

Uses Bytewax Version 0.10.1
Written by Osinacha Chukwujama and Zander Matheson
Data enrichment is the process of adding to or enhancing data to make it more suitable or useful for a specific purpose. Often in the field of analytics this will aid in providing more useful insights and in machine learning this may refer to enhancing the data to get a more accurate model. Data enrichment is most often the result of joining additional data from a 3rd party api or another data source. For example the data could be enriched using an internal database to look up customer data based on the user ID, or another example would be adding some information from clearbit or similar to build a more detailed picture of the customer based on their email.
In this tutorial, you’ll learn how to use Bytewax and Apache Kafka to enrich data. In the following sections, you’ll learn how to write a Bytewax dataflow that will ingest a stream of IP addresses from a Kafka topic, enrich the data by querying the most likely geolocation of those IP addresses and then stream these to a different Kafka topic.
Implementing Real-Time Data Enrichment with Python
The steps below outline the process of taking IP address data and enriching it with geolocation for further downstream analysis. In this tutorial, you’ll set up two Apache Kafka topics, one for input and one for output. The input topic will contain raw IP addresses, and the output topic will contain location information provided by the IP addresses from the input topic.
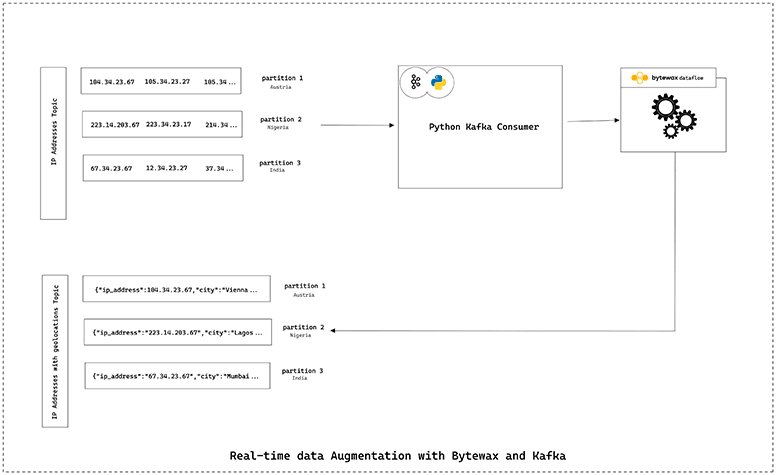
The first step we will cover in this tutorial will be to populate the input topic with IP address data partitioned by country. In the next step, we will run a Bytewax dataflow (essentially a pipeline defined using Python that is used to organize operations such as “map”, “filter”, and “reduce” on streaming data to perform some transformation) that obtains location data from the IP addresses using the publicly available ipapi REST API. Then, the Bytewax dataflow writes the location data that is obtained into the output Kafka topic, partitioned by country. The following diagram shows a rough architecture of the data enrichment system:
Prerequisites
Before you begin, you’ll need the following:
- A local copy of the starter code, which can be cloned from this GitHub repository.
- Python 3 version 3.8 or higher and pip version 20 or higher.
- A local installation of Docker and Docker Compose. Docker is the easiest way to set up Apache Kafka without worrying about versions.
Clone the starter code repo and navigate into it using the command below:
git clone https://github.com/bytewax/real-time-data-enrichment-with-bytewax.git
cd real-time-data-augmentation-with-bytewax
The starter code is a project that uses a simple requirements.txt file for dependency management. We recommend using a virtual environment manager to create a fresh python environment. Copy and paste the command below in a shell to install the requirements:
pip install -r requirements.txt
If the above installation is unsuccessful, make sure you have a clean environment and that the dependencies are not conflicting with each other.
Apache Kafka provides the data source and sink that this dataflow works with.
The docker-compose file in the project contains set up instructions for starting the Kafka broker and Zookeeper. Navigate to the kafka directory and run the command below to start the Kafka Docker container in detached mode:
cd kafka
docker compose up -d
You should get an output showing that two containers are running (Zookeeper and broker):
Setting Up the Apache Kafka Topics
The dataflow used here has two topics of concern:
1. An input topic: “ip_addresses_by_countries”, that will store IP addresses partitioned by their country of origin.
2. An output topic: “ip_addresses_by_location”, that will store JSON location data obtained from the IP addresses in the input topic. This output topic is also partitioned by the country of origin of the IP address. The JSON data contains city, state, or region, and country key value pairs.
