At the beginning of 2023, there was a Cambrian explosion of AI in the natural language space. Terms like LLMs, foundational models, generative AI and more could be heard at your local coffee shop or in the daily news. Something called ChatGPT is revolutionizing the world. What is ChatGPT? Is it really coming for your job? Can ChatGPT write essays? Why teachers are raising the alarm as students submit AI written essays? Etc, etc.. if as engineers, our job is to automate ourselves out of a job, maybe we finally succeeded! One of the crucial aspects of why ChatGPT has been so successful is its ability to maintain context not only via the model architecture, but also of the conversation between you and the bot. That’s something we are going to explore here as we build a stateful application in Python with Bytewax.
- Skip the words and go straight to ChatGPT in Python on our GitHub.
Before we move on to our application, let’s take a quick detour into what some of the language and terms are.
LLMs and Foundational Models
LLMs (Large Language Models) are machine learning models trained on vast amounts of text data. They use this data to learn patterns and relationships in language, enabling them to generate human-like text with remarkable accuracy. The models are often trained on billions of words from books, websites, and other sources, making them some of the largest and most complex models in the world. Often you will hear reference to parameters in reference to the size of the model the parameters are values assigned as weights or biases that in a simplified way tell the model which tokens are important.
Foundational Models refer to models that are trained on a huge volume of data in an unsupervised manner and they can be then tuned for a variety of different applications. For example, you can tune a foundational model on the legal domain to answer legal questions.
NATS
NATS is a high-performance open-source messaging system that is designed for cloud-native applications and microservices. It provides efficient and scalable communication between applications and services, and supports features such as publish/subscribe messaging, request/reply patterns, and streaming. NATS is written in the Go programming language and is designed to be lightweight, fast, and easy to use. It has become a popular choice for organizations that are looking for a fast, efficient, and reliable messaging system for their cloud-native applications. We are going to use NATS for the ease of use in the request response pattern.
Context and State
When we have a conversation as humans, we get information from many different sources in our environment that allow us to respond appropriately; we take in our surroundings, visual cues, body language and what has been spoken about in our conversation. This can be referred to as context. It is difficult for software applications to have this multi-modal context, but we can still maintain what context we can gather to make the application more intelligent. This is what ChatGPT does, it maintains information about our conversation to reply intelligently.
In an application, context is stored in state that can be referenced by the application. This is solved in a number of ways, for example it can be stored in the browser as part of a session, or in a database referenced by the application server over multiple sessions. With a distributed stream processing engine you can have state maintained globally or locally. The decision on whether you use one or the other will impact latency and complexity. Locally stored state can provide very low latency, but requires you to route data correctly to the right worker. Global state may be slower, but you don't care as much about routing the right data to the right worker.
Bytewax maintains state on each workers and routes the data to the correct worker for stateful operations. We are going to take advantage of this to build our ChatGPT clone.
Developing Our ChatGPT clone
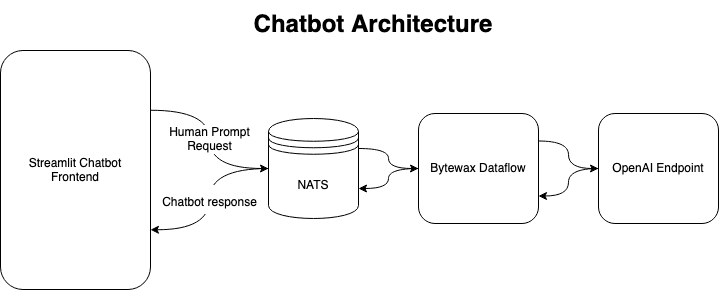
We are going to build a Bytewax dataflow that will facilitate receiving prompts via NATS, maintaining the conversation between the user and the AI as well as facilitate responding to the prompt via NATS. The overall architecture of our application is included for reference.
**Prerequisites**
NATS Included in our docker-compose, you can also install NATS via their website
Docker/Docker Compose We will use Docker to escape the subtleties in different OS and environments. Docker Compose will facilitate running multiple services that need to communicate with each other.
OpenAI API Key Follow the instructions on the OpenAI website
Python modules bytewax streamlit backoff pynats openai
NATS Input
To start, let's cover the input mechanism. We are going to construct a custom input with the Bytewax manualInputConfig. This is going to subscribe to a NATS subject called prompts and when a new NATS message is received, it will pass the required information downstream. The way that NATS works, we will get a unique INBOX identifier and a payload. We need the INBOX identifier information to respond with that information since our frontend will be waiting for it. This is the way the NATS request loop works.
from pynats import NATSClient
nats_client = NATSClient()
nats_client.connect()
def input_builder(worker_index, worker_count, state):
# Ignore state recovery here
state = None
messages = []
def callback(message):
messages.append(message)
nats_client.subscribe(subject="prompts", callback=callback)
while True:
nats_client.wait(count=1)
yield None, messages.pop()
flow = Dataflow()
flow.input("input", ManualInputConfig(input_builder))
Chatbot Response & Conversation
If you recall above, we mentioned stateful processors and how in a distributed application we need to route data to the right worker if the state is maintained locally. We will pull the user_id information out of the NATS message payload and use this as a key. Bytewax will then route the data based on this key so that it lands on the right worker for our stateful operator. This is handled in a map operator.
