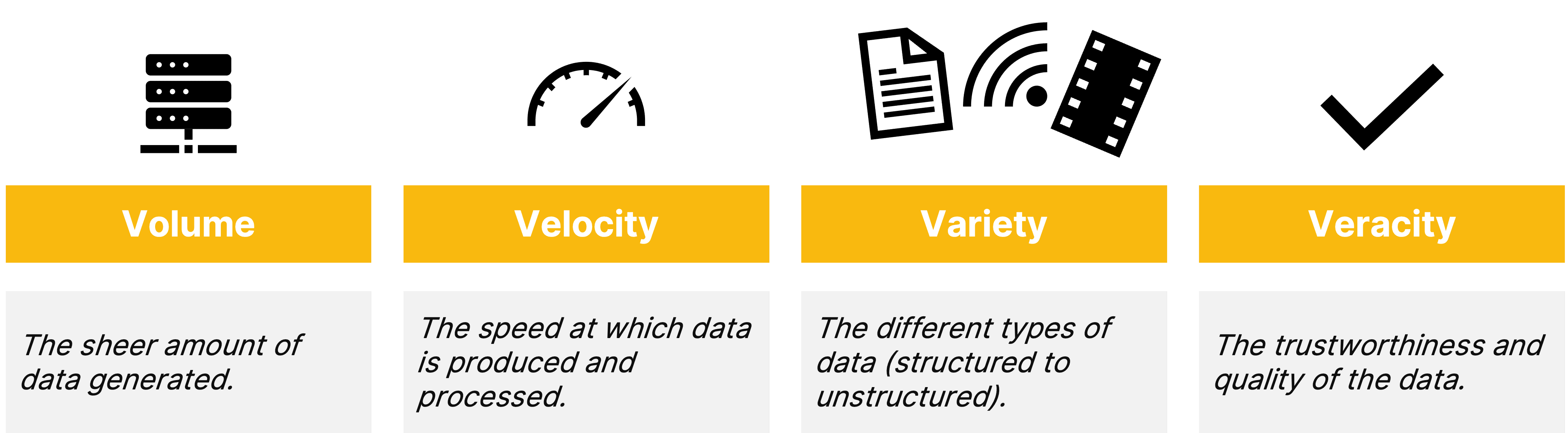 🔍 Click to enlarge image4 Vs of Data, inspired by Doug Laney (2001)2
🔍 Click to enlarge image4 Vs of Data, inspired by Doug Laney (2001)2
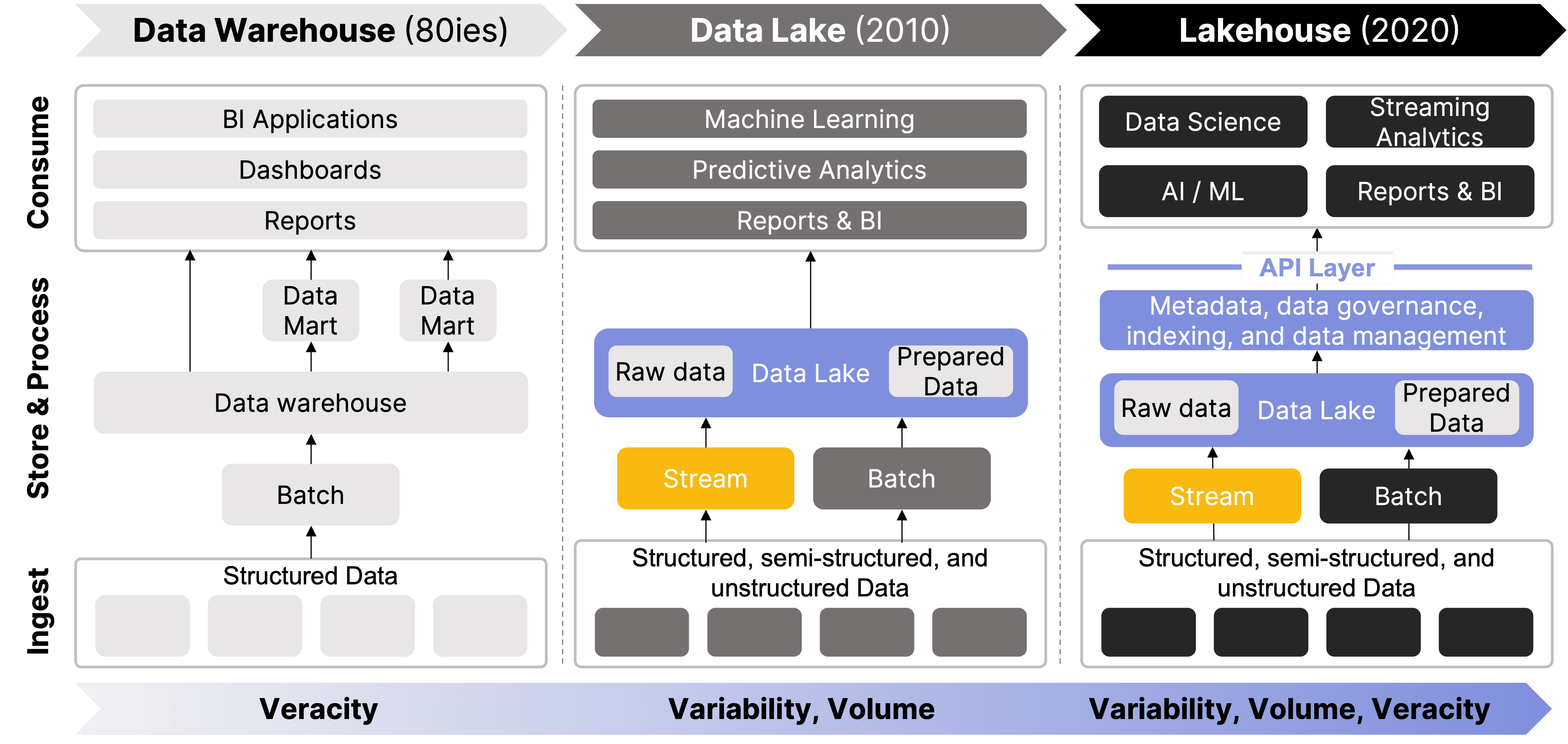
From Data Warehouse to Data Lakehouse: The Evolution
For many years, the data warehouse served as the cornerstone of enterprise data management, optimized for structured, trustworthy data and supporting business intelligence. However, as data generation surged, with diverse data types from logs, images, and IoT devices, warehouses struggled with their rigid schemas. While they excel in querying structured datasets, they struggle to keep pace with the growing volume and complexity of modern data streams, necessitating a more flexible solution.
