
Target Audience: Data Scientists
Introduction
In part 1: Foundational Concepts for Stream Data Processing of this series, we broke down some of the foundational concepts of stream data processing. This time, we will explore windowing and sessionization, two fundamental aspects that enable us to manage and interpret streams of data over time.
Learning Overview
If you are new to this series, our aim is to teach you all of the concepts and tools you need to know to build real-time data pipelines entirely in Python. Most of this series will be taught using the Bytewax library, our open-source Python library for stream processing.
No previous experience with streaming data, the Bytewax library, or other languages (like Java) is necessary to thrive in this series. This hands-on tutorial is split into 4 parts:
- Part I: Foundational Concepts for Stream Data Processing
- Part II: Controlling Time with Windowing & Sessionization
- Part III: Joining Streams
- Part IV: Real-time Machine Learning
Understanding Windowing
What is Windowing?
Windowing is a technique used in stream processing to divide the continuous flow of data into manageable, discrete segments called windows.
These windows allow practitioners to perform calculations on data that arrives in real-time over specified intervals. Within a window you can collect data into an object or reduce it into a single item per window.
For example we could return a distinct set of users for every 5 minutes or we could count the unique users. Windowing is crucial for tasks such as computing aggregate statistics, defining machine learning model features or applying machine learning models in real-time scenarios.
Windows can be broken down into three groups:
- Tumbling Windows: These are fixed-sized, non-overlapping windows that reset after each interval. For example, a five-minute tumbling window processes data in five-minute chunks.

- Sliding Windows: These windows overlap with each other, where each new window slides over the data stream by a specified interval. This type is useful for moving average calculations.
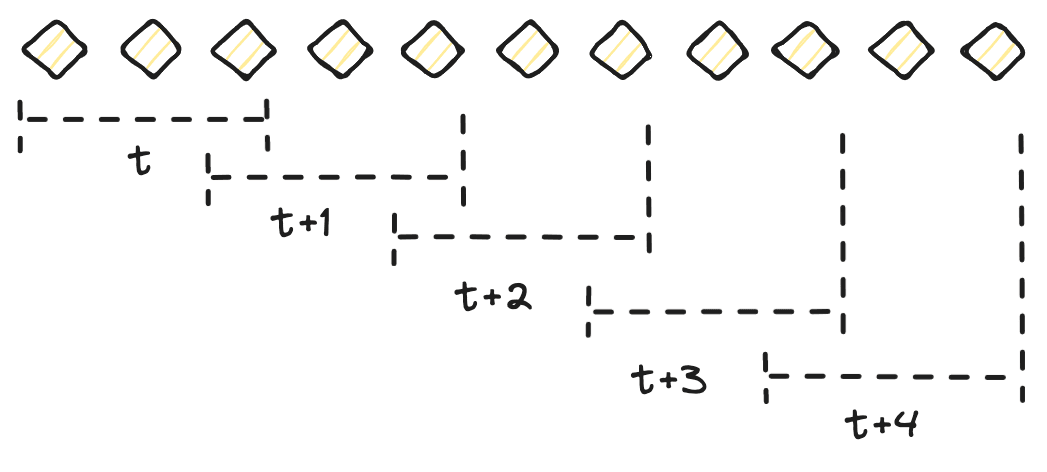
- Session Windows: These are dynamically sized based on the activity of the data stream. A session window extends as long as the activity (events or data points) continues and closes after a timeout period of inactivity.
Time in Windows
Time is an important concept in Windows because you must understand if the current system time will be used to set the window's boundaries or the event time. The system time refers to the time the data is being processed, equivalent to time.time() in Python, whereas the event time is when the event occurred, which most likely is in the past, even if only a few milliseconds. The difference between the system and event time can vary drastically and result in very different outcomes.
Late Arriving Data
Another important concept in windowing is how to handle late-arriving data. Let's say we receive an event just outside of our window that should have been caught in the window. How do we process it? Do we drop it on the floor?
Most systems have some ability to handle late arriving data. The simplest way to understand how this works is imagine holding the events for some amount of extra time (usually system time) and only then, ensuring you have the right events and passing those downstream. This has a lot of implications in the latency of a system because of that extra wait.
Practical Application with Bytewax
Let's apply these concepts using the Bytewax library to demonstrate how windowing can be implemented in a data streaming application.
Tumbling Window Example
Suppose we want to calculate the sum of numbers in our data stream every minute. Here's how we can set up a tumbling window using the system time in Bytewax:
import bytewax.operators as op
import bytewax.operators.windowing as win
# pip install aiohttp-sse-client
from bytewax.dataflow import Dataflow
from bytewax.operators.windowing import SystemClock, TumblingWindower
flow = Dataflow("window")
inp = op.input("inp", flow, TestingSource([i for i in range(100)]))
server_counts = win.count_window(
"count",
inp,
SystemClock(),
TumblingWindower(
length=timedelta(seconds=0.1), align_to=datetime(2023, 1, 1, tzinfo=timezone.utc)
),
get_server_name,
)
op.inspect("output", server_counts)
This example initializes a Dataflow object, applies a tumbling window based on system time to sum the numbers every tenth of a second, and outputs the results.
This example is quite trivial but illustrates how we can reduce over a time-based window.
Sliding Window Implementation
Following the tumbling window example, similar steps can be followed to implement sliding windows. Adjust the Windower type in the count_window method and modify parameters according to the sliding window logic.
Session Windows and Sessionization
What is Sessionization?
