

As programs process ever-increasing amounts of data, they also use an increasing amount of time and resources. One way for programmers to reduce the time and cost of processing all that data is to use parallelization.
Parallelization is the act of running several tasks at once to speed up processing. You divide a single large or complex task into more manageable pieces, then run the smaller pieces simultaneously. This is especially helpful for operations that involve a lot of input/output (I/O), are network-bound, or use a lot of CPU power. If you’re one of the many developers using Python, its standard library offers modules for parallelization.
In this article, you’ll learn more about Python parallelization and when to use the different methods involved—multithreading and multiprocessing—to handle large amounts of data.
Why Do You Need Parallelization?
When you’re writing software, you’ll inevitably deal with I/O or network-bound operations such as downloading and uploading files from external sources. You might also have to deal with tasks that are more CPU-bound, such as preprocessing and data transformation calculations (which could be applied to text, image, audio, or numerical data).
All these processes typically take a long time to complete, which causes latency and decreased efficiency—either for you when developing the application or for consumers when using it. Parallelization helps you manage these processes more quickly and efficiently.
The Python Global Interpreter Lock
In order to use parallelization in Python, you need to work around the global interpreter lock (GIL). This system locks the interpreter and limits how many threads can use it at once. It was put in place to prevent memory leakage and the problems it would cause if there were no way to manage the threading system.
The GIL limits your Python scripts to using a single CPU, or process, and a single thread, or an independently running component of a process. You can use parallelization to overcome this restriction and run multiple processes at once to speed up program execution.
Keep in mind, though, that the GIL was put in place for a reason. When you loosen these restrictions, make sure to avoid the problems that the GIL prevents.
Use Cases for Parallelization
Parallelization helps with a number of different operations. For example, in natural language processing (NLP), multiple operations must be performed on text in order to process it. These include tokenization and the computation of term frequency-inverse document frequency (TFIDF) vectors, which generally require working with large sparse arrays.
When you’re carrying out CPU-heavy operations like audio data processing, parallelization enables you to solve smaller parts of these operations simultaneously, using more of the available resources and speeding up the process.
Additionally, if the cost of running a task is an obstacle due to the time it takes to run, parallelization can make it achievable by reducing the time required.
By default, tasks are run one after another:
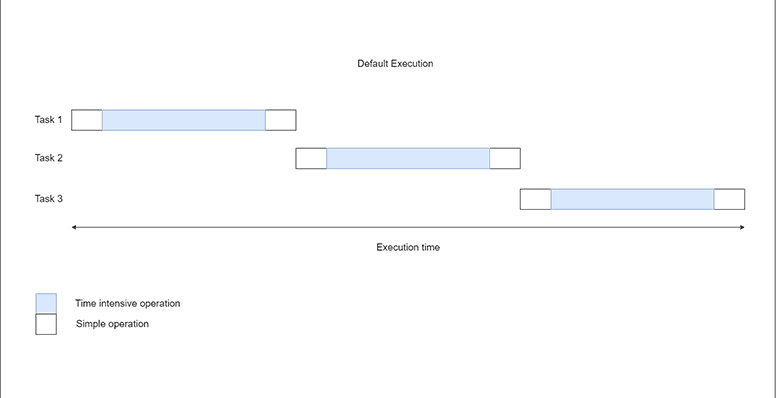
How Does Python Parallelization Work?
Parallelization in Python is a type of concurrency, in which various tasks are carried out at once in various processes. Each process is associated with a different interpreter and GIL. As a result, numerous operations can be performed simultaneously with no issues.
The components involved in parallelization are threads and processes.
Threads
Python threads are essentially different collections of executable instructions. By default, the Python interpreter used to run a script is connected to a single thread and only processes the commands in that thread. Concurrency allows for the simultaneous execution of multiple tasks using multiple threads through the multithreading technique.
However, concurrency only works when these tasks are I/O or network-bound. For instance, after sending a download request, the thread must wait for the request to be executed by the external server before receiving a response.
Multithreading ensures that one thread can cede control to another thread if a task there needs to be completed. In preemptive multitasking, you use a predetermined number of threads and allow the operating system to choose which thread to switch to when necessary. You can achieve this with Python’s threading and concurrent.futures modules.