Each topic has twenty partitions and will be created using Kafka-Python. The topic creation and data population commands are scripted in the src/initializer.py Python script. Run the command below to create both topics and populate the input topic:
python src/initializer.py
# Result
# input topic ip_addresses_by_countries created successfully
# output topic ip_addresses_by_location created successfully
# input topic ip_addresses_by_location populated successfully
How the Dataflow is Structured
The dataflow has a single step that performs the data enrichment using an IP address as input.
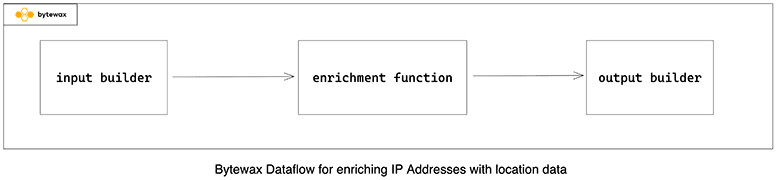
Every Bytewax dataflow begins from a dataflow instance, flow = Dataflow(). A dataflow has some mechanism for input and output. In the following code snippet, we use the KafkaInputConfig for the input and an output builder to write back to a Kafka topic:
flow = Dataflow()
flow.map(get_location)
flow.capture()
if __name__ == "__main__":
input_config = KafkaInputConfig(
"localhost:9092", "ip_adds", "ip_addresses_by_countries", messages_per_epoch=1
)
cluster_main(flow, input_config, output_builder, [], 0,)
The capture operator on the dataflow instance calls the function returned by the output builder. However, before the capture method runs, all intermediate functions that are passed to map, filter, and reduce operations are run. The previous dataflow has a single map operation that takes an IP address as input and returns the location data based on that IP address in JSON format. The code for this is defined in the get_location function.
def get_location(data):
key, value = data
ip_address = value.decode('ascii')
response = requests.get(f'https://ipapi.co/{ip_address}/json/')
response_json = response.json()
location_data = {
"ip": ip_address,
"city": response_json.get("city"),
"region": response_json.get("region"),
"country_name": response_json.get("country_name")
}
return location_data
The KafkaInputConfig is an input mechanism that will listen to the configured topic and pass the returned data in the format (key, payload) to the next step in the dataflow. In this case it will be (country, ip_address). We pass the kafka broker address, the group_id, topic_name and the number of messages to batch. In this case, we are going to batch each event individually.
input_config = KafkaInputConfig(
"localhost:9092", "ip_adds", "ip_addresses_by_countries", messages_per_epoch=1
)
In the following code, the output_builder returns the function send_to_kafka that takes in the JSON output from the get_location function call. Then, it writes it to the output Kafka topic ip_addresses_by_location.
def output_builder(worker_index, worker_count):
def send_to_kafka(previous_feed):
location_json = previous_feed[1]
producer.send('ip_addresses_by_location', key=f"{location_json['country_name']}".encode('ascii'), value=location_json)
return send_to_kafka
You can think of a Bytewax dataflow as a pipeline that takes in one input item from a source, transforms it, and sends it to a sink.
Running the Dataflow
You can run the dataflow as a normal Python script using the following command:
python src/dataflow.py
If throughput is a concern because of the added API request latency. You could also increase the parallelism across workers or processes to match the number of topics that were initially created.
This command will source data from the input topic, enrich the data, and write the result to the output topic. Then, you can investigate the output topic using the following command:
docker exec -it broker kafka-console-consumer --bootstrap-server broker:9092 --topic ip_addresses_by_location --from-beginning
The output will look something like this:
{"ip": "76.132.87.205", "city": "San Jose", "region": "California", "country_name": "United States"}
{"ip": "204.135.230.95", "city": "Collierville", "region": "Tennessee", "country_name": "United States"}
{"ip": "134.71.193.184", "city": "Pasadena", "region": "California", "country_name": "United States"}
{"ip": "137.77.92.48", "city": "Denver", "region": "Colorado", "country_name": "United States"}
Please note: Your output could look slightly different because some HTTP requests were completed before others.
Conclusion
In this article, you learned about data enrichment and its use cases and how you can map your IP data from server logs to geolocations for further understanding and analysis.
Bytewax is a stateful stream processing engine that allows you to transform data streams for your use case. It’s built on the Timely-Dataflow Rust library for dataflow computation and allows you to set up stream processing pipelines for aggregating, enriching, and excluding items from your data streams. If you like the project, give the GitHub repo a star!
Python Parallelization - Threads vs. Processes

Osinacha Chukwujama
Technical Writer
Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

