
Introduction
Retrieval-Augmented Generation (RAG) is a method in natural language processing (NLP) that combines generative AI, such as large language models (LLMs), with the capability to extract relevant information from a knowledge base. This combination allows RAG to generate content that is not only nuanced but also grounded in factual data.
By leveraging a vast repository of information, RAG aims to produce responses that are both accurate and contextually relevant.
One of the interesting applications of RAG lies in situations where the data the LLM uses to generate content changes in real-time.
In this blog, we will explore how to model RAG through directed graphs and leverage the open-source ecosystem to build RAG systems whose data can be updated in real-time.
This blog is based on the presentation below ⬇️
Understanding RAG
The primary purpose of RAG is to enhance the accuracy and contextual relevance of AI-generated responses.
Traditional generative models often struggle with producing factually accurate content, as they rely solely on the data they were trained on. RAG addresses this limitation by incorporating real-time information retrieval, ensuring that the generated content is both up-to-date and pertinent to the user's query.
Significance in the AI Landscape
RAG represents a significant advancement in the field of artificial intelligence. It enhances the capabilities of AI systems by providing access to extensive external knowledge bases, which can include the latest information and a wide array of data sources. This integration results in AI-generated responses that are not only more accurate but also more relevant to the specific context of the query. Consequently, RAG improves the overall quality and reliability of AI interactions, making it a valuable tool in various applications.
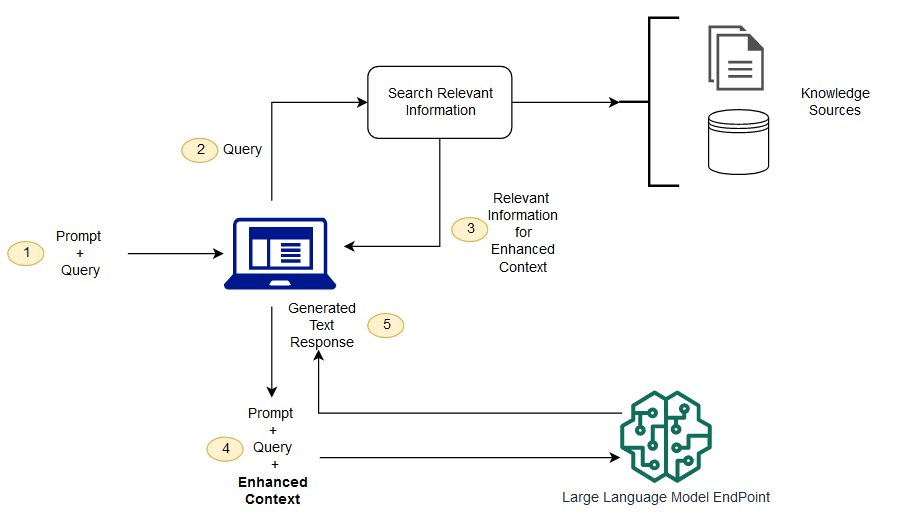
Source: Retrieval Augmented Generation (AWS)
Use Cases and Benefits of RAG
RAG's versatility makes it suitable for a wide range of applications. Some of the prominent use cases include:
- Customer Support: RAG can provide precise and relevant answers to customer inquiries, improving the efficiency and satisfaction of customer support interactions.
- Education: In educational settings, RAG can assist in generating accurate and contextually appropriate content for learning materials and tutoring systems.
- Healthcare: RAG can be utilized to retrieve and present the latest medical information, supporting healthcare professionals in making informed decisions and providing better patient care.
- Content Creation: For content creators, RAG can generate articles, reports, and other written materials that are well-researched and grounded in factual data.
The benefits of RAG are manifold:
- Accuracy: By retrieving and utilizing the most relevant information, RAG ensures that the content generated is factually correct.
- Relevance: The ability to provide contextually appropriate responses enhances the user experience and the usefulness of the AI system.
- Efficiency: RAG streamlines the process of content generation by quickly accessing and incorporating necessary information.