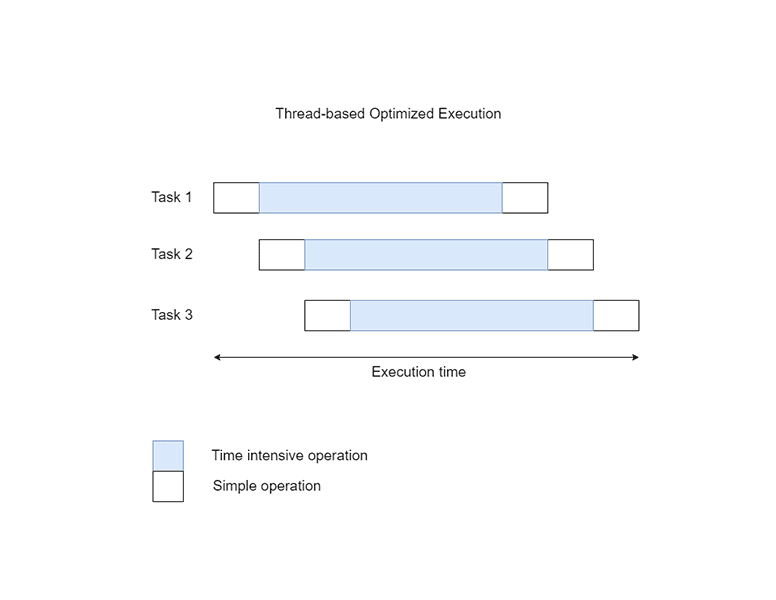
You don’t necessarily need multiple threads to run multiple tasks, because only one thread is active at any given time, thanks to the GIL. You can specify different points in your program to switch from one task to another using the cooperative multitasking technique. These are usually the components that have some I/O or network overhead. Useful modules here are asyncio, curio, and trio.
Processes
Every line of code in Python is run in a process that has multiple threads, a GIL, and an interpreter. However, by default, only one process is available for use. This is referred to as the main process. If you use multiple processes, you can run tasks in parallel to speed up operations. This is possible because a global interpreter lock only restricts a single process, giving multiprocessing an advantage.
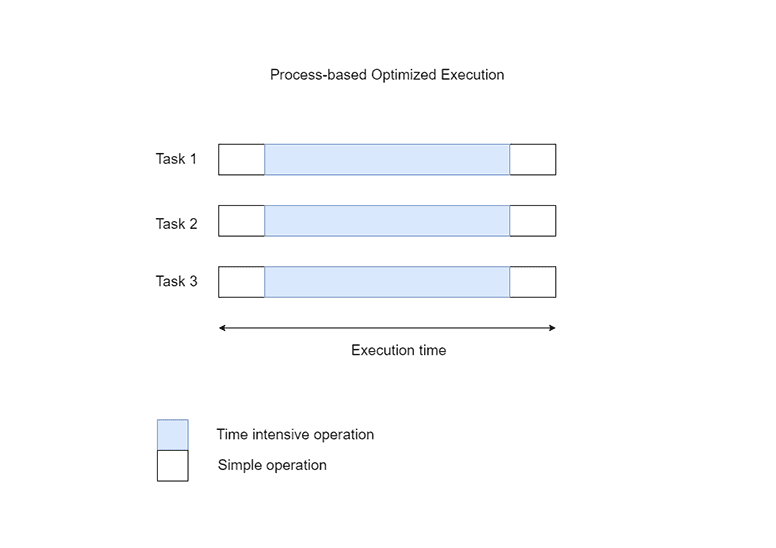
Performing network- or I/O-intensive tasks lessens the effect of multiprocessing because the operating system still has to wait for the requests to finish processing. However, by parallelizing CPU-intensive tasks, you can greatly reduce the computation time. Using Python’s concurrent.futures or multiprocessing modules can help with this.
Threads vs. Processes
Should you optimize with threads or processes? To answer this question, analyze your process to find the steps that are costing you the most time. Consider thread usage optimization if the problem involves I/O or network-bound operations. This could be accomplished by using multiple threads or multiple tasks on a single thread. If the problem involves CPU-bound operations, optimize processes via multiprocessing.
