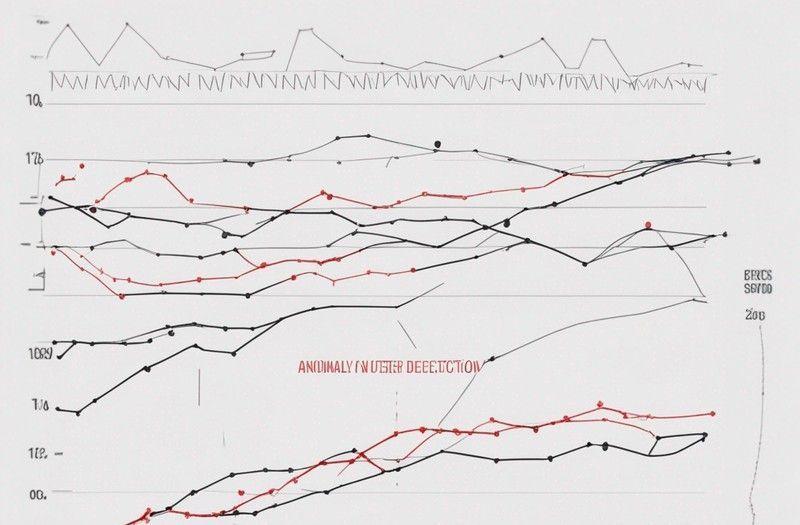
Online Machine Learning in Practice: Interactive dashboards to detect data anomalies in real time
Redpanda, River, Rerun powered by Bytewax
Written by Oli Makhasoeva & Zander Matheson
If you prefer videos check out Zander's talk at Data Council 2023 "When to Move from Batch to Streaming and how to do it without hiring an entirely new team".
The world of data processing is undergoing a significant shift, moving towards real-time processing. Despite an increase in understanding that shifting workloads to real-time can increase ROI and lower costs, there isn’t consensus in the industry around how to best transition workloads to real-time and what the best tools are for different types of real-time workloads. While traditional analytical tools such as data warehouses, business intelligence layers, and metrics are widely accepted and understood, the concept of real-time data processing and the technologies that enable it are not as widely recognized or agreed upon.
In this post, we aim to demystify real-time data processing, discussing its relevance within an organization, the different types of real-time workloads, and some real-world examples from my time at GitHub. But first, let's clarify some definitions.

What is Real-Time? "Real-Time" refers to anything that is perceived to happen in real time by a human - an admittedly fuzzy definition. Quantitatively, this usually refers to processes that happen in the sub-second realm. Interestingly, based on this definition, real-time data processing can actually occur with both batch and stream processing technologies depending on the end-to-end latency.
Stream processing refers to processing a single datum at a time, flowing in a continuous stream, while batch processing is when you gather a batch of data and process it all at once. By reducing the size of the batch progressively, we can edge closer to real-time processing. This is precisely what technologies like Spark's structured streaming do with micro-batches.
Now that we have some definitions out of the way, let's dive into real-time processing and the different types of real-time workloads.

In our day-to-day lives, we're constantly receiving and processing information in real-time. Consider driving a car - an activity that requires processing multiple inputs and making decisions in real-time. If we were to approach driving in a batch processing manner, waiting to gather information for a duration and then trying to forecast the next 15 seconds, it would likely end in disaster. As another example you can imagine a sport like basketball. For each moment in time, the players are receiving tens or hundreds of inputs and they are reacting to them in real-time. If we also imagined a non-real-time version of this, it might not be so exciting to watch or play as each player waited for a certain number of seconds while receiving input and then tried to react to those inputs.
These examples help to highlight why we might choose to process things in real-time. In the context of driving, we're making decisions that could potentially be a matter of life or death. And in our basketball example, the real-time processing elevates the user experience. However, while these examples provide some understanding, they don't necessarily help us generalize the concept.
