
Scaling Bytewax with Ray: Running Bytewax Dataflows Across Multiple Ray Workers
By Zander Matheson

At Bytewax, we’re always looking for ways to enhance the scalability and performance of our data processing framework. In this post, we’ll explore how to leverage Ray, a high-performance distributed execution framework, to scale Bytewax dataflows across multiple workers.
With its unopinionated deployment story, Bytewax can also leverage Ray, similar to how we currently leverage Kubernetes.
Kubernetes and the Bytewax Platform remain the most powerful deployment methods enabling seamless scaling across many machines with governance and observability.
Why Bytewax on Ray?
If you haven't heard of Ray, it's an open source distributed compute framework developed to make it easy to scale Python workloads across multiple workers, specifically for AI workloads.
What makes Ray a popular choice for AI workloads?
Firstly, Ray provides a simple, universal API for building distributed applications. It allows you to scale your applications by distributing tasks across multiple nodes seamlessly, something that can be quite difficult, but necessary in ML workloads with high I/O and compute requirements.
Secondly, many ML and AI teams are divorced from their platform and infrastructure teams and are simply provided with a Ray cluster to support their compute needs. This infrastructure is available similar to how a kubernetes cluster might be available to application development teams. So you have to adapt to what you have at your disposal.
Let's take a look at how we can customize a Bytewax dataflow to run on a ray cluster.
Setting Up the Environment
First, ensure you have both Bytewax and Ray installed. You can do this using pip:
pip install bytewax==0.20.1 ray==2.32.0
Defining the Bytewax Dataflow
Let’s start by defining a Bytewax dataflow. This example demonstrates an anomaly detection system that processes metrics and identifies anomalies based on statistical properties.
We will define the dataflow in a function, so it could possibly be parameterized, but that isn't necessary, you could simply define the flow and pass that object to ray with instructions how to run it.
import ray
from dataclasses import dataclass, field
from typing import List, Optional
import bytewax.operators as op
from bytewax.connectors.demo import RandomMetricSource
from bytewax.connectors.stdio import StdOutSink
from bytewax.dataflow import Dataflow
# Define the Bytewax dataflow
def create_dataflow():
flow = Dataflow("anomaly_detector")
metric1 = op.input("inp_v", flow, RandomMetricSource("v_metric"))
metric2 = op.input("inp_hz", flow, RandomMetricSource("hz_metric"))
metrics = op.merge("merge", metric1, metric2)
# ("metric", value)
# redistribute the data randomly across the workers to show multiple processes
metrics = op.redistribute("distribute", metrics)
op.inspect_debug("dist", metrics)
# ("metric", value)
@dataclass
class DetectorState:
last_10: List[float] = field(default_factory=list)
mu: Optional[float] = None
sigma: Optional[float] = None
def push(self, value):
self.last_10.insert(0, value)
del self.last_10[10:]
self._recalc_stats()
def _recalc_stats(self):
last_len = len(self.last_10)
self.mu = sum(self.last_10) / last_len
sigma_sq = sum((value - self.mu) ** 2 for value in self.last_10) / last_len
self.sigma = sigma_sq**0.5
def is_anomalous(self, value, threshold_z):
if self.mu and self.sigma:
return abs(value - self.mu) / self.sigma > threshold_z
return False
def mapper(state, value):
if state is None:
state = DetectorState()
is_anomalous = state.is_anomalous(value, threshold_z=2.0)
state.push(value)
emit = (value, state.mu, state.sigma, is_anomalous)
# Always return the state so it is never discarded.
return (state, emit)
labeled_metrics = op.stateful_map("detector", metrics, mapper)
# ("metric", (value, mu, sigma, is_anomalous))
def pretty_formatter(key_value):
metric, (value, mu, sigma, is_anomalous) = key_value
return (
f"{metric}: "
f"value = {value}, "
f"mu = {mu:.2f}, "
f"sigma = {sigma:.2f}, "
f"{is_anomalous}"
)
lines = op.map("format", labeled_metrics, pretty_formatter)
op.output("output", lines, StdOutSink())
return flow
The above code is a pretty normal Bytewax code if you have worked with Bytewax before. One thing to note is that we have added a redistribute step to the dataflow. We will inspect the data right after this step to prompt the worker to show us what data it has.
metrics = op.redistribute("distribute", metrics)
op.inspect_debug("dist", metrics)
This is needed because our data comes from a single source, and we want to show the multiple ray workers coordinating on processing.