The concept of the data lake emerged just over a decade ago as organizations grappled with the challenges of big data—managing and analyzing vast amounts of diverse information generated in the digital age. In 2010, James Dixon, then CTO at Pentaho, coined the term "data lake" to describe a centralized repository that allows for storing all structured and unstructured data at any scale. He likened data marts and warehouses to bottled water—clean and packaged for easy consumption—while a data lake is akin to a natural body of water, where data flows in its raw, native format and can be accessed and explored as needed.3
The widespread adoption of Hadoop and cloud storage solutions accelerated the move to data lakes by providing scalable, cost-effective platforms for storing and processing large volumes of data. However, as most data teams discovered, without proper data governance, data lakes risked becoming disorganized "data swamps" filled with redundant or irrelevant information. This challenge led to an evolution in data lake architecture, incorporating metadata management, data cataloging, and governance frameworks to restore data quality and veracity.
Eventually, this progression gave rise to the data lakehouse architecture, which combines the flexible storage of data lakes with the data management and performance features of data warehouses.
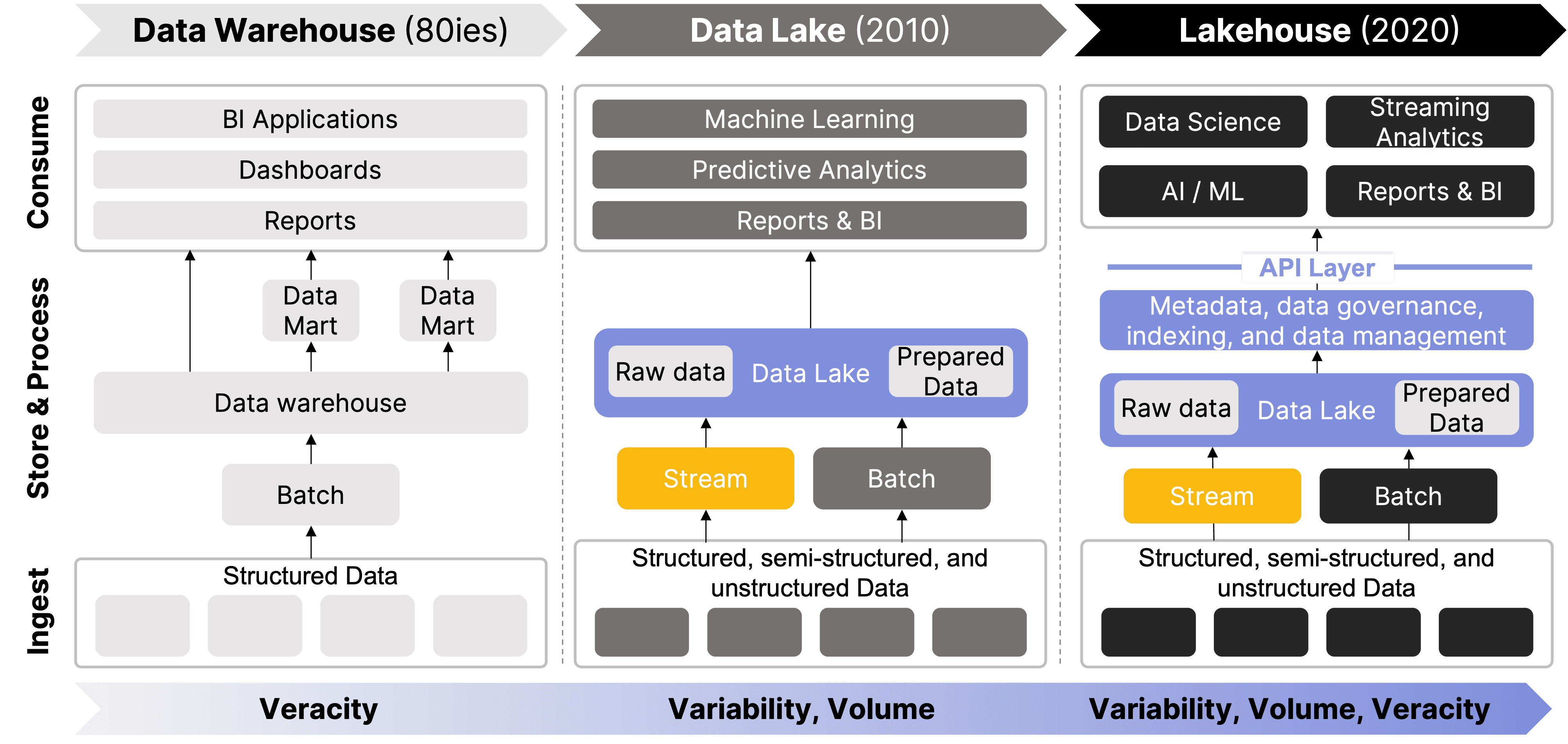 🔍 Click to enlarge imageEvolution from Data Warehouse to Lakehouse4
🔍 Click to enlarge imageEvolution from Data Warehouse to Lakehouse4
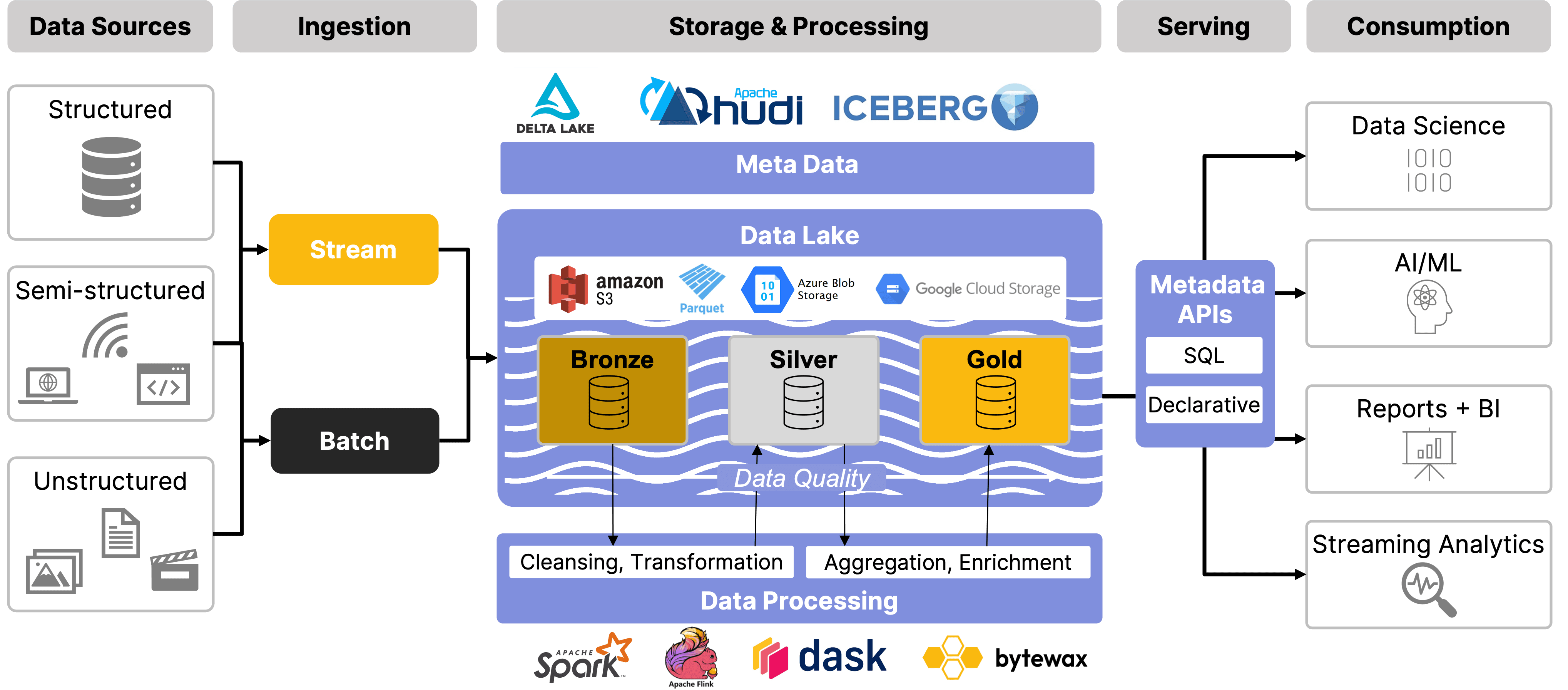
