
Building Real-Time RAG for Financial Data and News
By Anastasia Khomyakova & Laura Funderburk

We’re excited to invite you to our upcoming workshop in collaboration with Microsoft and Unstructured, hosted by AICamp.
📅 Date and Time: June 4, 10 am PT
⏱️ Duration: 2 hours
💻 Format: Virtual, FREE
Financial news and analytics with LLMs Retrieval Augmented Generation (RAG) is a technique that enhances the capabilities of Large Language Models (LLMs) by dynamically incorporating external information during the generation process. This approach combines the generative strengths of LLMs with the retrieval of relevant information from a large dataset, allowing for more informed, accurate, and contextually relevant outputs. By enabling real time analytics capabilities within RAG systems, we can ensure users obtain the latest information.
Designed for Data/ML/AI engineers, Data scientists, Software engineers interested in data processing, IT professionals looking to understand and apply RAG
In this workshop, we will focus on designing RAG pipelines through data flow pipeline design including Directed Graphs (DG), and the integration of real-time analytics.
Takeaway
❗️ Attendees will learn ➡️ how to set up efficient RAG pipelines that cater to the complexities of varied data types, driving enhanced decision-making and insights in their organizations.
This workshop will use financial data as its use case, and will leverage a combination of structured and unstructured data such as stock and market prices as well as publicly available news.
One of the challenges of financial data is how quickly it becomes irrelevant - both in terms of the market prices and any events around it.
Goals
- Gain proficiency in setting up and managing RAG pipelines for diverse data types;
- Leverage Bytewax for integrating real-time analytics into your data processing workflows;
- Incorporate Unstructured to process image and web based information;
- Incorporate Azure AI services to deploy and manage RAG pipelines;
- Understand the nuances of working with both structured and unstructured data in a unified system;
- Develop the skills to architect, deploy, and optimize advanced RAG systems in real-world scenarios. 💼📈📰
Architecture explored
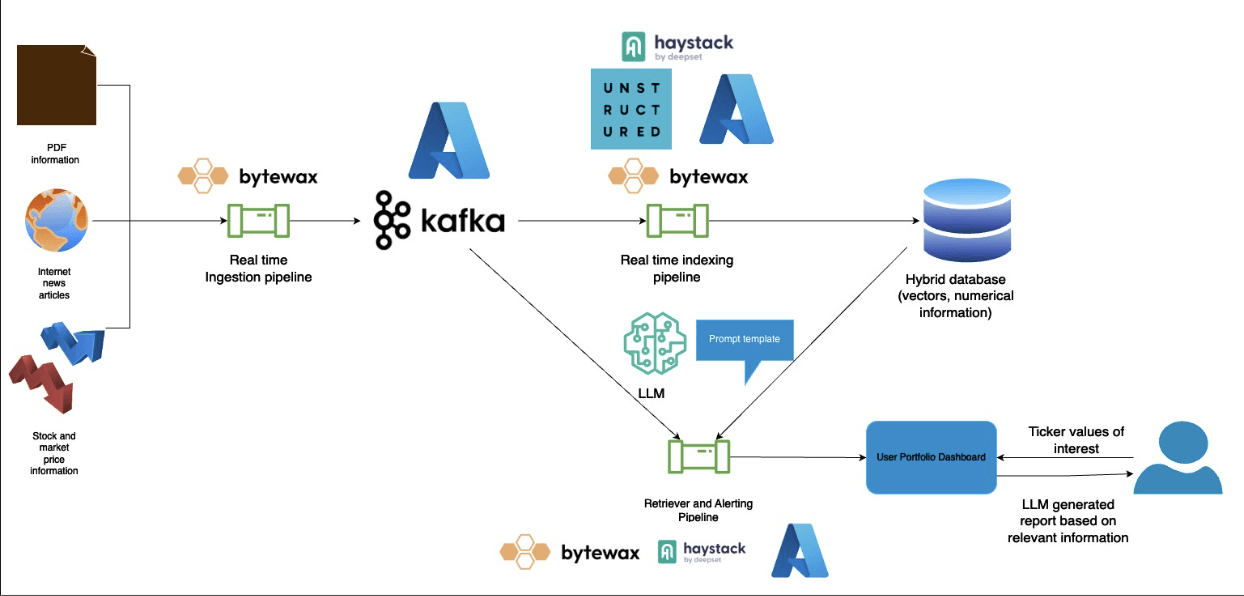
The agenda of the workshop
1. Introduction to the Partners and Problem Statement (15 minutes)
5 minutes: Welcome and brief introduction of the webinar goals. 5 minutes: Problem statement - Challenges in financial data processing and the need for real-time RAG. 5 minutes: Introduction to the partners:
Bytewax is an open-source Python framework that simplifies building apps for streaming data. It's developed for real-time processing and supports aggregation, windowing and splitting/joining streams, making it easier to handle big projects.
Azure AI is a comprehensive set of artificial intelligence services and tools provided by Microsoft on the Azure cloud platform. It helps developers and organizations build, deploy, and manage AI solutions. Azure AI encompasses a variety of services including machine learning, natural language processing, computer vision, and more. Technologies: Azure Document Intelligence; Azure AI Search; Azure Prompt Flow; Azure OpenAI.
Unstructured provides tools to ingest and preprocess unstructured documents for Retrieval Augmented Generation (RAG) and Fine Tuning. 80% of enterprise data exists in difficult-to-use formats like HTML, PDF, CSV, PNG, PPTX, and more. Unstructured effortlessly extracts and transforms complex data for use with every major vector database and LLM framework. They offer offer three products:
- API - The quickest way to get started for document transformation.
- Platform - Entirely no code enterprise platform to get all your data RAG-ready.
- Open Source - Best for prototyping.
2. Partner Solutions Showcase (45 minutes)
15 minutes: Bytewax Overview of Bytewax and its role in real-time data processing. Demonstration of how Bytewax integrates with financial data pipelines. Key features and benefits in the context of RAG.
15 minutes: Azure AI Services Overview of Azure AI, focusing on Azure AI Search, and Azure OpenAI services. Demonstration of how these services enhance data processing and retrieval. Use cases in financial data analytics.
15 minutes: Unstructured Tools Overview of Unstructured tools for processing unstructured data. Demonstration of the API, Platform, and Open Source tools. Key features and how they facilitate the preparation of financial data for RAG.
3. Integration of Technologies (40 minutes)
10 minutes: Theoretical insights into designing RAG pipelines RAG principles and assumptions Introduction to data flow pipeline design and Directed Graphs (DG). Modeling RAG as a directed graph
15 minutes: Practical integration steps Architectural design Setting up and integrating Bytewax, Azure AI, and Unstructured tools through an orchestrator. Visualization of our directed graphs
15 minutes: Case study: Financial Data and News Step-by-step code walkthrough of a real-world example Understanding the data sources Setting up real time pipelines to extract, preprocess and index data Setting up a retriever pipeline Bringing all pieces together into an application
4. Question and Answer Session (20 minutes)
Open floor for audience questions.
Pre-requisites
- Basic Understanding of Data Structures and Algorithms
Familiarity with fundamental concepts in data structures and algorithms is required. This includes knowledge of arrays, linked lists, stacks, queues, trees, and basic algorithmic principles.
- Proficiency in Python Programming
Comfortable with writing and debugging Python code. Experience with Python libraries commonly used in data processing and machine learning, such as Pandas, NumPy, and Scikit-learn.
- Knowledge of Data Processing and ETL Concepts
Understanding of data extraction, transformation, and loading (ETL) processes. Experience with handling structured (e.g., CSV, JSON) and unstructured (e.g., text, images) data.
Optional To reproduce the solution - not required to participate in the webinar
- Setup of Required Azure Services
- Get Unstructured API Key and Install Unstructured Tools
- Obtain an API key from Unstructured by signing up on their platform.
- Follow API documentation to set up your connectors and ingest your documents to your destination.
- Clone this repository and install dependencies
- git clone
- cd real-time-rag-workshop/
- Pip install -r requirements.txt
Instructors info

