{kind=link}


About five years ago, our founder Zander Matheson was working at GitHub, where his team was tasked with building and maintaining the machine learning infrastructure for a critical product feature—one that relied heavily on real-time data. The catch? They were forced to use legacy streaming tools designed during the Big Data era, built primarily for Java/Scala-focused data engineers. In an environment where rapid iteration and Python-based experimentation were essential for ML workflows, these constraints became a bottleneck.
The team faced relentless challenges: cumbersome setup processes, intricate configurations, and a steep learning curve that diverted focus from innovation. At the time, the term MLOps was just emerging, and while companies had started hiring AI/ML Engineers, the role of the MLOps Engineer was not yet widespread. Unsurprisingly, the tooling landscape hadn’t caught up with these hybrid roles.
This frustration sparked an idea: What if there were a tool that embraced Python-first development, flexibility, and simplicity for real-time data? That vision became Bytewax.
The tools of the big data era are powerful and battle-tested, but they were built for a different era and audience. As roles have evolved, so too must the tools they rely on.
The Growing Complexity of Data Roles
Why is there a shift toward new tools and skill sets? Because data-centric roles have evolved dramatically over the last decade.
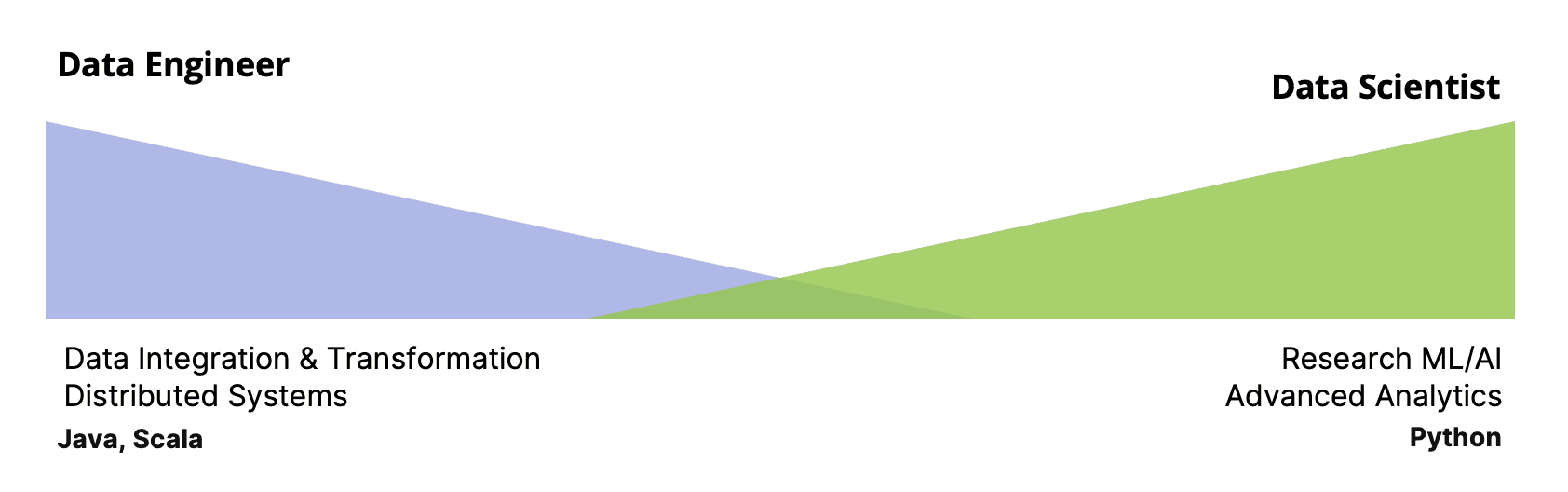
Big Data Era: Traditional Data Roles
In the Big Data era that started in the early 2010s, traditional data teams typically had two core roles:
- Data Engineers – Managing massive data pipelines, often using Java/Scala to orchestrate data flow in and out of systems.
- Data Scientists – Expert statisticians and modelers, usually working in Python or R to extract insights and build predictive models.
These distinct roles - with relatively little overlap between - made perfect sense in the era of “Big Data,” where the challenge was how to store, process, and retrieve large volumes of data reliably.