A Closer Look at the Data Lakehouse
The Data Lakehouse aims to provide a unified platform for both advanced analytics and business intelligence workloads, making data more accessible and reliable across organizations.
Let’s look at the architectural features of a data lakehouse, combining the strong data management and governance capabilities of a data warehouse with the scalability and flexibility of a data lake, to offer a cost-effective solution for managing both structured and unstructured data.
Data Lakehouses allow the ingestion of data from multiple sources in structured and unstructured formats, whether it’s real-time streams or batch loads. Once ingested, data moves into the storage and processing layer, which is organized into bronze, silver, and gold tiers. These are the "medallions", commonly referred to in the medallion architecture. These tiers help manage data from raw (bronze) to cleansed and transformed (silver), to enriched and ready for analytics (gold). Throughout this process, governance is enforced with metadata management, schema evolution, and data quality checks, ensuring compliance and control. Finally, the serving layer provides easy access to data through APIs, with access control to safeguard sensitive data.
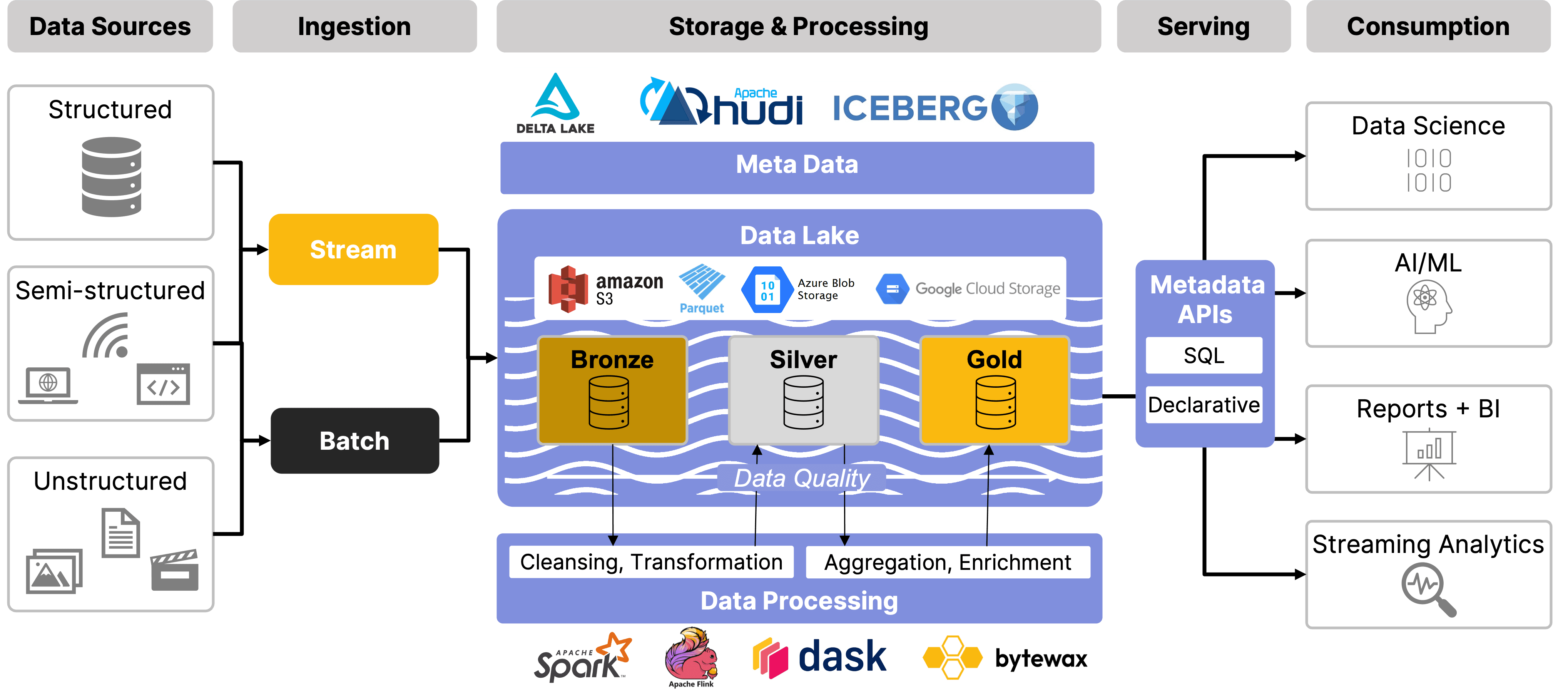 🔍 Click to enlarge imageData Lakehouse Components
🔍 Click to enlarge imageData Lakehouse Components
Leading Data Lake (house) Solutions
Below is a summary of the most prominent data lakes and lakehouse solutions available today. This is not an exhaustive list, but only includes the most commonly used solutions today.