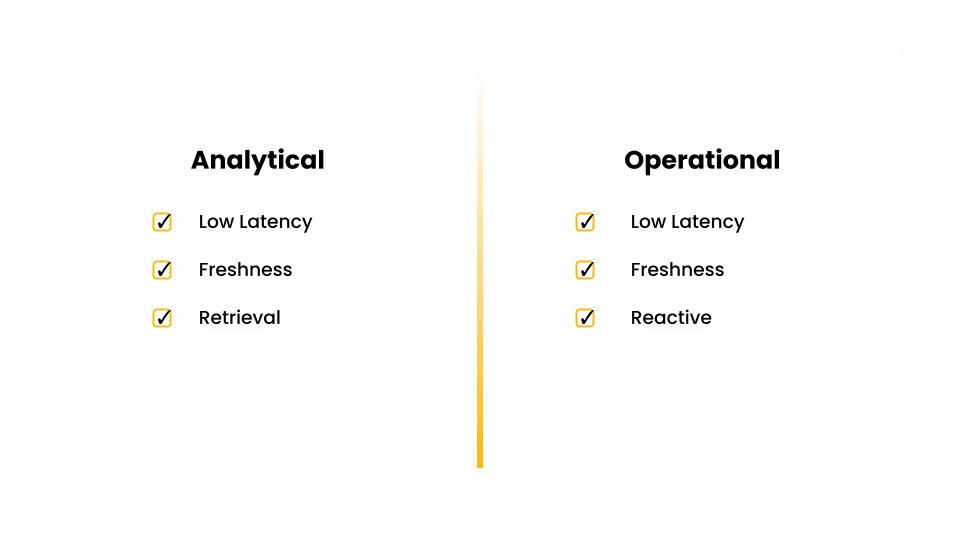
We can broadly categorize real-time processing into two types of workloads: analytical and operational.
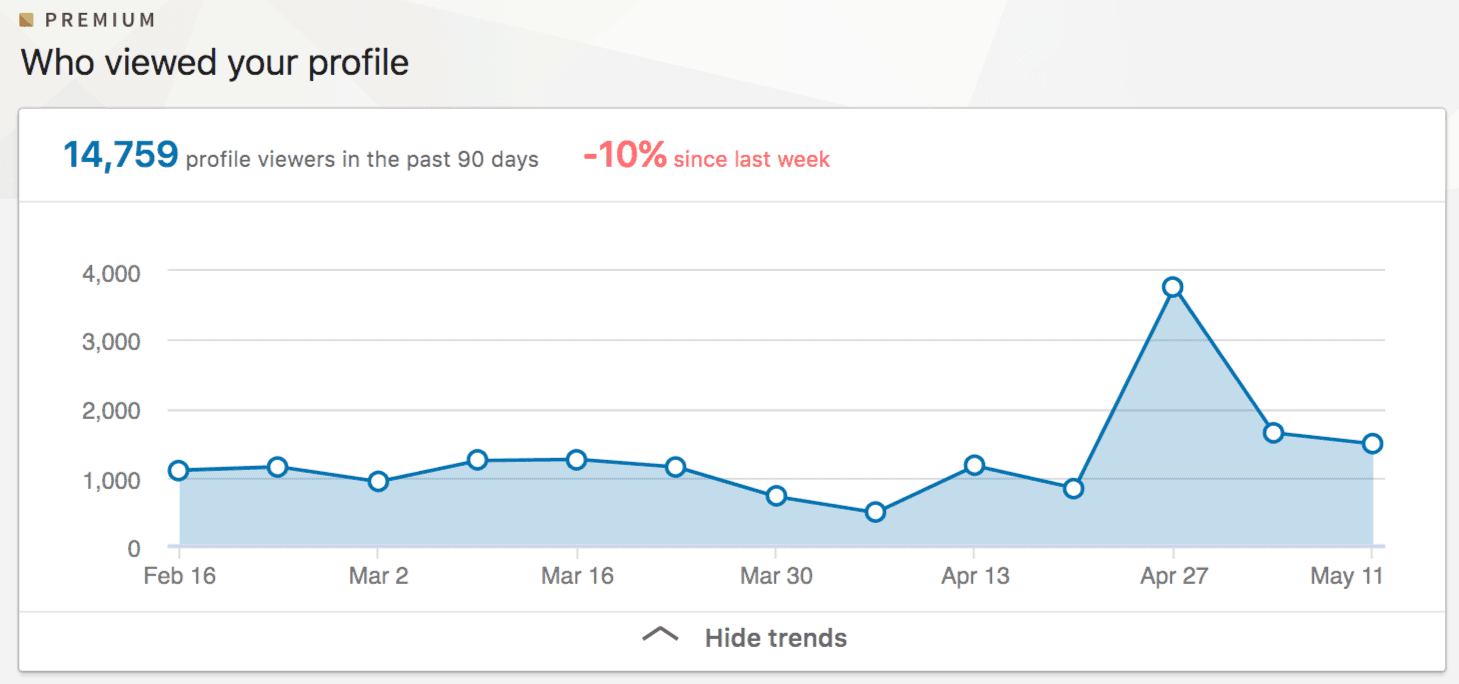
Analytical workloads require low latency, freshness, and the capability of retrieval at scale. Real-time analytical workloads must be queryable. A good example of this is LinkedIn's profile view notification. When you click into the profile view notification, you're taken to a page that shows your profile views history, all the way up to the most recent data. This demonstrates the freshness of data and the ability to query it as you can filter and interact with the data, querying the freshest data.
Another example of a real-time analytical workload is an Instacart order. When you place an order on Instacart, you can go into your order and see the updated Estimated Time of Arrival (ETA). This is another instance of an analytical real-time workload where the user is interacting with analytical data in real-time.
On the other hand, operational workloads, require low latency and freshness, but they also need to be reactive. This means that some of the decision-making or business logic is embedded inline in the system. For example, in a streaming use case, this would be inside the stream processor. The data is received, transformed, and then a decision is made in an online fashion. Bytewax is a great example of a framework that can be used to make real-time decisions for operational workloads.
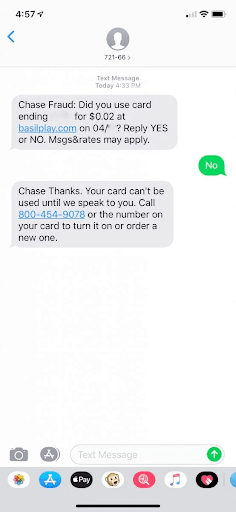
A good example of operational processing is fraud detection. The fraud detection system takes all the inputs in real time and makes a decision about them without a human in the loop. It then makes a decision on what to do and communicates with the user to confirm if its suspicion of fraud is correct.
Another example in financial markets is high-frequency trading. The software system consumes inputs from a variety of different data sources, processes them in real time, and then makes a decision whether to buy or sell. The speed of making that decision is a key factor in this context.
One more aspect I wanted to touch on here is the difference between having a human in the loop versus having a machine in the loop. If we look at different examples across analytical and operational workloads, there's a concept of the human being more involved in the analytical and less or not involved in the operational.
To summarize, if there is a situation where you believe there's value to be derived and there's a human in the loop, there's probably a subset of tools within the real-time space that fall under the analytical workload. If you're building something like an algorithmic trading system, where you believe that there's no requirement for a human in the loop, you're more likely to fall under the operational category, and you should look at tools, like Bytewax, that support operational processing.
Let's make things more concrete by discussing a couple of case studies involving decisions we made at GitHub concerning real-time data processing.
The team I was a part of at GitHub was responsible for several data products that were featured on github.com, including Trending Repositories and Trending Developers. These features were located on the GitHub Explore page and aimed to identify trending repositories and developers based on a variety of metrics, such as stars, forks, and views. We had access to this data in real time through a streaming platform (Kafka) managed by another team.