- Scalability: RAG systems can be scaled to handle large volumes of queries and data, making them suitable for a variety of industries and applications.
Introduction to data flow and directed graphs (DG)
Data flow refers to the movement of data through a system or process, often visualized as a series of steps where data is processed, transformed, and transferred. This concept is essential for understanding how data is managed and manipulated within various systems, ensuring that data moves smoothly from one point to another, undergoing necessary transformations along the way.
Role in Processing Pipelines
In processing pipelines, data flow plays a crucial role by defining the sequence and dependencies of data processing tasks. It ensures that each task is executed in the correct order, with the necessary data inputs, thereby maintaining the efficiency and orderliness of the entire process. This structured approach helps prevent errors and inefficiencies, making sure that data processing is both effective and reliable.
Significance
Understanding data flow is significant for several reasons.
-> It provides clarity on how data transformations occur and what dependencies exist between different tasks. This clarity is vital for optimizing data processing systems and troubleshooting any issues that may arise.
-> By having a clear visualization of the data flow, it becomes easier to identify and address inefficiencies, ensuring that the system operates at its best.
Introduction to Directed Graphs (DGs) and Their Properties
Directed graphs (DGs) are a set of nodes connected by directed edges, where each edge has a specific direction from one node to another. These graphs are commonly used to model relationships and processes in various fields, such as computer science, engineering, and network analysis. The directionality of the edges in DGs allows for precise modeling of processes where the order of operations is crucial.
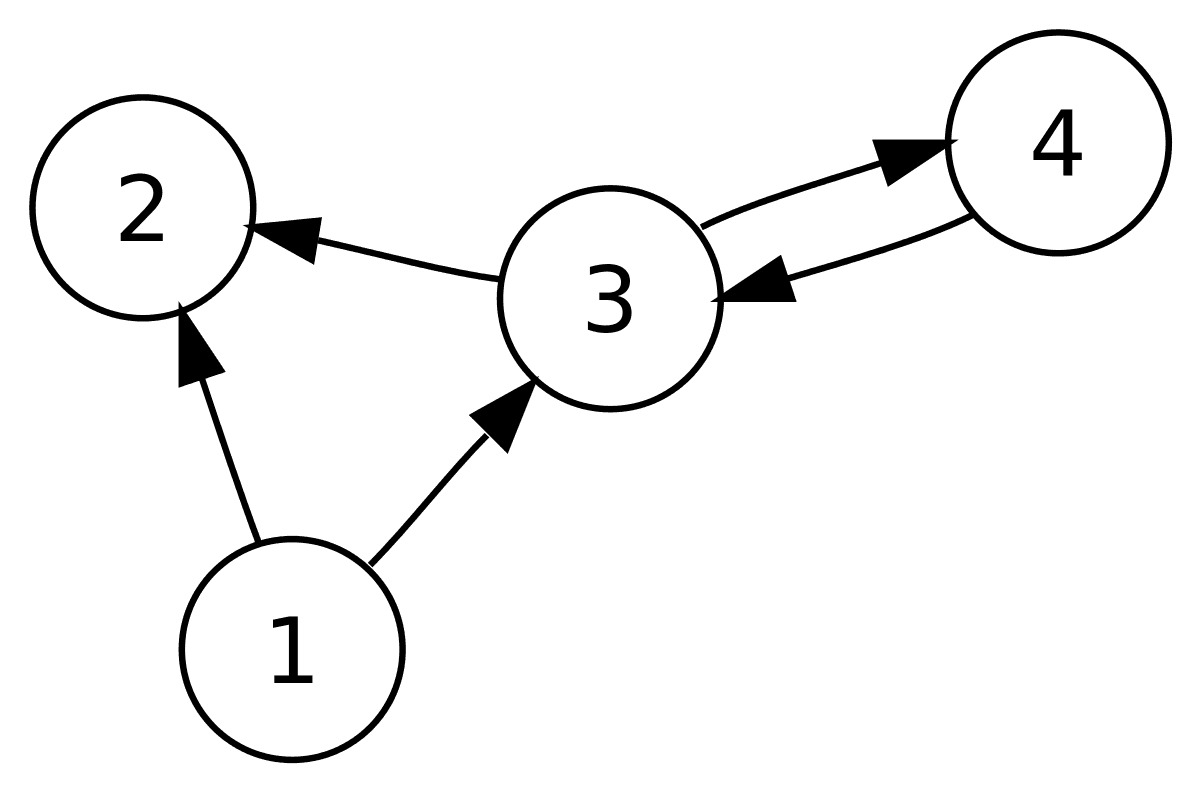 Sample directed graph. Source: Wikipedia
Sample directed graph. Source: Wikipedia
Properties of Directed Graphs
Directed graphs have several key properties:
- Nodes and Edges: Nodes represent the entities or data points, and edges represent the relationships or dependencies between these nodes.