The final output from our dataflow will all come from the same worker in this dataflow because of the stateful_map step that requires all data with the same key to be on the same worker, otherwise our computations wouldn't be correct.
Integrating Bytewax with Ray
Next, we’ll integrate Bytewax with Ray to distribute the dataflow execution across multiple actors. There isn't much we need to do here actually 🙂. Ray makes this part pretty easy!
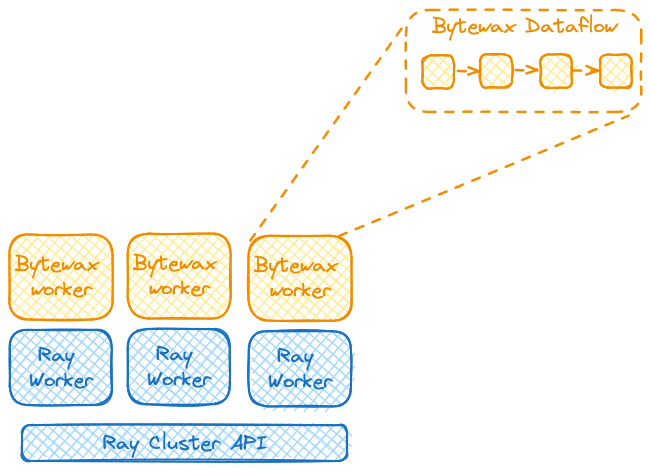
The diagram below depicts how this works to better understand it. We are starting Ray workers, who will each be a Bytewax worker, and the Bytewax worker run the data.
# Initialize Ray
ray.init(ignore_reinit_error=True)
# Define a Ray actor for Bytewax execution
@ray.remote
class BytewaxWorker:
def __init__(self, flow, proc_id, addresses):
self.flow = flow
self.proc_id = proc_id
self.addresses = addresses
def run(self):
from bytewax.run import cli_main
# start a Bytewax process with the defined args
cli_main(
self.flow,
addresses=self.addresses,
process_id=self.proc_id
)
# Create the Bytewax dataflow
flow = create_dataflow()
# This example assumes localhost
def _gen_addresses(proc_count: int): # -> Iterable[str]:
return [f"localhost:{proc_id + 2101}" for proc_id in range(proc_count)]
# Create and run Ray actors for Bytewax workers
num_workers = 2 # Number of Ray actors
addresses = _gen_addresses(num_workers)
workers = [BytewaxWorker.remote(flow, proc_id, addresses) for proc_id in range(num_workers)]
# This will run the ray workers
results = ray.get([worker.run.remote() for worker in workers])
Breaking down the Ray powered Dataflow
- Initialize Ray: Start Ray using
ray.init(). This sets up the Ray runtime environment. - Define a Ray Actor: Create a Ray actor class
BytewaxWorkerthat encapsulates the Bytewax dataflow execution. Therunmethod executes the dataflow using Bytewax’scli_mainfunction. - Create and Run Bytewax Workers Bytewax workers will run in each Ray Actor. We use
cli_mainto construct a cluster of Bytewax processes that are cooperatively working on the data. - Run Indefinitely: The workers run indefinitely, processing data and detecting anomalies in real-time.
Conclusion
That's It! We've shown you how to run Bytewax on a Ray cluster. By leveraging Ray, you can scale your Bytewax dataflows across multiple workers and even multiple machines, enabling efficient and scalable data processing.
If you liked this tutorial, feel free to give us a shout-out on social media or a ⭐️ on GitHub.
Building a ClickHouse Sink for Bytewax to Enable Real-Time Analytics

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

