

Uses Bytewax Version 0.8.0
In this blog post, we will take streaming JSON event data and put it in partitioned Parquet files in 15-minute intervals by taking the following steps:
- Define our collection time interval
- Parse the JSON and add partition columns
- Accumulate the events
- Write the events to partitioned Parquet Files
In this tutorial we will also introduce the concept of grouping our data so we can easily scale this code to run on multiple on workers.
Want to skip and go straight to the code? repo
What is Bytewax?
Bytewax is a dataflow stream processing framework that allows you to process data in real-time with Python. Bytewax is open source and is built on top of the Timely Dataflow execution framework.
Let’s break that down.
A dataflow is a set of operators that act on data and can be described in a directed graph. A dataflow is highly paralellizable in nature because the operators act independently on the data flowing through the system. This allows for awesome throughput.
Operators are the processing primitives of bytewax. Each of them gives you a "shape" of data transformation, and you give them functions to customize them to a specific task you need. The combination of each operator and their custom logic functions we call a dataflow Step.
Prerequisites
Before getting started, make sure you have the following python packages installed as defined in the requirements.txt file shown below. We recommend using a new python virtual environment when getting started with Python 3.7 or greater.
pyarrow
pandas
bytewax==0.8.0
fake_web_eventsConsuming Events with Bytewax
Let’s start with a set of events. For this example, we mock a stream of events using the python library fake web events.
from fake_web_events import Simulation
import json
# use the user pool size, sessions per day and the duration to
# create a simulation size that makes sense
def generate_web_events():
simulation = Simulation(user_pool_size=5, sessions_per_day=100)
events = simulation.run(duration_seconds=10)
for event in events:
yield json.dumps(event)We can use the Bytewax library to consume these events as an input to our dataflow. In our case, we want to batch these events before we write them to avoid the problem of having too many small Parquet files.
For this example, we are making a Parquet file of events every 15 minutes. In order to do this with Bytewax, we leverage the concept of epochs and use the tumbling_epoch method. Epochs allow us to collect data for a defined period of time. In this case, every 15 minutes.
from bytewax import inp
inp.tumbling_epoch(900.0, fake_events.generate_web_events())Now this generator is ready to be used with a dataflow.
Constructing a Bytewax Dataflow to Convert to Parquet
To start, we instantiate the Executor and then create a Dataflow object which we will be assigning our dataflow steps. Our Dataflow takes the input generator we created above.
import bytewax
from bytewax import inp
ex = bytewax.Executor()
flow = ex.Dataflow(inp.tumbling_epoch(5.0, fake_events.generate_web_events()))Now that we have defined our dataflow, we can use Bytewax operators to define the steps we need to convert these into parquet files. We will write the following steps for our dataflow.
- Parse the input
- Format the data for partitioning downstream
- Reduce the data
- Write to Parquet
- Build and Run
The Dataflow can be explained with a directed graph.

In our first step, we are using the
mapoperator to convert the JSON event into a python object we can work with. If we had any other processing like flattening, we could do that following or in this step.flow.map(json.loads)In the next two steps, we are going to reformat our data. First we will add additional columns to our dataset that we will eventually use to partition the data when we write it to Parquet files. Then we will reformat it into a tuple of the format (
key,DataFrame) that we can use in the reduce step.flow.map(add_date_columns) flow.map(key_on_page)from datetime import datetime from pandas as pd def add_date_columns(event): timestamp = datetime.fromisoformat(event["event_timestamp"]) event["year"] = timestamp.year event["month"] = timestamp.month event["day"] = timestamp.day return event def key_on_page(event): return event["page_url_path"], pd.DataFrame([event])After the reformatting step, we are using the
reduce_epoch_localoperator to reduce the events with an aggregator function. This operator will maintain state over an epoch and will aggregate the data on each worker based on the key it receives. This is important for our file output as we want our partitioned events to be co-located on a worker. In our case the data received is in the shapeevent["page_url_path"], pd.DataFrame([event])that we created in the prior step. The result of thereduce_epoch_localoperator is of the format (key,aggregated_events) where theaggregated_events, in this case, is a pandasdataframeand thekeyis thepage_url_path.flow.reduce_epoch_local(append_event)def append_event(events_df, event_df): return pd.concat([events_df, event_df])Now that we’ve aggregated the events, we will use the
mapoperator and ourconvert_to_parquetfunction to convert our dataframes into Parquet files. Here we are converting the pandas DataFrame into a pyarrow table, and then using pyarrow’s parquet functionality to write out a dataset, which is a collection of files split on certain partitions to the$PWD/parquet_demo_out/with the partitions being sub directories.flow.map(write_parquet)from pyarrow import Table import pyarrow.parquet as pq def write_parquet(path__events_df): """Write events as partitioned Parquet in `$PWD/parquet_demo_out/`""" path, events_df = path__events_df table = Table.from_pandas(events_df) parquet.write_to_dataset( table, root_path="parquet_demo_out", partition_cols=["year", "month", "day", "page_url_path"], )Finally we give the
executorthe instructions to build and run our dataflow upon execution of the python file.if __name__ == "__main__": ex.build_and_run()
🎉 Putting it all together! 🎉
ex = bytewax.Executor()
flow = ec.Dataflow(inp.tumbling_epoch(900.0, fake_events.generate_web_events()))
flow.map(json.loads)
flow.map(add_date_columns)
flow.map(key_on_page)
flow.reduce_epoch_local(append_event)
flow.map(write_parquet)
if __name__ == "__main__":
ex.build_and_run()Now we can run our file as we would run a regular python file. 🎉
> python event_to_parquet.pyScaling to multiple workers
Bytewax files can be run as single-threaded dataflows, multi-threaded dataflows and multi-process dataflows. And it’s really simple to do so. In our case, we are writing python files for each epoch, partitioned by a certain key, which we have already specified in our dataflow. When we scale our dataflow to 3 workers, the directed graph would look like the one below. The data would be grouped on workers at the reduce step.
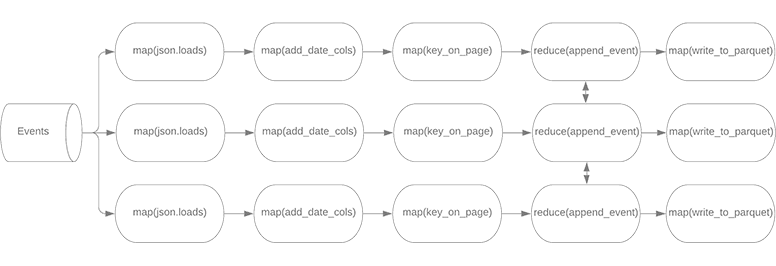
Running our dataflow again with 3 workers looks like the following.
> python event_to_parquet.py -w 3Takeaway
While there are many ways to turn streaming events into parquet files, the simplicity of Bytewax is unique as is the ability to leverage the Python tools lot of developers already know.
This template can be expanded to do additional processing on these events and can quickly scale to massive scale.
Have a streaming problem you want to solve? Reach out to us!
Stay updated with our newsletter
Subscribe and never miss another blog post, announcement, or community event.

Zander Matheson
CEO, Co-founderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