Data Engineer
Data Engineers generally come from a strong software engineering background. Their primary mission? Design and build robust data pipelines that feed downstream systems. They’re the unsung heroes who know how to juggle distributed frameworks, databases, and messaging systems.
| Core Skills | Key Responsibilities |
|---|---|
| - Proficiency in Java, Scala, SQL and sometimes Python - Deep understanding of distributed systems and big data tech (Spark, Kafka, Flink, etc.) - Expertise in data integration and transformation - Familiarity with data governance and best practices | - Designing and developing scalable data pipelines - Integrating big data tools to address business use cases - Ensuring data efficiency and reliability - Setting up proper ETL/ELT workflows |
Data Scientist
Data Scientists, on the other hand, focus on extracting insights from raw data. Armed with Python, they apply statistical modeling and machine learning techniques to forecast trends, identify patterns, and deliver actionable recommendations.
| Core Skills | Key Responsibilities |
|---|---|
| - Statistical analysis and machine learning know-how - Data visualization and “data storytelling” - Advanced programming (Python) for analytics - Strong analytical and problem-solving abilities | - Designing predictive models and experiments - Interpreting complex datasets - Presenting insights to stakeholders - Ensuring model robustness and reliability |
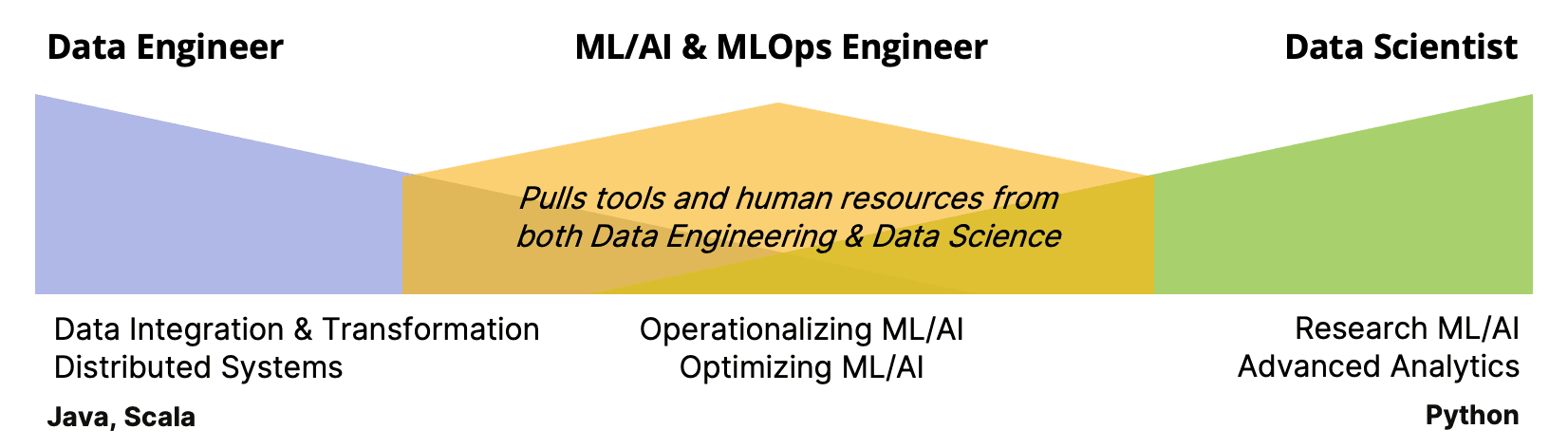
The AI/ML Era: Hybrid Roles Emerge
As AI and ML models moved into production, new challenges emerged: How do you train, deploy, and monitor models in real time using both Data Engineering and Data Science skill sets? To address these challenges, the ML/AI Engineer role emerged around 2015, followed by the MLOps Engineer role around 2019—both positions blend pipeline expertise with the training and deployment of ML models.