- Path: A sequence of edges that connect a series of nodes.
- Cycle: A path that starts and ends at the same node, indicating a potential loop in the process.
Importance
Directed graphs are important because they help in visualizing and understanding complex systems. By representing systems as DGs, it becomes easier to see the interactions and dependencies between different components. This visualization aids in the design and analysis of data processing pipelines, making it simpler to identify potential issues and optimize the system.
Why Model Problems as Directed Graphs?
Modeling problems as directed graphs enhance the clarity and manageability of processing pipelines. DGs allow for the identification of parallelism opportunities, where multiple tasks can be processed simultaneously, and potential bottlenecks that could slow down the system. By understanding these aspects, it becomes possible to optimize the data flow, improving the overall efficiency and performance of the system.
In summary, the concepts of data flow and directed graphs are fundamental for designing, analyzing, and optimizing data processing systems. They provide a clear framework for understanding the movement and transformation of data, ensuring that systems are efficient, reliable, and capable of handling complex tasks effectively.

Examples of Data Processing Frameworks that leverage DGs and DAGs
Modelling RAG as a Directed Graph (DG)
Retrieval-Augmented Generation (RAG) can be effectively modeled as a Directed Graph (DG) to illustrate the key processes and their interdependencies. By visualizing RAG in this way, we gain a clearer understanding of how data flows through the system, from initial extraction to final response generation.
Key Processes in RAG
- Data Extraction
Data extraction is the first step in the RAG process, involving the retrieval of raw data from various sources. This step is crucial for gathering the necessary information that will be processed and utilized in subsequent stages. In the context of a DG, data extraction nodes represent the entry points where data is initially collected.
- Data Wrangling and Pre-processing
Once the data is extracted, it undergoes wrangling and pre-processing. This step involves cleaning, transforming, and organizing the raw data into a structured format suitable for further processing. In a DG, this stage is represented by nodes where data is manipulated to ensure it is accurate and ready for indexing.
- Data Indexing
Data indexing follows pre-processing and involves creating indexes for efficient data retrieval. This step is essential for organizing the processed data in a way that allows for quick and accurate access. In a DG, indexing nodes denote the points where data is systematically cataloged, facilitating faster retrieval in later stages.
- Data Retrieval
Data retrieval is the process of accessing the indexed data based on specific queries or requirements. This step is critical for obtaining the relevant information needed to generate responses. In a DG, retrieval nodes are the points where the system queries the indexed data to fetch the necessary details.
- Response Generation with an LLM
The final step in the RAG process is response generation using a Large Language Model (LLM). This step involves taking the retrieved data and using the LLM to generate coherent and contextually appropriate responses. In a DG, response generation nodes represent the culmination of the process, where the final output is produced based on the gathered and processed information.
Modeling RAG as a Directed Graph provides a structured and clear framework for understanding the intricate processes involved in data extraction, processing, and response generation. This approach not only enhances clarity but also facilitates the optimization and efficient management of RAG systems.