Although we had the capacity to implement these as real-time features, we decided against it. Our team primarily consisted of data scientists and machine learning engineers who hadn't worked with streaming platforms or stream processors before. Moreover, these features were new products, and we didn't know how impactful they would be or whether users would find them valuable and engage with them repeatedly.
Instead of implementing these features to use real-time data, we decided to process this data in a batch format. We would run nightly queries against Presto, where the data landed from Kafka, then store the processed data in a MySQL database for retrieval from github.com. These features were not real-time workloads, but they could have been. If it was determined they would be useful as real-time data products, they would serve as excellent examples of analytical use cases.
Another task we undertook was star spam detection. The concept of "stars" on GitHub repositories is used as a proxy to gauge the health and utility of the project. If we were unable to detect star spammers, it would degrade the platform's value for users, potentially leading to a downward spiral in the platform's overall value.
We decided to tackle this problem in a real-time manner to limit the exposure of the users and potential degradation of the platform from star spam. The data was available in Kafka and could therefore be consumed as it was available. Based on certain criteria, users could be flagged as spammers and then action taken. Once a user was flagged, they were submitted for human review to decide on what the next steps should be. This is an excellent example of operational processing.
The point is that the decision to implement real-time processing can have significant impacts on the return on investment for a project, and this correlation should be carefully considered. If we had decided to make the trending feature real-time, it would have been even more necessary to maintain the platform's value by detecting star spam as close to real-time as possible.
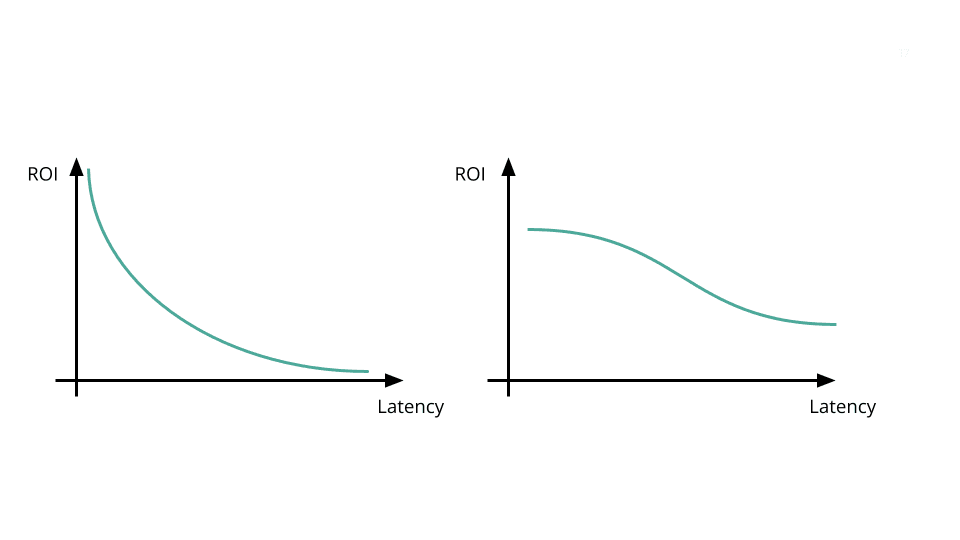
The value of data often degrades over time, and while it's usually depicted as a sharp decline (see graph on the left), most projects or data tend to follow more of an S-curve (on the right). After a certain point, the return or value of the data caps out with respect to latency. In these case studies, neither project saw an exponential increase in return on investment as latency was reduced, and we were able to tackle star spammers on an hours timeframe instead of milliseconds. This demonstrates that not all data projects need to move towards zero latency to provide significant value.
If you are interested in moving some of your workloads to real-time and not sure where to start. Please reach out to us in our slack channel and we would be happy to help you figure out if the value is there and where to start.