| Solution | Type | Underlying Storage | ACID Transactions | Query Engine Support | Cloud Integration | Data Format Support |
|---|---|---|---|---|---|---|
| Amazon S3 | Data Lake | Object Storage | No | Amazon Athena, EMR | AWS | Any |
| Azure Data Lake Storage | Data Lake | Object Storage | No | Azure Synapse Analytics | Microsoft Azure | Any |
| Google Cloud Storage | Data Lake | Object Storage | No | BigQuery, Dataproc | Google Cloud Platform | Any |
| Databricks Lakehouse | Data Lakehouse | Object Storage (Various) | Yes | Databricks SQL Analytics | AWS, Azure, GCP | Parquet, Delta |
| Delta Lake | Data Lakehouse | Object Storage | Yes | Apache Spark | Multiple Cloud Providers | Parquet, Delta |
| Apache Hudi | Data Lakehouse | Object Storage | Yes | Apache Spark, Presto, Hive | Multiple Cloud Providers | Parquet, Avro, ORC |
| Apache Iceberg | Data Lakehouse | Object Storage | Yes | Apache Spark, Trino, Flink | Multiple Cloud Providers | Parquet, Avro, ORC |
| Snowflake | Data Lakehouse | Proprietary Cloud Storage | Yes | Snowflake SQL | Snowflake Cloud Platform | Structured, Semi-structured |
| Amazon Redshift Spectrum | Data Lakehouse | Amazon S3 | Yes | Amazon Redshift SQL | AWS | Any |
| Google BigQuery | Data Lakehouse | Columnar Storage | Yes | BigQuery SQL | Google Cloud Platform | CSV, JSON, Avro, Parquet |
| Dremio | Data Lakehouse | Object Storage | Yes | Dremio SQL, Apache Arrow | Multiple Cloud Providers | Parquet, ORC, Avro |