In some situations, you could see slowdowns in both I/O or network-bound and CPU-bound steps. You might need to use both threads and processes to solve the problem.
Implementing Parallelization
Next are examples of how to implement the above approaches, using the sample problem of making requests from a blog. In web scraping projects, this is typically the first step.
To follow along, make sure you have Python 3.7 or later installed and, ideally, work in a virtual environment. Use the command pip install requests to install the requests library.
Next, configure your environment:
import time
import requests
def download_blog_post(url: str, index: int) -> str:
print(f"Task {index}: Running")
response = requests.get(url=url)
print(f"Task {index}: Request successful. Status: {response.status_code}")
return response.textIn the code block above, you import the time and requests libraries into your working environment, then define a function named download_blog_post(). This function accepts a string representing the link to a blog post and an index variable to indicate which task is active at the moment. The current task is indicated by printing a string. Then you submit the request with the get() method by passing in the required URL parameter. You return the text in the response after sending some output to indicate that the request was successful along with the status code. This returned text contains the web page’s content.
You can call the function created iteratively and compute the run time as shown below:
if __name__ == "__main__":
blog_posts = [
'https://www.jordanbpeterson.com/transcripts/lewis-howes/',
'https://www.jordanbpeterson.com/transcripts/lewis-howes-2/',
'https://www.jordanbpeterson.com/philosophy/facts-and-values-'
'science-and-religion-notes-on-the-sam-harris-discussions-part-i/',
'https://www.jordanbpeterson.com/philosophy/facts-from-values-not'
'-without-an-intermediary-notes-on-the-sam-harris-discussions-part-ii/',
'https://www.jordanbpeterson.com/poetry/prairie-requiem/',
'https://www.jordanbpeterson.com/blog-posts/the-sunday-times-interview-request-and-my-response/'
]
start = time.time()
content = []
for i, link in enumerate(blog_posts):
content.append(download_blog_post(link, i))
print(f"Run completed in {time.time() - start} seconds.")In the above code, you declare a condition to make sure the program is running from its original file, then create a list with all of the blog post links that need to be scraped. You declare a variable to hold the start time so that you can determine how long the task takes to complete. You call the download function on each link as you loop through the blog_posts array. Once this is finished, you use the print() function to parse a string and show the time difference between the start time and the current time.
When the script is run, you should see the below output:
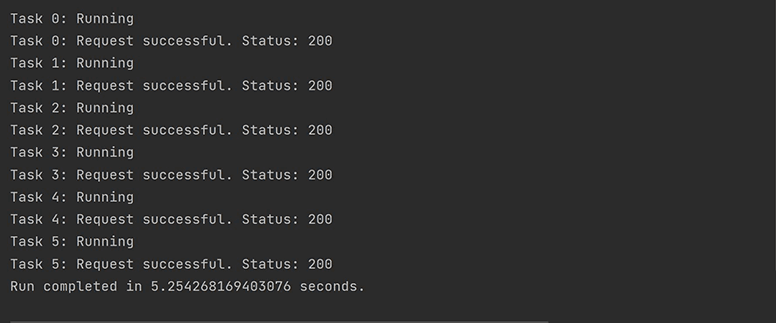
Note how each task is started and finished before moving on to the next. The response time may differ based on your network and compute resources. The result displayed is the minimum run time in three runs. You’ll see the same for all subsequent cases.
Using Multithreading
You can modify the above program to use multithreading:
import time
import requests
import concurrent.futures
def download_blog_post(args: tuple) -> str:
url, index = args
print(f"Task {index}: Running")
response = requests.get(url)
print(f"Task {index}: Request successful. Status: {response.status_code}")
return response.textIn addition to the time and requests modules, import the concurrent.futures module. Since this module is a part of the Python standard library, installation isn’t necessary. Next, change the parameters of the download_blog_post() function to a tuple. The tuple args is unpacked into the url and index variables, which are analogous to those in the previous section.