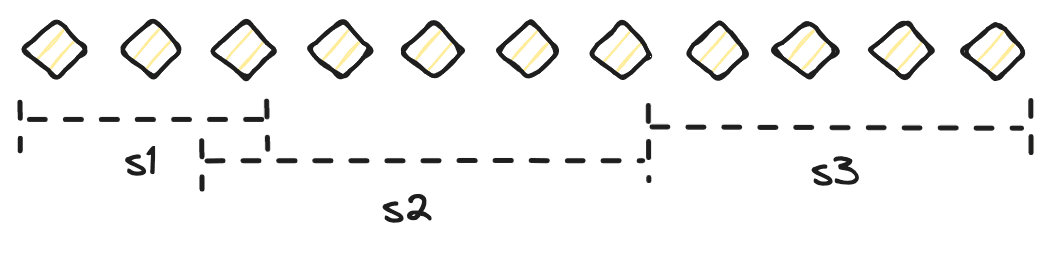
Sessionization groups a series of events into sessions based on the activity of an entity, often used to analyze user behavior patterns or determine the start and end of an interaction or activity. It is especially useful in scenarios where activity duration and frequency are important, such as web analytics and e-commerce, but can be applied to many areas like logistics, manufacturing, cybersecurity and more.
A session window is the window implementation of a session. Events that occur in the stream are used to trigger the start and end of a window instead of just time. Session windows can be hetergeneous with respect to time.
We usually use a timeout to close a session to prevent it from continuing indefinitely.
Implementing Sessionization with Bytewax
Let's use a search session as an example to understand better how the session window will work. This is a common use case for analyzing the effectiveness of the search results.
When a user visits our app, we signal an app session started, then they use the search functionality, we could signal that a search session has started. after entering a search, they click through a successive number of links and then log off. Or, maybe they leave the app open or engage in content for a long enough duration that we want to stop counting towards the current search session even though the app session hasn't ended.
Here's how you might implement this in Bytewax:
import operator
from dataclasses import dataclass
from datetime import datetime, timedelta, timezone
from typing import List
from bytewax import operators as op
from bytewax.connectors.stdio import StdOutSink
from bytewax.dataflow import Dataflow
from bytewax.operators import windowing as win
from bytewax.operators.windowing import EventClock, SessionWindower
from bytewax.testing import TestingSource
@dataclass
class Event:
user: int
dt: datetime
@dataclass
class AppOpen(Event): ...
@dataclass
class Search(Event):
query: str
@dataclass
class Results(Event):
items: List[str]
@dataclass
class ClickResult(Event):
item: str
@dataclass
class AppClose(Event): ...
@dataclass
class Timeout(Event): ...
start = datetime(2023, 1, 1, tzinfo=timezone.utc)
def after(seconds):
return start + timedelta(seconds=seconds)
IMAGINE_THESE_EVENTS_STREAM_FROM_CLIENTS = [
AppOpen(user=1, dt=start),
Search(user=1, query="dogs", dt=after(1)),
Results(user=1, items=["fido", "rover", "buddy"], dt=after(2)),
ClickResult(user=1, item="rover", dt=after(3)),
Search(user=1, query="cats", dt=after(4)),
Results(user=1, items=["fluffy", "burrito", "kathy"], dt=after(5)),
ClickResult(user=1, item="fluffy", dt=after(6)),
AppOpen(user=2, dt=after(7)),
ClickResult(user=1, item="kathy", dt=after(8)),
Search(user=2, query="fruit", dt=after(9)),
AppClose(user=1, dt=after(10)),
AppClose(user=2, dt=after(11)),
]
def is_search(event):
return type(event).__name__ == "Search"
def remove_key(user_event):
user, event = user_event
return event
def has_search(session):
return any(is_search(event) for event in session)
# From a list of events in a user session, split by Search() and
# return a list of search sessions.
def split_into_searches(wm__user_session):
user_session = wm__user_session[1]
search_session = []
for event in user_session:
if is_search(event):
yield search_session
search_session = []
search_session.append(event)
yield search_session
def calc_ctr(search_session):
if any(type(event).__name__ == "ClickResult" for event in search_session):
return 1.0
else:
return 0.0
flow = Dataflow("search session")
stream = op.input("inp", flow, TestingSource(IMAGINE_THESE_EVENTS_STREAM_FROM_CLIENTS))
# event
initial_session_stream = op.map("initial_session", stream, lambda e: [e])
keyed_stream = op.key_on("add_key", initial_session_stream, lambda e: str(e[0].user))
# (user, [event])
window = SessionWindower(gap=timedelta(seconds=5))
session_stream = win.reduce_window(
"sessionizer",
keyed_stream,
EventClock(lambda x: x[-1].dt, timedelta(seconds=10)),
window,
operator.add,
)
# (user, [event, ...])
event_stream = op.map("remove_key", session_stream.down, remove_key)
# [event, ...]
# Take a user session and split it up into a search session, one per
# search.
event_stream = op.flat_map(
"split_into_searches", event_stream, lambda x: list(split_into_searches(x))
)
event_stream = op.filter("filter_search", event_stream, has_search)
# Calculate search CTR per search.
ctr_stream = op.map("calc_ctr", event_stream, calc_ctr)
op.output("out", ctr_stream, StdOutSink())
This mock sessionization takes app events and windows them into a user session. It will return all the session events in the window, which we can then split into search events and calulate the click through rate for the session, a common metric used for the effectiveness of the results.
Conclusion
Windows is a powerful technique that enables more conrete analysis of streaming data by creating discrete operable batches of data out of a continuous stream. By mastering these concepts, data scientists can extract meaningful insights from streaming data, ultimately enhancing decision-making processes in dynamic environments.
Stay tuned for Part 3, where we will explore how to join multiple streams to enrich data and provide more comprehensive insights.
💛 We hope this series part helps deepen your understanding of stream data processing. For more practical examples and guides, check out the Bytewax documentation. If you have questions or feedback, join our community on Slack or email us!
Bytewax at PyData London: Engaging the Python and Data Communities

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