| Hopsworks | Data Lakehouse | Object Storage | Yes | Apache Spark, Trino, Presto | Multiple Cloud Providers | Parquet, ORC, Avro, CSV |
Challenges for Real-time Workloads in Data Lakehouses
Data lakehouses are not yet fully real-time like dedicated streaming platforms. While significant progress has been made in integrating real-time data ingestion and processing, challenges remain in achieving true real-time performance across the entire architecture—essentially, they still fall short on the final “V” of the 4Vs: velocity. Most data lakehouses can manage a combination of batch and micro-batch processing but rely on additional components such as stream processing engines and message brokers to handle real-time data ingestion and processing. Some modern data lakes now offer the option to use streaming engines as part of the architecture, but full real-time integration is still evolving.
Some of the limitations include higher latency compared to stream-first systems, complexities around integrating real-time and historical data processing, and potential inefficiencies in managing continuous data updates within the storage layer, which is often optimized for larger batch operations.
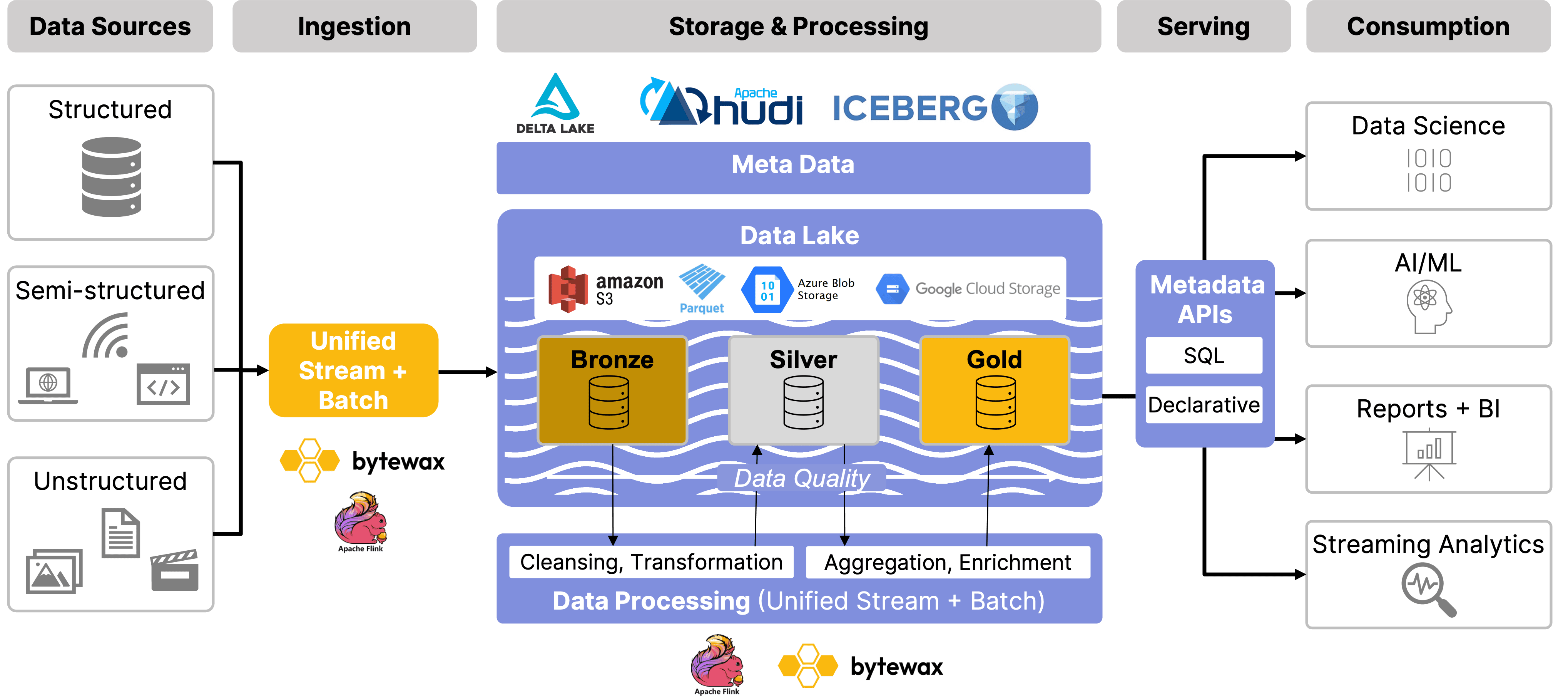
Adding Velocity: The Shift to Real-Time in Lakehouses
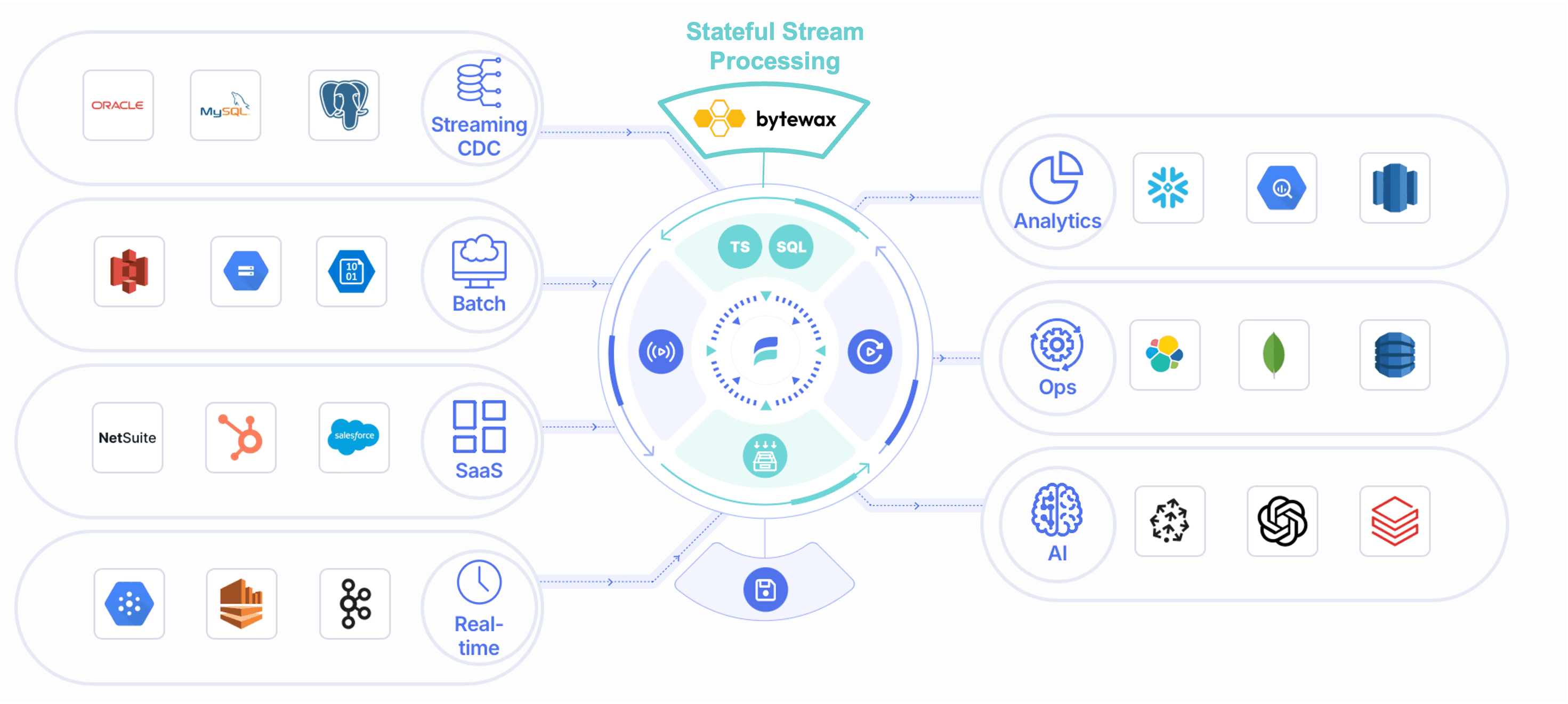
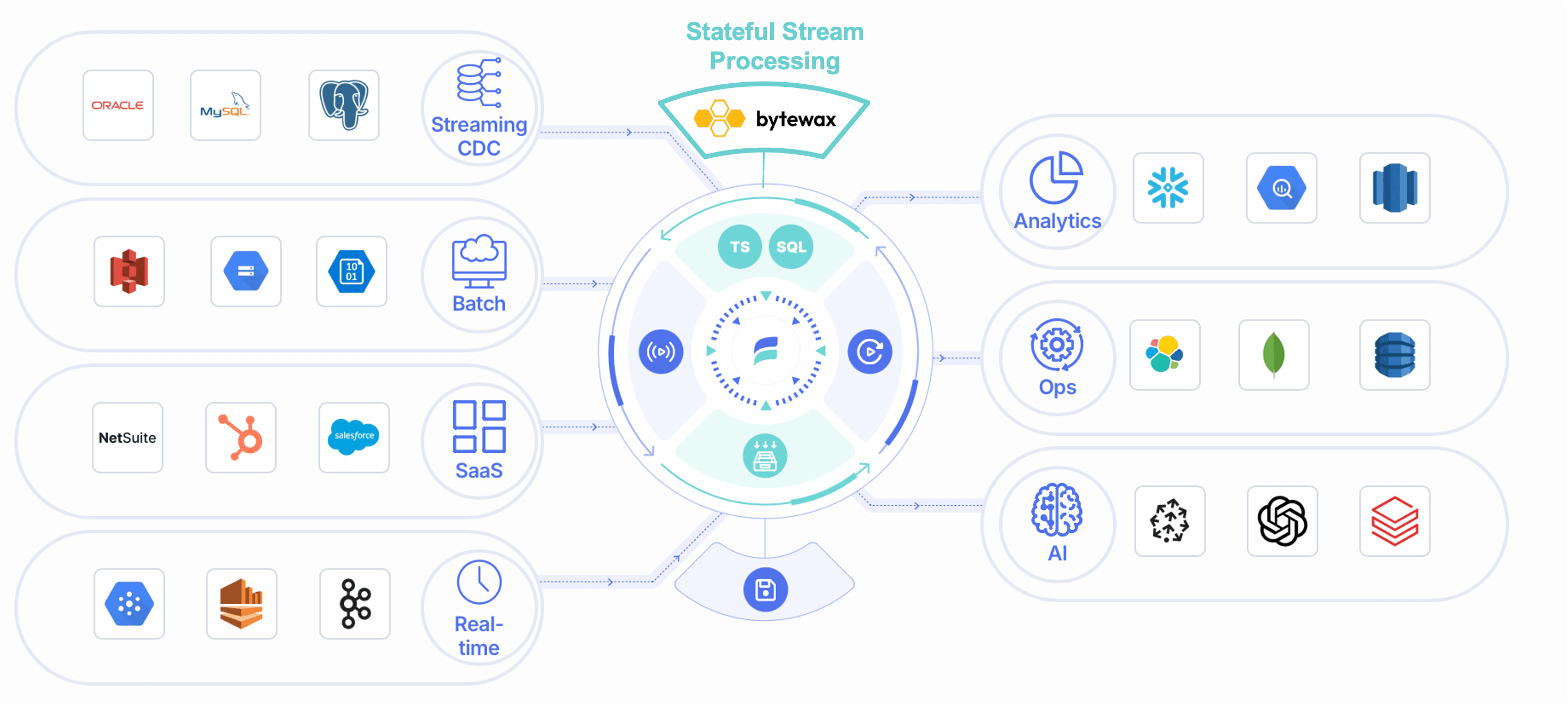