ML/AI Engineer
An ML/AI Engineer works at the intersection of data science and software engineering. They make ML models not just feasible but deployable at scale, ensuring models are optimized, tested, and ready to handle real-world data.
| Core Skills | Key Responsibilities |
|---|---|
| - ML frameworks (TensorFlow, PyTorch) - Feature engineering and data preprocessing - Proficiency in Python (and sometimes C++/Rust for performance-critical parts) - Distributed computing for large-scale training - Familiarity with real-time data pipelines | - Designing, training, and optimizing ML models - Experimenting with algorithms and feature sets - Collaborating with data engineers to integrate models - Building scalable solutions for model deployment |
MLOps Engineer
The MLOps Engineer role takes DevOps principles—CI/CD, containerization, monitoring—and applies them to the ML lifecycle. They ensure models are deployed seamlessly and remain healthy post-deployment, which can include retraining when data or model performance shifts.
| Core Skills | Key Responsibilities |
|---|---|
| - CI/CD for ML deployment - Cloud platforms (AWS, GCP, Azure) - Container orchestration (Docker, Kubernetes) - Python + ML frameworks - Monitoring & metrics tracking | - Deploying models with minimal downtime - Setting up automated pipelines - Monitoring performance - Triggering retraining or rollbacks |
Why New Tools Are Necessary
AI/ML and MLOps Engineers overlap heavily with both Data Engineers and Data Scientists. They need:
- Software engineering proficiency to build robust, scalable systems,
- Statistical/ML expertise to craft effective models, and
- Automation skills to streamline deployment and monitoring.
Yet in the Big Data era, data engineering and data science used separate toolstacks: Java/Scala on one side, Python/R on the other. Data Engineering tools like Flink or Spark are extremely powerful, but their complexity often acts as a barrier for teams whose core expertise (and favorite language!) is Python.
This creates demand for tools that combine the simplicity and flexibility of Python with the processing capabilities once exclusive to heavy-duty Java/Scala-based systems.