Zander Matheson, Founder & CEO at Bytewax. Zander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.
Laura Funderburk, Senior Developer Advocate at Bytewax. Laura has a B.Sc. Mathematics from Simon Fraser University, and over three years of experience as a professional data scientist. Laura is enthusiastic about using open source for MLOps and DataOps and is passionate about outreach and education. In her day to day, Laura creates written content around building end to end scalable LLM pipelines with streaming data.
Shagun Sharma, Data Scientist at Microsoft via TCS. Shagun is a highly skilled Data Scientist and AI Engineer with over five years of extensive experience in the field of Natural Language Processing (NLP). For almost four years, Shagun has been a pivotal part of the AI Co-Innovation Lab, globally leading multiple customer engagements around generative AI. Shagun's leadership has extended to labs in Redmond, WA, Montevideo, Uruguay, and San Francisco, CA. Shagun has successfully built more than 15 proof-of-concept (POC) projects leveraging Azure technologies, including Azure OpenAI, Azure AI Search, Azure Document Intelligence, LangChain, and other advanced tools
Nina Lopatina is a Staff Developer Relations Engineer at Unstructured, where she helps customers make the most of their unstructured data for retrieval augmented generation (RAG) and other large language model (LLM) use cases. Nina has been primarily working on multilingual language modeling since 2018. In this span, she has worked on language classification and generation. Throughout her career, she has focused on the data that LLMs need to improve performance and reliability.
📣 ❗️ Please remember that we'll be handling all communications and answering questions through our Slack channel, #workshop-room. If you haven't joined yet, now's the perfect time!
🐝🐝🐝
Real time RAG with Bytewax and Haystack 2.0

Anastasia Khomyakova
Laura Funderburk
Senior Developer AdvocateLaura Funderburk holds a B.Sc. in Mathematics from Simon Fraser University and has extensive work experience as a data scientist. She is passionate about leveraging open source for MLOps and DataOps and is dedicated to outreach and education.