Finally, you can create the threads and call the function as shown below:
if __name__ == "__main__":
blog_posts = [
'https://www.jordanbpeterson.com/transcripts/lewis-howes/',
'https://www.jordanbpeterson.com/transcripts/lewis-howes-2/',
'https://www.jordanbpeterson.com/philosophy/facts-and-values-'
'science-and-religion-notes-on-the-sam-harris-discussions-part-i/',
'https://www.jordanbpeterson.com/philosophy/facts-from-values-not'
'-without-an-intermediary-notes-on-the-sam-harris-discussions-part-ii/',
'https://www.jordanbpeterson.com/poetry/prairie-requiem/',
'https://www.jordanbpeterson.com/blog-posts/the-sunday-times-interview-request-and-my-response/'
]
start = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=6) as executor:
iterable = zip(blog_posts, range(len(blog_posts)))
content = executor.map(download_blog_post, iterable)
print(f"Run completed in {time.time() - start} seconds.")In the above code, the for loop from the earlier code is swapped out. The threads are first managed by a context manager using the with statement. An instance of the ThreadPoolExecutor() function from the concurrent.futures module is created with the max_workers argument assigned a value of 6. This instance is given the alias executor. When done in this way, the creation and destruction of the thread pool are properly managed.
The blog post URLs are then paired with index values using the zip() function. The function to be executed (download_blog_post()) and an iterable are both then passed to the executor.map() function. You should see the following output:
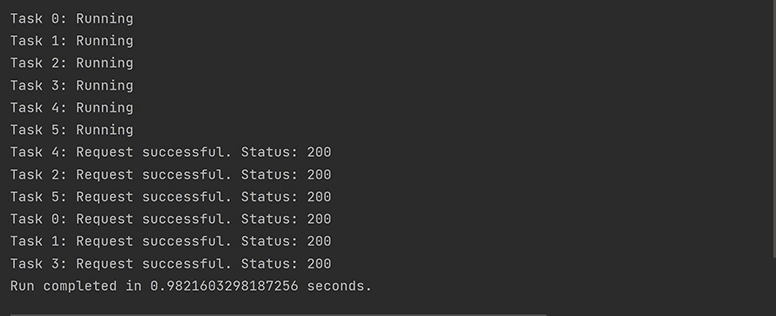
This output demonstrates that using multithreading with six threads cuts the run time by a factor of five. The order of completion is different from the order in which the tasks are started, and all tasks begin running before any of them is finished. This is partially due to the fact that the OS manages thread assignments, meaning the order will inevitably change with each run.
Using Multiprocessing
As previously noted, multiprocessing does not offer the greatest benefit when handling I/O or network-bound tasks. However, because these operations take some time, they can be used to show the power of multiprocessing:
import multiprocessing
import os
import requests
import time
def download_blog_post(url: str) -> str:
print(f"Process {os.getpid()}: Running")
response = requests.get(url)
print(f"Process {os.getpid()}: Request successful. Status: {response.status_code}")
return response.textIn the above code, you import the os, multiprocessing, requests, and time modules. Next, you define the download_blog_post() method, which only takes in the URL as a parameter. Different processes will have different identifiers, and they're more natural than the indexes used before, so instead of using “Task” in the print statements, you use “Process” and get the process ID using the os.getpid() method. Finally, you call the request.get() method and return the text in the response like before.