As there is a shift to derive real-time insights from data and operationalize and automate decision making, the role of streaming and stream processing in data lakehouse architectures is becoming more important. Traditional data lakehouses are primarily batch-oriented, relying on periodic processing of data, but real-time streaming capabilities are essential for use cases requiring instant decision-making. By integrating scalable stateful stream processors—like Flink or Bytewax—that can handle both batch and real-time streaming data, the tradeoff between batch and streaming is increasingly disappearing. Stateful stream processing enhances the lakehouse’s flexibility, enabling it to seamlessly handle both types of data with greater speed and efficiency.
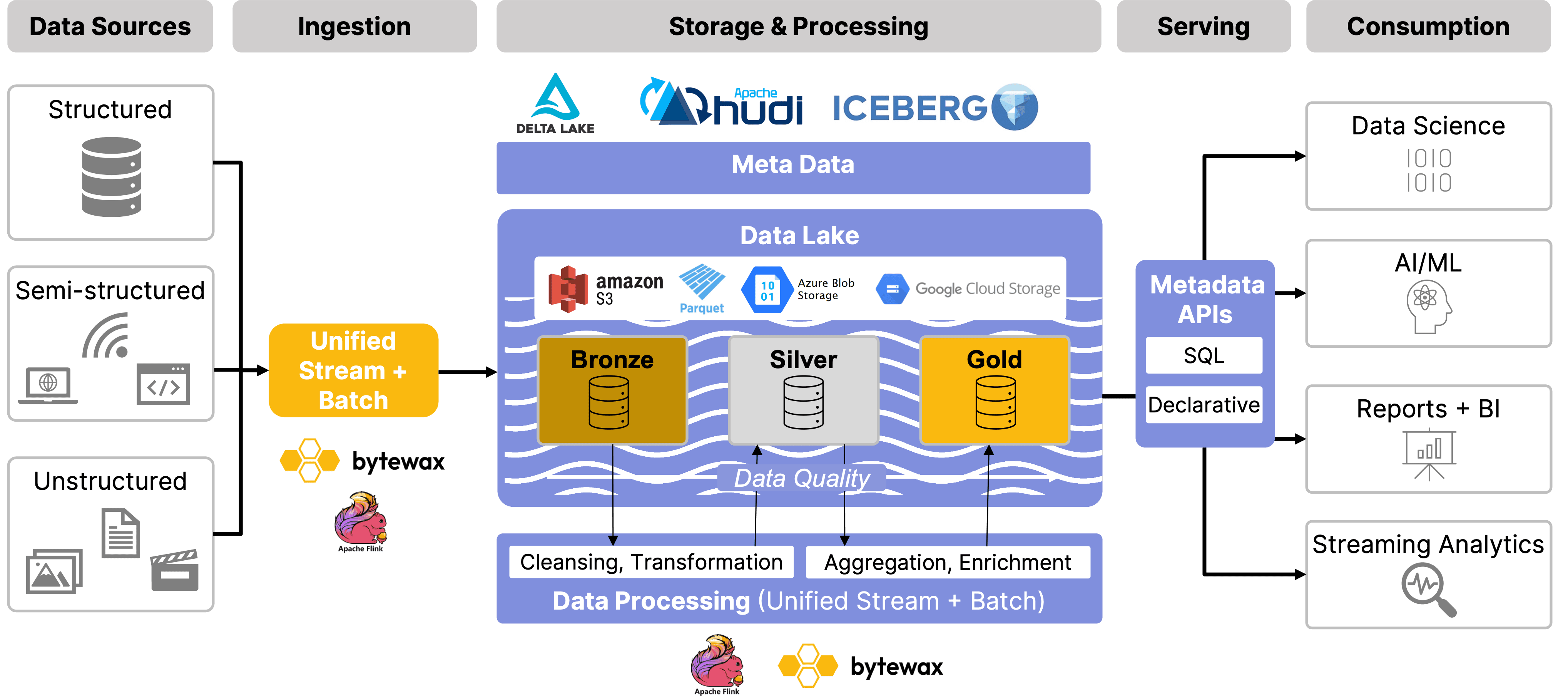 🔍 Click to enlarge imageStreaming Data Lakehouse Architecture
🔍 Click to enlarge imageStreaming Data Lakehouse Architecture
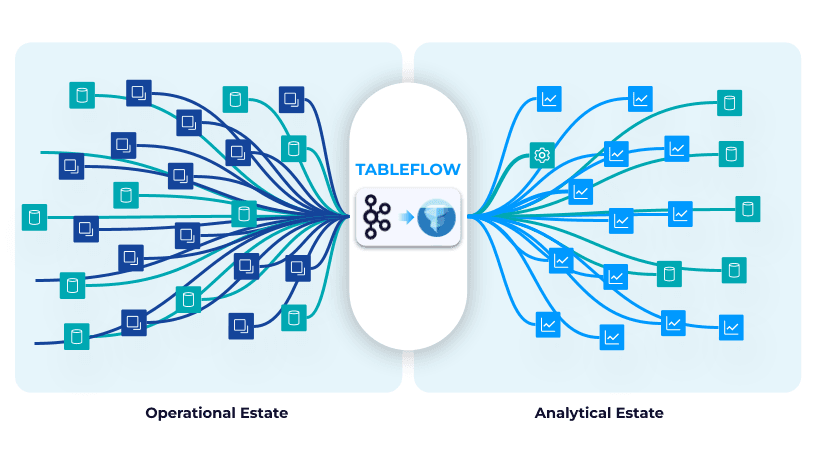
Newer developments are pushing the boundaries to make the data lakehouse truly real-time and unify the data interface regardless of whether you are querying streaming or at-rest data. The recent launch of Confluent's Tableflow and Redpanda’s Iceberg Topics marked the start of the streaming shift to the data lakehouse. Since streaming platforms are most often the source for streaming data it makes sense for streaming platforms to add the functionality of a data lake by transposing topics to columnar oriented and cataloged tables.