The Rise of Python-Centric Tools
A new wave of tools is emerging to empower developers working in AI/ML(Ops). These tools aim to bridge the gap between Python’s simplicity and the demanding performance requirements of production-grade ML systems. Three distinct architectural approaches are gaining traction:
- Extending Legacy Big Data Platforms: Many legacy "Big Data" era tools retrofit existing Java/Scala-based systems (e.g., Apache Spark, Flink) with Python APIs. While practical, this often introduces JVM-related complexities and overhead.
- Native Python with High-Performance Engines: Frameworks like Dask, Polars or Ray embed high-performance engines (written in C++/Rust) under Python abstractions, bypassing the Global Interpreter Lock (GIL) to achieve parallelism without sacrificing developer ergonomics. Bytewax with its Rust engine sits in this category.
- Hardware-Acccelerated Python: Libraries like CuPy, cuDF, and Numba leverage GPUs directly, while tools like ONNX Runtime optimize models for specialized hardware such as TPUs—significantly enhancing Python’s performance capabilities.
This reflects a broader shift toward enabling Python developers to build scalable ML systems without sacrificing performance or productivity.
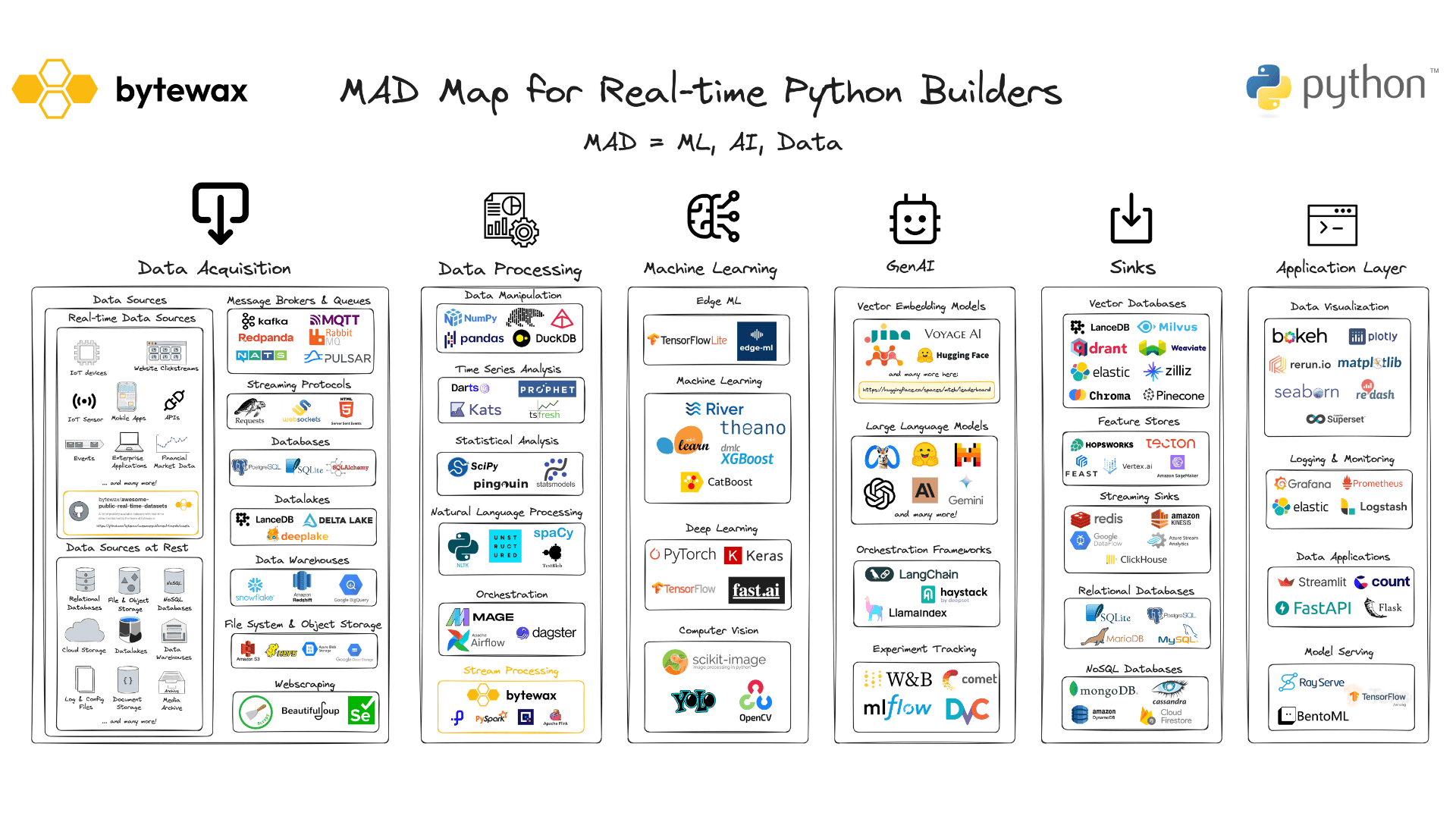
As Python cements its role as the lingua franca for data science, machine learning, and AI, it also brings a robust ecosystem of compatible tools spanning the entire workflow—from data from ETL to AI/ML application development. We took a deep dive into these offerings in our Bytewax MAD Map, which provides an extensive overview of the Python ecosystem for data, analytics, and AI/ML.
Who Uses Bytewax?
From Bytewax’s first launch, our vision was to:
- Be Python-First, Developer-Friendly
Help ML/AI Engineers, MLOps Engineers, and Data Scientists feel at home—no more jumping between Java and Python. - Get to Production, Fast
Real-time data workloads should be quick to prototype and easy to scale. - Low Maintenance, High Value
Reduce the heavy ops overhead traditionally needed for stream processing.
Have we succeeded? Our community survey shows a developer mix from data engineering to AI/ML(Ops) and data science.