Building real-time RAG with Bytewax and Haystack
Introduction to Haystack and Bytewax
Haystack:
Haystack is an open-source framework designed for building sophisticated search systems that support retrieval-augmented generation (RAG). It provides a suite of tools for document retrieval, question answering, and information extraction, making it a powerful solution for developing advanced search capabilities.
Installation and Configuration:
To get started with Haystack, you can install it using pip:
pip install haystack-ai
Haystack's architecture is built around several core building blocks, including data structures, document stores, components, and pipelines. These elements work together to create a seamless and efficient search experience.
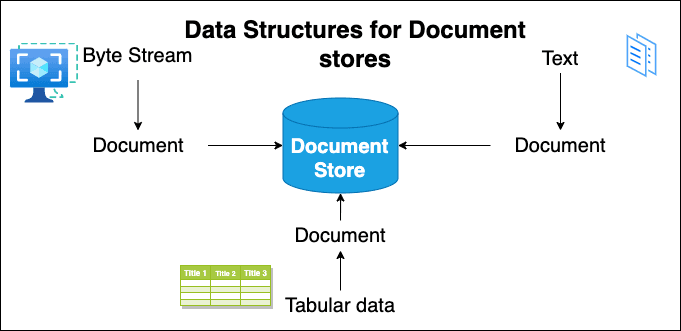 Haystack sample data structures
Haystack sample data structures
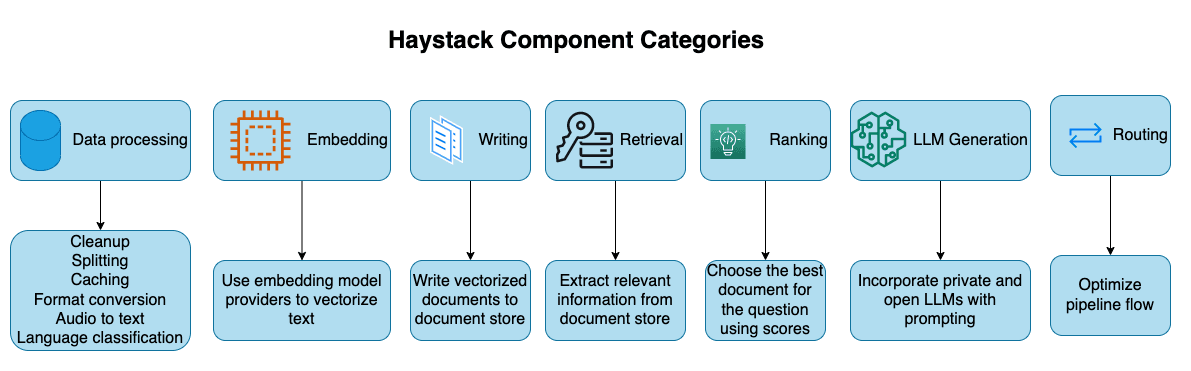 Haystack component categories
Haystack component categories
Bytewax:
Bytewax is a stream processing framework that excels in building real-time data processing applications. It supports stateful processing and real-time data flows, making it particularly suitable for dynamic RAG implementations where timely data handling is essential.
Installation and Configuration:
To install Bytewax, use the following pip command:
pip install bytewax
Bytewax's key concepts include workers and parallelization, dataflow programming, joining streams, windowing, connectors, and operators. These concepts are fundamental to understanding how Bytewax handles real-time data processing.
1. Workers:
Workers in Bytewax are distributed components that process data in parallel. This parallelization enables scalable and efficient handling of large data streams. Bytewax’s execution model utilizes identical workers that execute all steps (I/O) in a dataflow, ensuring consistency and efficiency.
2. State Management:
State management in Bytewax is crucial for maintaining the state across streaming events. This capability is essential for handling complex operations and ensuring data consistency throughout the data processing lifecycle.
3. Stream Processing:
Stream processing in Bytewax involves the continuous processing of data as it arrives. This approach is suitable for real-time applications where low latency is crucial. By processing data in real-time, Bytewax ensures that applications can respond promptly to new information.
