
How We Found 10x Performance While Reducing CPU Consumption in Bytewax v0.17
By Federico Dolce
Bytewax has just released version 0.17, and with it comes a host of exciting features and performance optimizations. In this article, we will delve into the performance improvements made since version 0.16.
Please note that the performance metrics discussed here are based on benchmarks designed to highlight significant changes between versions. While they offer valuable insights, absolute numbers should be interpreted with caution. We plan to work on a benchmark suite to compare Bytewax with other tools, but for now, our focus is on showcasing the progress made within Bytewax itself. All the benchmark are ran on a laptop with a i7-11800H and 64GB of RAM.
Addressing High CPU Usage in Input Connectors
One of the primary issues we tackled was the high CPU usage observed in our input connectors. In Bytewax, it's crucial that input operators return as quickly as possible to prevent blocking other operators within the same thread. To address this, we implemented a polling mechanism that continuously requests data, ensuring that no idle time was wasted.
However, this approach led to excessive CPU consumption when no other work was available. To mitigate this, we introduced a cooldown period, adding a maximum delay of 1 millisecond between polling requests if there was no data in the previous iteration. This small adjustment significantly improved CPU efficiency without visibly affecting latency. We proved this by building a set of benchmarks, and comparing three metrics: real, user and system times, as reported by hyperfine with bytewax 0.16 and the version with this fix included.
The plot of the benchmark looked something like:
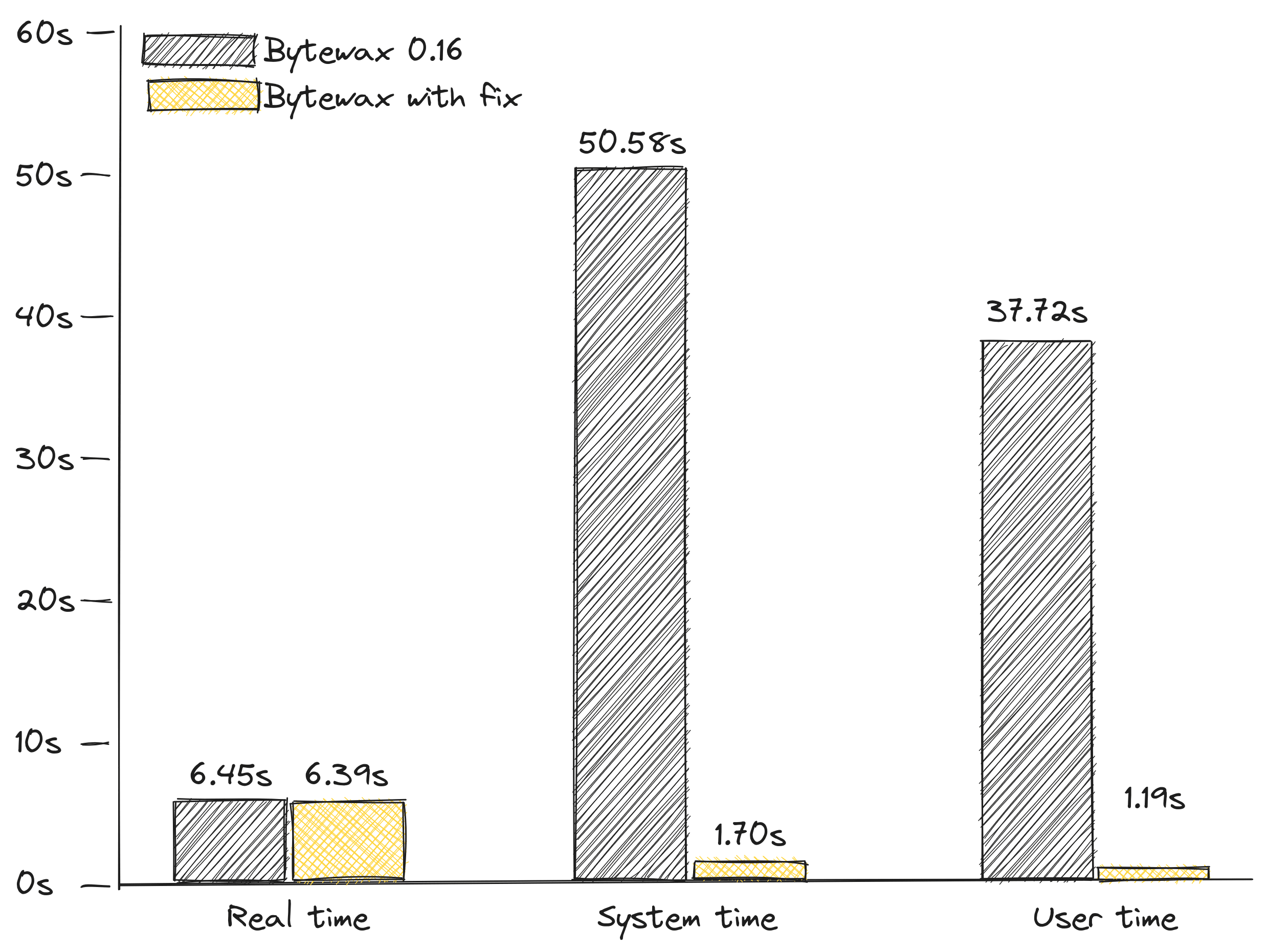
The real execution time remained the same (within the error margin of the measurements), but the total time spent in the CPU went drastically down. This specific benchmark emphasized a particularly bad scenario, other benchmarks showed a milder improvement, but the situation was consistently better with the fix than without.