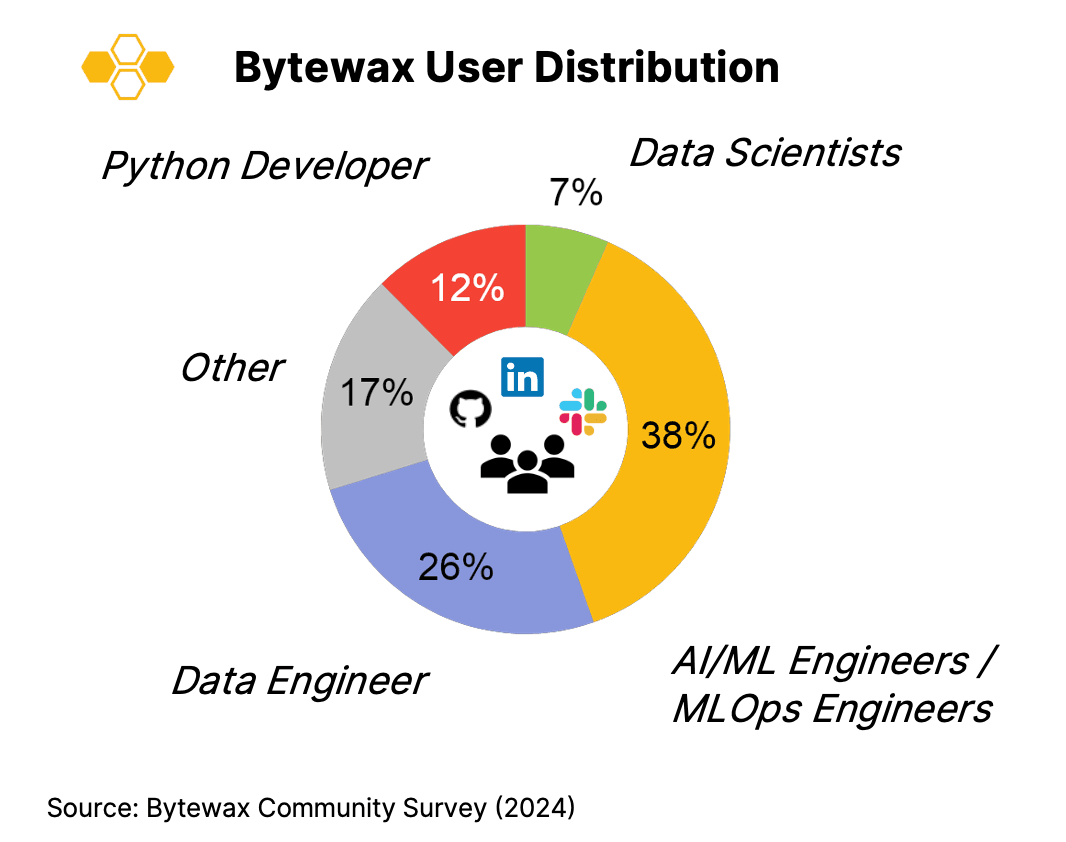
Bytewax naturally appeals to those who need to handle real-time data in a Pythonic environment—especially those bridging the gap between pure data science and operational ML. Of course, Bytewax isn’t just for AI and ML; it can be used for almost any real-time use case.
Final Thoughts
The data landscape is changing fast. Roles like ML/AI Engineer and MLOps Engineer are becoming standard for pushing ML from experiments to production-grade systems. The Big Data tools of the past served us well, but we need software built for speed, simplicity, and agility.
That’s why Bytewax was born: to empower modern data teams—those who prioritize real-time, Python-driven, and production-ready capabilities. It’s time to stop fighting the old ways and start embracing tools designed for the future of data and AI/ML.
Ready to check Bytewax out? Learn more here or visit our GitHub repo. We’d love to have you join our community—whether you’re a Data Engineer, Data Scientist, ML/AI Engineer, MLOps Engineer, or something entirely new.
Thanks for reading, and welcome to the evolving world of data roles—where the lines blur, the pace quickens, and the tools get better every day.
How Bytewax Beats Flink in Efficiency, Cost, and Ease of Use

Jonas Best
Chief of StaffJonas brings extensive experience from Accenture and Monitor Deloitte, where he managed projects at the intersection of technology and business. Before joining Bytewax, he attended business school at the University of St. Gallen and HEC Paris. He is crucial in coordinating Bytewax's strategic efforts and ensuring seamless operations.
The Evolution of AI Agents: Architectures, Durability, and Caching
Other posts you may find interesting
View all articles
Integrating Bytewax with SingleStore for a Kafka Sink
A step-by-step guide to using Bytewax to move Kafka data into SingleStore efficiently.
Written by Zander Matheson & David Selassie