Building Real-Time RAG with Bytewax and Haystack
Combining Bytewax and Haystack allows for the creation of powerful real-time RAG systems.
Here’s how these frameworks can be integrated to build a dynamic and efficient RAG implementation:
1. Data Extraction with Haystack:
- Use Haystack to extract relevant documents and information from various data sources.
- Leverage Haystack’s robust document retrieval and question-answering capabilities to gather the necessary data.
2. Data Wrangling and Pre-processing with Bytewax:
- Use Bytewax for real-time data wrangling and pre-processing.
- Implement stateful processing to handle complex data transformations and maintain data consistency.
3. Data Indexing and Retrieval:
- Index the processed data using Haystack’s document store capabilities.
- Employ Bytewax’s stream processing to handle real-time data retrieval and ensure low-latency responses. **
- Response Generation with an LLM:**
- Use a Large Language Model (LLM) to generate responses based on the retrieved data.
- Integrate Bytewax’s parallel processing capabilities to scale response generation and manage large volumes of data efficiently.
By combining the strengths of Haystack and Bytewax, developers can build sophisticated real-time RAG systems that are both powerful and efficient. Haystack provides the tools for robust document retrieval and question answering, while Bytewax offers the framework for real-time data processing and state management. ❗️Together, they enable the creation of advanced RAG implementations capable of delivering timely and accurate responses.
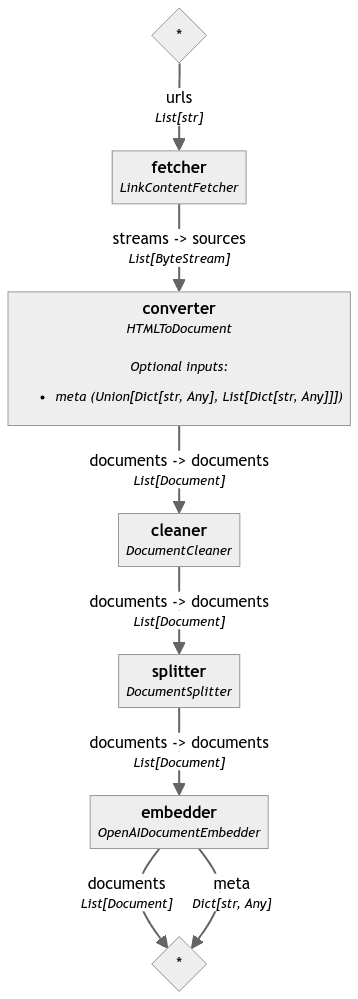
Sample real-time indexing dataflow with Haystack 2.0 and Bytewax
Now that we have introduced key concepts behind RAG as a directed graph, let's take a look at some code. In this example, we will build an indexing pipeline, and incorporate it as a map step as part of a Bytewax dataflow.
Simple indexing pipeline with Haystack 2.0
The pipeline below will take as input a URL, and it will return embeddings of the content of the page. The workflow we will follow is:
- Define the appropriate components
- Initialize a pipeline
- Add the components
- Connect components in the right order
The pipeline below will extract content from a web page, transform the content into Document objects, we will then clean the documents to remove specific patterns (line breaks, tags, etc), we can then split the content into chunks and apply an embedding model, for example from OpenAI.