Introducing next_awake for Input Sources
While the previous optimization improved performance, we identified an underlying issue: input sources lacked a mechanism to express when they should be awoken next. Although it was possible to implement this logic manually in Python input sources, it wasn't straightforward, and doing it at the library level allowed us to reduce unnecessary calls to Python code.
To address this, we introduced a next_awake method for both StatelessSource and StatefulSource. This new feature allows sources to explicitly signal when they should be awoken next. Bytewax ensures that the next method won't be called before the specified next_awake time, although runtime scheduling may cause a slight delay of around 1ms. For those who prefer the previous behavior of polling as fast as possible, they can just return datetime.now(tzinfo=timezone.utc) in next_awake.
Addressing a Kafka Throughput Regression
A noticeable regression in Kafka throughput emerged when one of our users was transitioning from Bytewax version 0.10 to 0.16. He had a dataflow running in production on Bytewax 0.10, and experienced significant issues when porting his dataflow to 0.16. While the original dataflow smoothly handled approximately 3,000 messages per second from multiple Kafka topics, the updated version struggled to keep up. Data began accumulating in the queue, eventually causing the dataflow to crash reaching the limit of available memory in the container.
The discrepancy in throughput was attributed to differences in default configurations. The old dataflow, which used a custom input source built with kafka-python, batched messages in the consumer to minimize I/O, while our new KafkaInput connector, built on confluent-kafka, read messages one at a time. While this reduced the delay between a message being added to a topic and its entry into the dataflow, it negatively impacted throughput, as the consumer had to make a request for each message.