You can create the multiprocess pool and compute the program run time as shown below:
if __name__ == "__main__":
blog_posts = [
'https://www.jordanbpeterson.com/transcripts/lewis-howes/',
'https://www.jordanbpeterson.com/transcripts/lewis-howes-2/',
'https://www.jordanbpeterson.com/philosophy/facts-and-values-'
'science-and-religion-notes-on-the-sam-harris-discussions-part-i/',
'https://www.jordanbpeterson.com/philosophy/facts-from-values-not'
'-without-an-intermediary-notes-on-the-sam-harris-discussions-part-ii/',
'https://www.jordanbpeterson.com/poetry/prairie-requiem/',
'https://www.jordanbpeterson.com/blog-posts/the-sunday-times-interview-request-and-my-response/'
]
start = time.time()
with multiprocessing.Pool(processes=6) as pool:
content = pool.map(download_blog_post, blog_posts)
print(f"Run completed in {time.time() - start} seconds.")In the above code, a context manager that instantiates a multiprocessing.Pool object of six processes with the alias pool takes the place of the default implementation’s for loop. You then use the pool.map() method to map download_blog_post() onto the blog_posts iterable and print the execution time. You should see the following output:
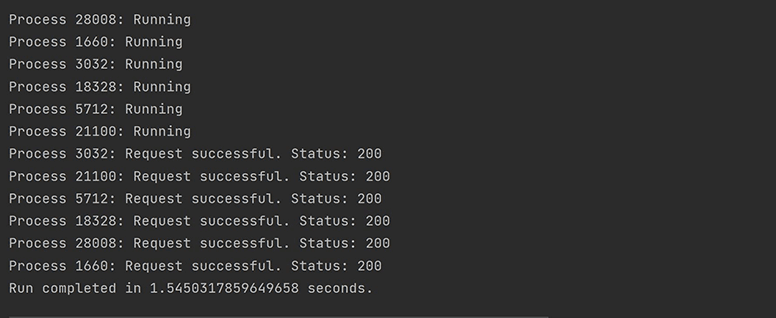
You can see that various processes were instantiated for the various tasks in this case. Additionally, there was more of a lag when the processes were being created in comparison to before. However, you still see a speed improvement in the total run time. This time is essentially the response time of the most expensive request plus the time it takes to create and delete processes. As expected, the thread-based optimization techniques do better.
Using Bytewax
You can use Bytewax to more easily perform data processing using multiple processes, threads, or both. To do this, simply structure your desired transformations into a pipeline known as a Dataflow. You can install Bytewax using the command pip install bytewax.
Below is a simple example of a Dataflow object that can be used to obtain the frequency of words in some CNN news headlines:
import operator
from bytewax import Dataflow, run_cluster
def get_headlines(lines):
for i, line in enumerate(lines):
yield 1, line
def initial_count(word):
return word, 1
flow = Dataflow()
flow.map(str.lower)
flow.flat_map(str.split)
flow.map(initial_count)
flow.reduce_epoch(operator.add)
flow.capture()
flow.inspect(print)In the above code, you import the operator module and the Dataflow() and run_cluster() methods from bytewax. Next, you define a generator named get_headlines() to output each headline. This generator produces a tuple consisting of 1 (the epoch) and the headline. You then define a simple function to instantiate the word count. This function returns the word in a tuple along with its initial count of one.
A Dataflow object is created and several transformations are added. The first one changes the string’s case to lowercase. To accomplish this, the flow.map() method receives the str.lower() method as a parameter. The str.split() method is similarly parsed into the flow.flat_map() method, which releases each element in the resulting iterator separately. To initialize the count, the flow.map() method is called once more.
You also parse the operator.add() method to the flow.reduce_epoch() method to aggregate the word counts. Finally, to specify the output and show the word counts, flow.capture() and flow.inspect() are called.
You can run the Dataflow pipeline on some input as shown below:
if __name__ == "__main__":
headlines = [
'How Redbox became a Wall Street darling once again',
'Ex-Trump adviser calls for lifting Trump tariffs on China',
'Netflix lays off 300 employees as bad year continues to hit company',
'She has visited every country in the world. Here is what she learned',
'Five guys take the same photo for 40 years',
'What it is like to sit in a double-decker airplane chair',
'Confessions of a 1980s flight attendant',
'Sign up for our 9-part Italy travel and food newsletter',
]
result = run_cluster(flow, get_headlines(headlines), proc_count=2, worker_count_per_proc=2)In the above code, the run_cluster() method is called and you define the list of headlines. The flow object, input generator, number of processes, and threads per process are all passed as arguments. The word counts are generated after the script is run:

Conclusion
Despite its seemingly restrictive setup, Python works well with multiple forms of parallelization. You can use this method to break down complex processes in various ways, including multiprocessing and multithreading, to speed up your execution and save on both time and resources.
There are also tools to help you accomplish parallelization more easily and efficiently. Bytewax is an open source Python framework that enables you to create scalable dataflows that can be run on multiple processes or threads. This means that you can run parallelization using your machine’s multiple cores or a distributed system of multiple machines. For more details and examples, see the documentation.
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.

Fortune Adekogbe
Technical WriterFortune is a community guest writer. <a href="https://www.linkedin.com/in/fortune-adekogbe-a81580176/" target="_blank">LinkedIn</a>