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocumentfrom haystack.components.embedders
from haystack.components.preprocessors import DocumentCleaner
from haystack.components.preprocessors import DocumentSplitter
from haystack.components.embedders import OpenAIDocumentEmbedder
from haystack import Pipeline
regex_pattern = r"(?i)\bloading\s*\.*\s*|(\s*--\s*-\s*)+"
fetcher = LinkContentFetcher(retry_attempts=3, timeout=10)
converter = HTMLToDocument()
document_cleaner = DocumentCleaner(
remove_empty_lines=True,
remove_extra_whitespaces=True,
remove_repeated_substrings=False,
remove_substrings=None,
remove_regex=regex_pattern
)
document_splitter = DocumentSplitter(split_by="passage")
document_embedder = OpenAIDocumentEmbedder(api_key=Secret.from_token(open_ai_key))
# Initialize pipeline
pipeline = Pipeline()
# Add components
pipeline.add_component("fetcher", fetcher)
pipeline.add_component("converter", converter)
pipeline.add_component("cleaner", document_cleaner)
pipeline.add_component("splitter", document_splitter)
pipeline.add_component("embedder", document_embedder)
# Connect components
pipeline.connect("fetcher", "converter")
pipeline.connect("converter", "cleaner")
pipeline.connect("cleaner", "splitter")
pipeline.connect("splitter", "embedder")
pipeline.run({"fetcher": {"urls": ["url1.html", "url2.html"]}})
We can the visualize the pipeline as a DG through a mermaid graph.
One of the key functionalities of Haystack 2.0 is custom component definition. This enables us to implement custom functionality within the DG and pipeline framework.
Here are the requirements for all custom components:
@componentdecorator. This will define that you are, in fact, creating a component.run()method. This expects a set of input arguments and returns a dict object. You can pass values to therun()method of a component either when yourun()a pipeline, or by using connect() to pass the outputs of one component to the inputs of another. An example of this is in the Extended Example below.@component.output_types decorator. This will define the type of data your custom component will output and the name of the outputting edge. The names and types defined here should match correctly with the dict object that run() method returns.
Sample custom component
from haystack import component
@component
class WelcomeTextGenerator:
"""
A component generating personal welcome message and making it upper case
"""
@component.output_types(welcome_text=str, note=str)
def run(self, name:str):
return {"welcome_text": ('Hello {name}, welcome to Haystack!'.format(name=name)).upper(), "note": "welcome message is ready"}
In Haystack 2.0 we can also define pipelines as custom components. This approach is particularly powerful, as the pipeline can take as input an event from our Bytewax stream. This approach will enable us to apply a pipeline as a single map step.
Below is how we can wrap a pipeline as a custom component, so that it can listen to a stream of events using Bytewax.
from haystack import component, Document
from typing import Any, Dict, List, Optional, Union
@component
class IndexingPipeline:
def __init__(self, open_ai_key=None):
self.open_ai_key = open_ai_key
regex_pattern = r"(?i)\bloading\s*\.*\s*|(\s*--\s*-\s*)+"
# Define indexing pipeline components
fetcher = LinkContentFetcher(retry_attempts=3, timeout=10)
converter = HTMLToDocument()
document_cleaner = DocumentCleaner(
remove_empty_lines=True,
remove_extra_whitespaces=True,
remove_repeated_substrings=False,
remove_substrings=None,
remove_regex=regex_pattern
)
document_splitter = DocumentSplitter(split_by="passage")
document_embedder = OpenAIDocumentEmbedder(api_key=Secret.from_token(self.open_ai_key))
# Initialize pipeline
self.pipeline = Pipeline()
# Add components
self.pipeline.add_component("fetcher", fetcher)
self.pipeline.add_component("converter", converter)
self.pipeline.add_component("cleaner", document_cleaner)
self.pipeline.add_component("splitter", document_splitter)
self.pipeline.add_component("embedder", document_embedder)
# Connect components
self.pipeline.connect("fetcher", "converter")
self.pipeline.connect("converter", "cleaner")
self.pipeline.connect("cleaner", "splitter")
self.pipeline.connect("splitter", "embedder")
@component.output_types(documents=List[Document])
def run(self, event: List[Union[str, Path, ByteStream]]):
"""
Process each source file, read URLs and their associated metadata,
fetch HTML content using a pipeline, and convert to Haystack Documents.
This method is designed to handle events from Bytewax, a stream processing framework.
The event parameter is a list that may contain strings, Path objects, or ByteStreams.
Each event is expected to include a 'url' key which points to the target content to be processed.