Turning a Performance Regression into a 10x Performance Boost
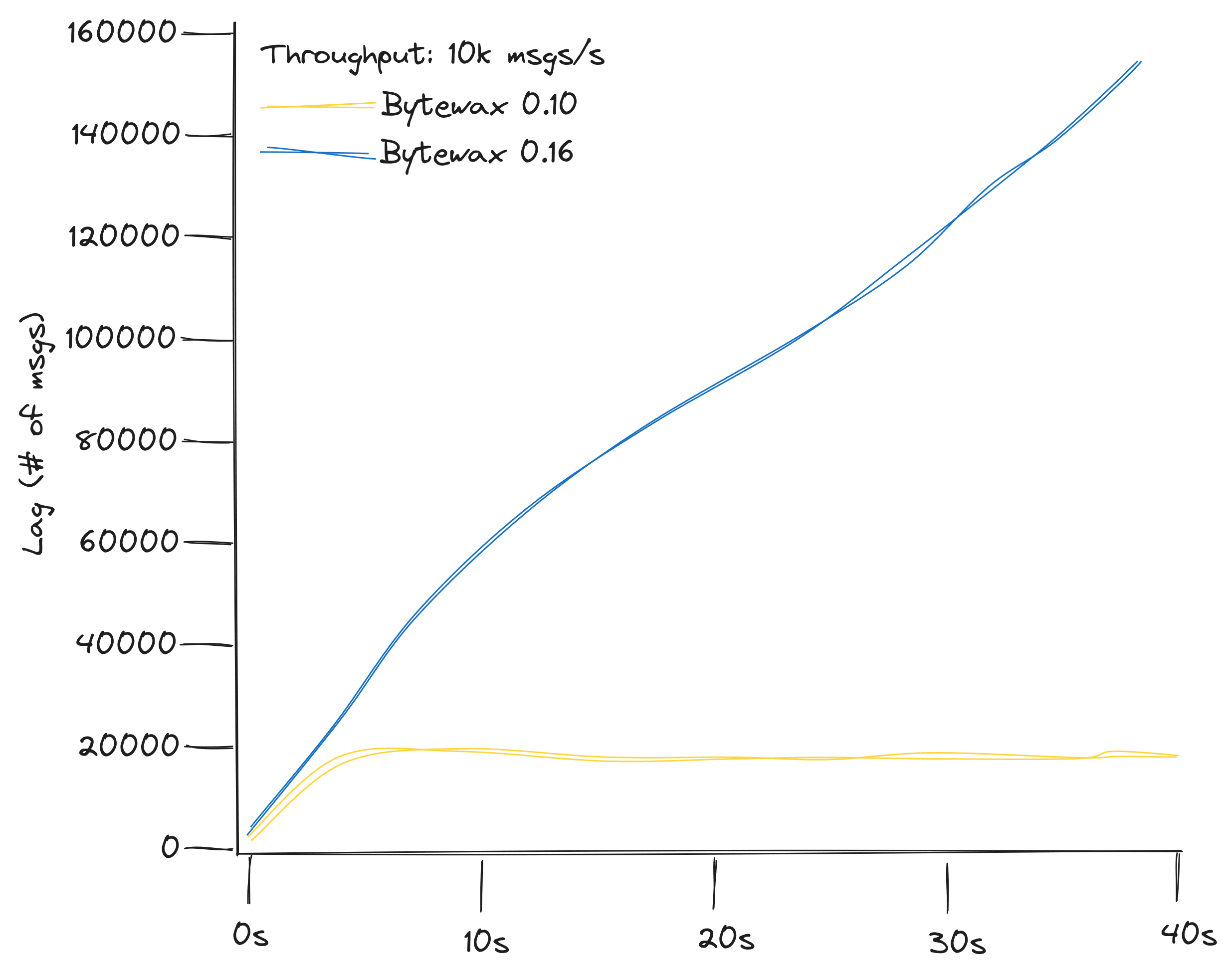
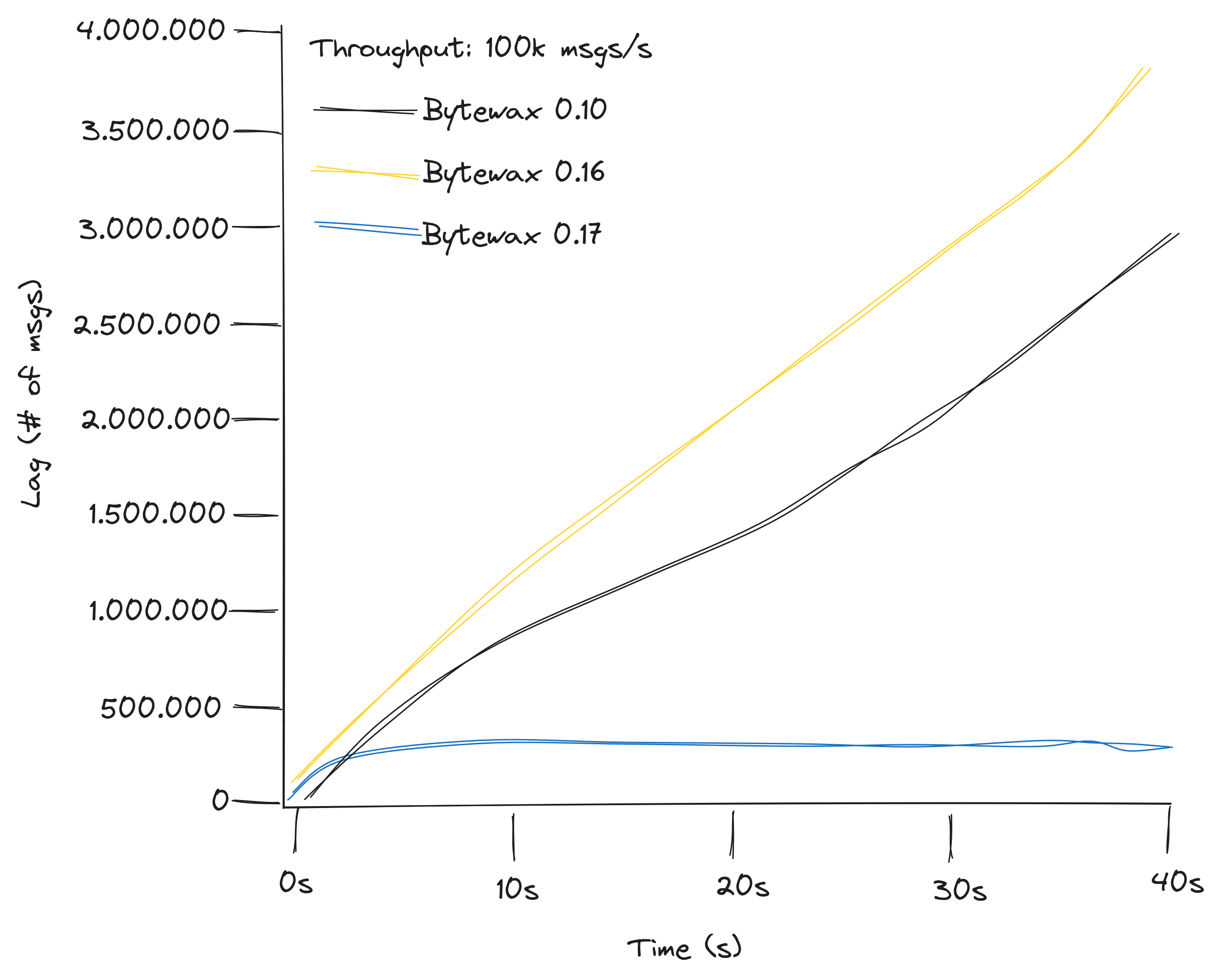
To address the throughput discrepancy, we conducted benchmark to compare the performance of Bytewax 0.10 with the custom input operator against Bytewax 0.16. The benchmark measured the number of unread messages in a Kafka topic (lag), providing valuable insights into the dataflow's ability to keep up with the incoming message rate.
Optimizing Batching for Input and Output
Our findings indicated that Bytewax 0.10, with the custom input operator, could handle 10,000 messages per second, whereas the new connector in Bytewax 0.16 struggled with just 2,000 messages per second. The benchmark measured the number