import json
def key_on_user(msg):
user_id = json.loads(msg.payload.decode())['user_id']
return(user_id, msg)
flow.map(key_on_user)
Once the data has been keyed on the user we can use the stateful operator, stateful_map, which will allow us to make a request to OpenAI for a response to the prompt included in the NATS message and also maintain the state of our conversation. stateful_map expects the name of the step, a builder function and a mapper function.
The way that stateful_map works is that before the step, the data is exchanged across workers as needed based on the key. Then, if the key is seen for the first time the builder function is called, then the mapper function will be called.
class Conversation:
def __init__(self) -> None:
self.session_responses = []
self.session_prompts = []
self.session_start = time.time()
self.elapsed_time = 0
def generate_response(self, msg):
if len(self.session_responses) >= 1:
chat_log = "\n".join([f"Human: {x[0]}\nAI:{x[1]}" for x in zip(self.session_prompts, self.session_responses)])
else:
chat_log = ""
prompt = f"{chat_log}\nHuman: {msg.payload.decode()}\nAI:"
response = completions_with_backoff(
model="text-davinci-003",
prompt=prompt,
stop=['\nHuman'],
temperature=0.6,
max_tokens=2000
)
print(response)
self.session_responses.append(response.choices[0].text)
self.session_prompts.append(msg.payload.decode())
return self, (msg, response.choices[0].text)
flow.stateful_map(
step_id = "conversation",
builder = lambda: Conversation(),
mapper = Conversation.generate_response,
)
To help with rate limiting in the openAI API, we add a backoff/retry functionality.
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def completions_with_backoff(**kwargs):
return openai.Completion.create(**kwargs)
NATS Output
To respond back to NATS in a way that our waiting client will get the message, we use the information from the NATS message we received initially and run the response code inside of an custom capture operator.
def output_builder(worker_index, worker_count):
def publish(key__msg__response):
key, (msg, response) = key__msg__response
nats_client.publish(msg.reply, payload=response)
return publish
flow.capture(ManualOutputConfig(output_builder))
Running NATS
Now that we have our dataflow written, let's run NATS and our dataflow via docker compose so that we can have them easily communicate with each other.
version: "3.5"
services:
nats-server:
image: nats:latest
restart: always
ports:
- "8222:8222"
- "6222:6222"
- "4222:4222"
bytewax:
image: bytewax-chatbot
container_name: bytewax-1
environment:
- NATS_URL=nats://nats-server:4222
- OPENAI_API_KEY=$OPENAI_API_KEY
depends_on:
- nats
We can start these with the commands in a simple run script. It is important that you have your API key stored as an environment variable first. export OPENAI_API_KEY=<your key here>
# run.sh
# build docker image
docker build . -t bytewax-chatbot
# run dataflow
docker compose up -e OPENAI_API_KEY=`$OPENAI_API_KEY`
Building the Streamlit Frontend
Now we have NATS acting as our broker and our dataflow waiting for prompts and ready to provide a response, we can add a little interactive widget to write and send our prompts. Streamlit is a good tool for building apps like this.
# frontend.py
import streamlit as st
from pynats import NATSClient
import json
# set up page details
st.set_page_config(
page_title="Bytewax ChatGPT",
page_icon="🐝",
layout="wide",
)
st.title("Bytewax ChatGPT")
if __name__ == "__main__":
user_id = st.text_input('Enter your user id')
print(user_id)
prompt = st.text_input('Enter your question here')
if st.button("Submit"):
print("querying for {prompt}")
with NATSClient() as client:
payload = json.dumps({
"user_id":user_id,
"prompt":prompt})
print(payload)
msg = client.request("prompts", payload=payload.encode())
st.write(msg.payload.decode())
And we can run our streamlit application with the streamlit commandline tool.
streamlit run frontend.py
Scaling Out
The nice thing with our architecture is that scaling out the bytewax dataflow backend is pretty straightforward. Just scale the worker_count_per_proc and/or proc_count in your execution.
if __name__ == "__main__":
spawn_cluster(flow, proc_count = 1, worker_count_per_proc = 1,)
Summary
Go forth and play with your new ChatGPT clone! You can now build stateful applications with Bytewax and NATS 🙂!
The next steps could include:
- Adding a second capture to the dataflow to write out the prompts and responses to a database for further fine-tuning.
- Adding in a summarize step that will summarize the conversation when we run out of tokens passing all the responses back.
- Moving away from OpenAI with a huggingface transformer model to save $$.
- Taking it to the next level and fine-tuning your own model for a certain application.
Using Language Models in a Streaming Context to Understand Financial Markets

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.