The method performs the following steps:
1. Extracts the URL from the event.
2. Runs the Haystack pipeline to fetch and process the content from the URL.
3. Converts the processed content into a Haystack Document object.
4. Returns the Document object for further use or storage.
:param event: A list containing various types such as strings, Path objects, or ByteStreams, representing the event data.
:type event: List[Union[str, Path, ByteStream]]
:return: A Haystack Document object containing the processed content and metadata.
:rtype: Document
"""
url = event.get("url") # assumes a deserialized dictionary with a url key
doc = self.pipeline.run({"fetcher": {"urls": [url]}})
# Add custom functionality
def document_to_dict(self, document: Document, ) -> Dict:
"""
Convert a Haystack Document object to a dictionary.
"""
# Ensure embedding is converted to a list, if it is a NumPy array
embedding = document.embedding
if embedding is not None and hasattr(embedding, 'tolist'):
embedding = embedding.tolist()
return {
"id": document.id,
"content": document.content,
"meta": document.meta,
"embedding": embedding
}
Defining our data flow with Bytewax
We are now ready to initialize our dataflow with Bytewax. The code below assumes we have a JSONL file with urls, and a function to deserialize them (safe_deserialize).
from bytewax import operators as op
from bytewax.dataflow import Dataflow
from bytewax import operators as op
from bytewax.connectors.stdio import StdOutSink
from bytewax.connectors.files import FileSource
from bytewax.testing import run_main
indexing_pipeline = IndexingPipeline(open_ai_key=open_ai_key)
def process_event(event):
"""Wrapper to handle the processing of each event."""
if event:
document = jsonl_reader.run(event)
return jsonl_reader.document_to_dict(document)
return None
flow = Dataflow("rag-pipeline")
input_data = op.input("input", flow, FileSource("data/news_out.jsonl"))
deserialize_data = op.map("deserialize", input_data, safe_deserialize)
extract_html = op.map("extract_html", deserialize_data, process_event)
op.output("output", extract_html, StdOutSink())
We can execute our dataflow through the command:
python -m bytewax.run dataflow:flow
The dataflow can now be used to extract content from a series of URLs, clean the content and apply an embedding model!
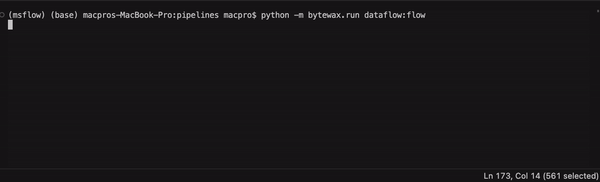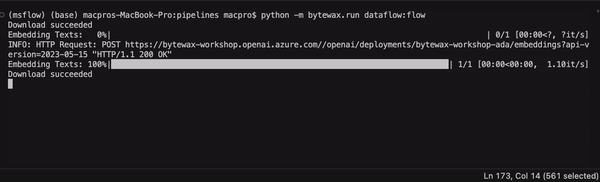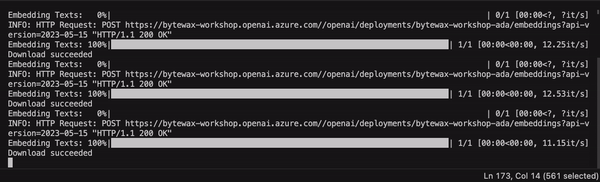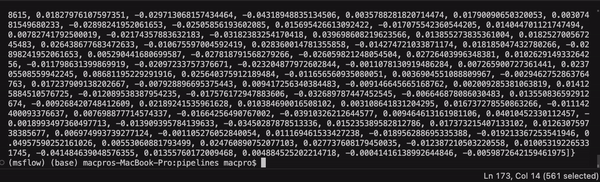
Two Powerful Ways to Ingest Streaming Data into Snowflake
Laura Funderburk
Senior Developer AdvocateLaura Funderburk holds a B.Sc. in Mathematics from Simon Fraser University and has extensive work experience as a data scientist. She is passionate about leveraging open source for MLOps and DataOps and is dedicated to outreach and education.