of messages not yet read on a kafka topic (lag), with a producer generating a fixed number of messages per second to the topic, and it looked like this:
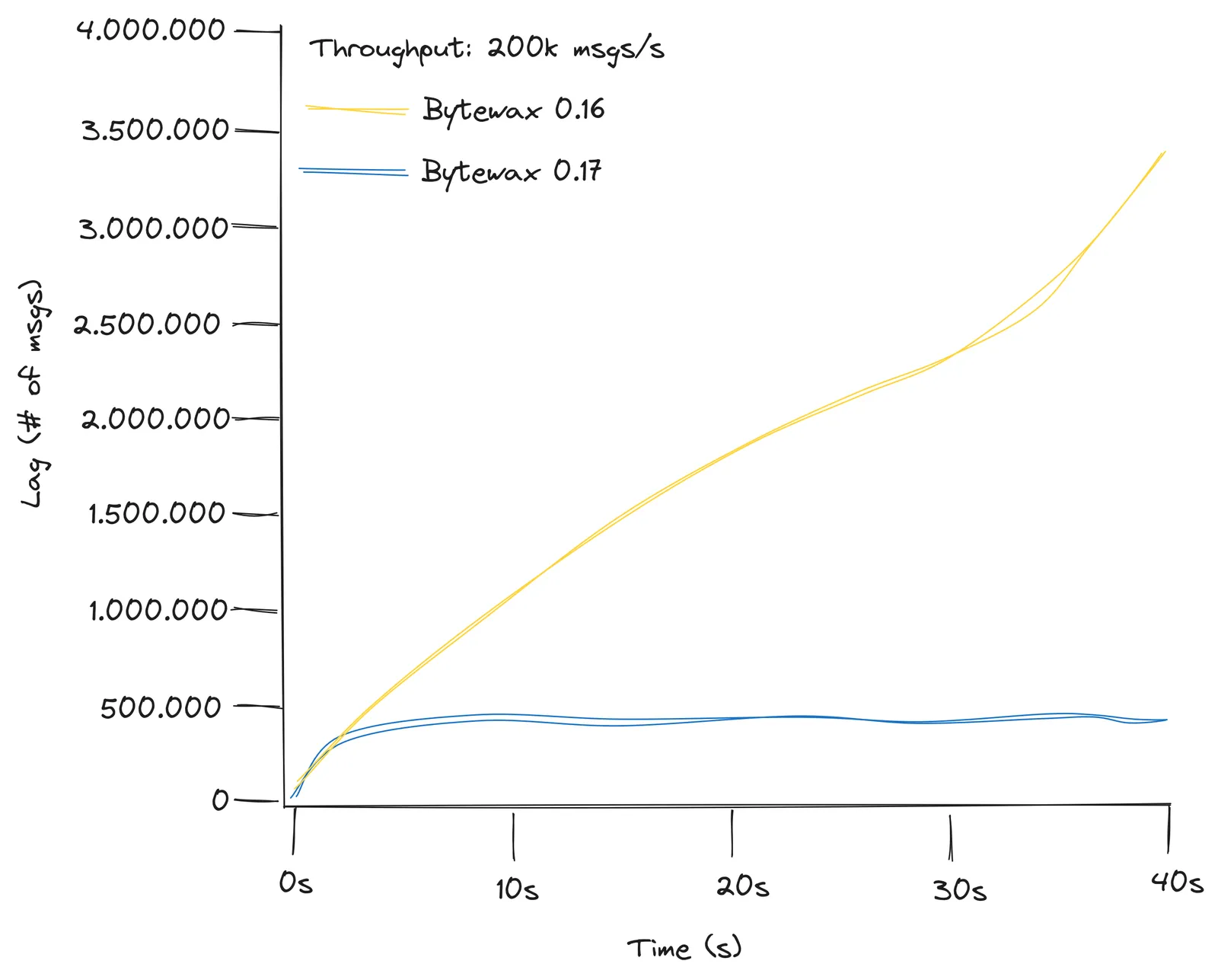
To resolve this issue, we allowed input sources to return a list of items rather than a single one. Additionally, we modified the KafkaInput to batch messages in the background. This enabled the new input operator to handle 200,000 messages per second:
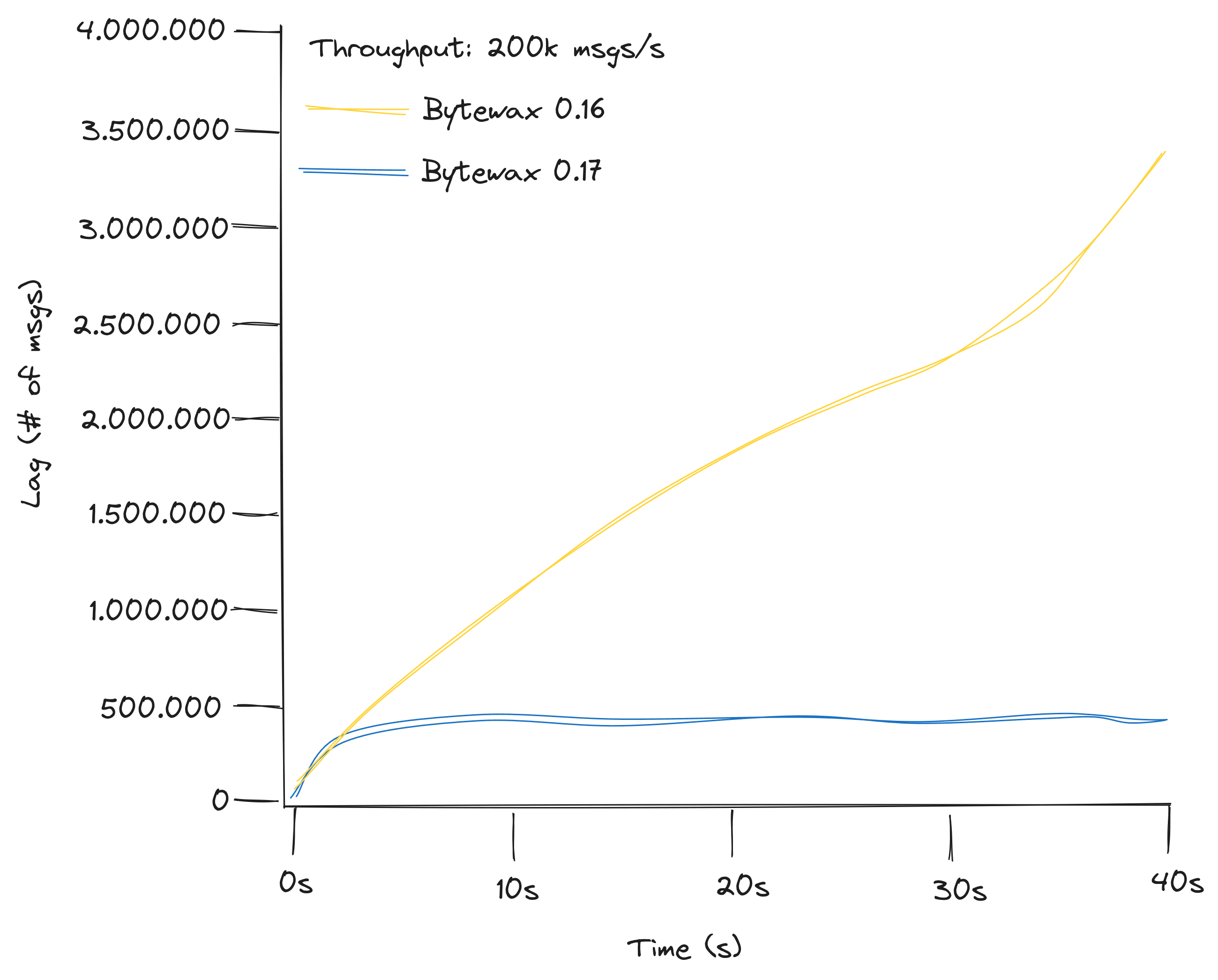
Thoe benchmarks where only stressing KafkaInput. We also addressed similar batching concerns on the output side, ensuring that StatelessSink and StatefulSink could be passed a list of messages instead of a single one. KafkaOutput now flushes messages at the end of each batch, rather than for each individual message. With these improvements, a Bytewax dataflow using KafkaInput and KafkaOutput with appropriate settings can now efficiently handle more than 100,000 messages per second in a single-topic, single-partition, single-worker configuration. While further enhancements are possible, this is a already much better than it was in both 0.16 and 0.10. If greater throughput is required, increasing the parallelization level remains an option.
In conclusion, Bytewax 0.17 represents a significant step forward in terms of performance improvements. These optimizations not only enhance the efficiency of input connectors but also address throughput regressions and batching concerns. As we continue working and benchmarking, we look forward to further enhancing Bytewax's performance and delivering an even more robust streaming platform for our users.
Stay tuned for more updates, and don't hesitate to explore Bytewax 0.17 to experience these enhancements firsthand.
If you want to support Bytewax, give us some ⭐ love on GitHub. If you are already building with Bytewax, jump in the Slack and share what you are building!
Hacker News From Request to Stream: A Deep Dive into How to Use Bytewax to Poll HTTP Endpoints to Create a Real-Time Stream of Data

Federico Dolce
Software EngineerAll-around software developer, Federico started his career as a backend Python developer. He later worked on frontend, mobile and game development, and became interested in DevOps and k8s.