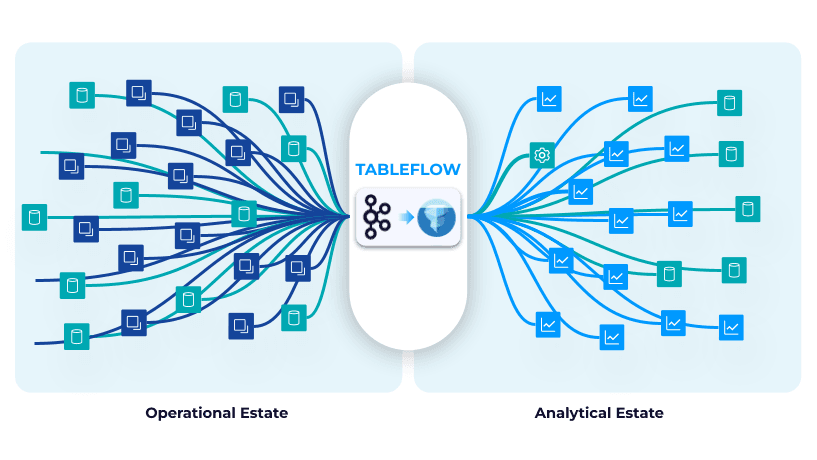 🔍 Click to enlarge imageConfluent's Table Flow
🔍 Click to enlarge imageConfluent's Table Flow
Another interesting recent development in this space is the Apache Paimon project that evolved out of an effort to make dynamic tables in Flink queryable. This project aims to deliver a streaming data lakehouse solution, aiming to unify batch and streaming data processing. Apache Paimon addresses the challenges of real-time data ingestion and querying by enabling consistent and low-latency access to data stored in data lakes. Simply put, Paimon brings the storage layer to Flink.
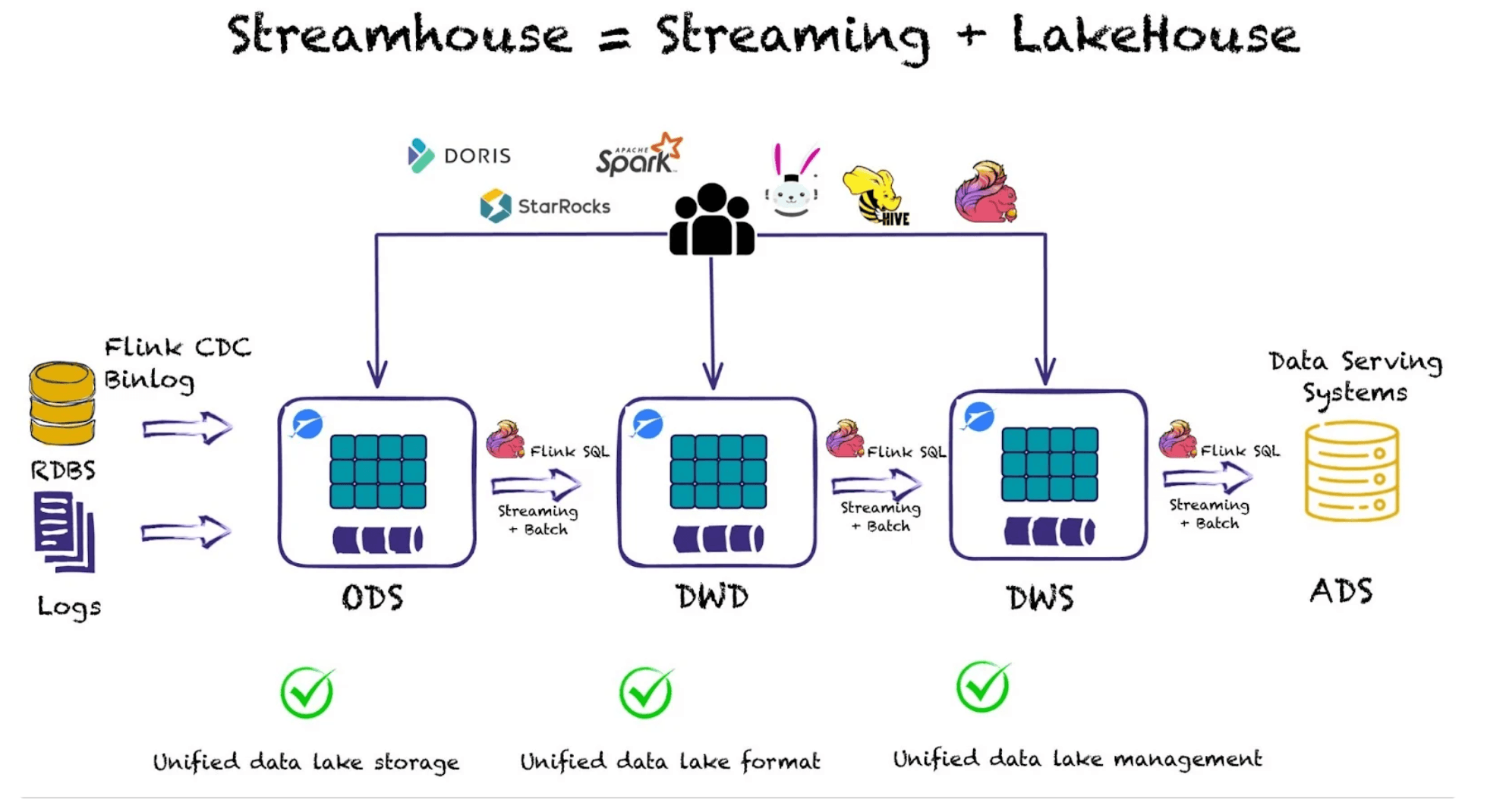
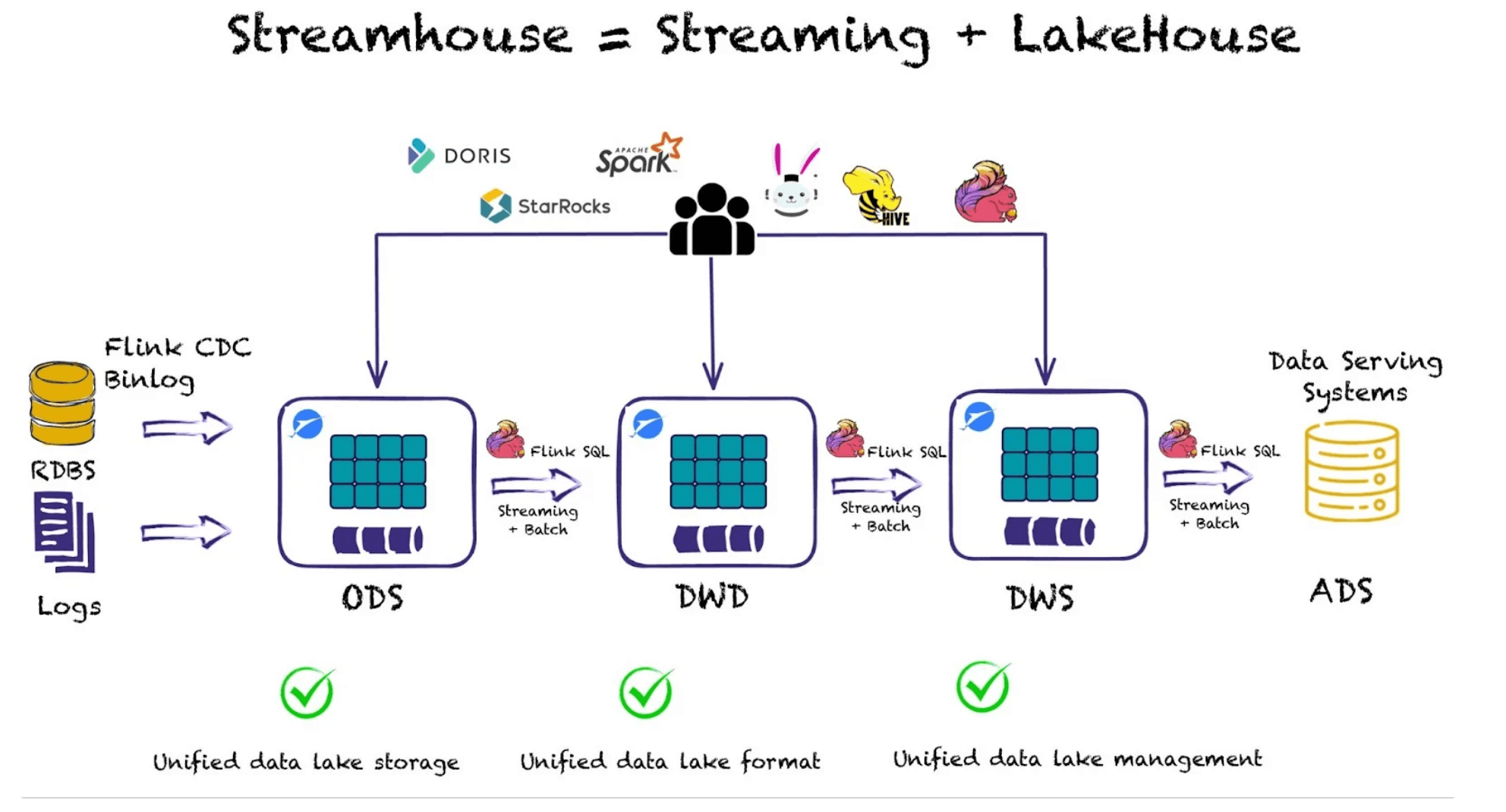 🔍 Click to enlarge imageThe Streamhouse: Ververica's Take on a Streaming Data Lakehouse
🔍 Click to enlarge imageThe Streamhouse: Ververica's Take on a Streaming Data Lakehouse
Additionally, platforms like Estuary are pushing forward the streaming data lakehouse paradigm by offering products like Flow that allow real-time data ingestion, transformation, and even storage to some extent. When married with a stateful stream processor like Bytewax, this provides a really unique take on how you can reduce your analytics stack with new simple to use tooling.
Estuary Flow with Bytewax as Stream Processor
Conclusion
The Data Lakehouse has emerged as a robust architecture for managing diverse data workloads. However, as the shift toward real-time processing accelerates, there is a growing need to extend lakehouse capabilities by integrating real-time processing, storage, and analytics into a unified solution.
This presents a significant opportunity for streaming platforms to simplify data pipelines by eliminating the need for additional downstream data vendors. By providing the storage, catalog, and compute layers through open-source protocols, streaming platforms can offer a more cohesive and efficient solution.
With various architectural approaches and products competing to define the future of the Streaming Data Lakehouse, the future will likely see more convergence between streaming technologies and data lakehouses, bringing real-time capabilities to the forefront of data architecture.
Footnotes
Do Python's Rust: Reaching into Rust to Create a Better Python Library

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}