

Real-time machine learning (real-time ML) is a subset of the broader machine learning category of applications that can make predictions in real-time or near real-time. This means that the models can process new data and make predictions on the fly, as opposed to batch processing, where after accumulating enough data, the data is processed and then the prediction is made. Real-time ML is core to things like conversational AI and human-like activities done by machines (self-driving, robotics etc.)
Applications
In addition, real-time machine learning can be a competitive advantage in situations where time is a driving factor in the relevance of the prediction coming from the model. It is considered table stakes in industries such as finance, healthcare, and transportation. For example, in finance, real-time ML can be used to detect fraudulent transactions as they occur, allowing for immediate action to be taken or it is used in high-frequency trading, where the time to decision is measured in a fraction of a second, faster than humanly possible (I like this framing by Sean Gourley). In healthcare, real-time ML can be used to monitor vital signs in real-time and alert medical staff to potential issues. And in transportation, real-time ML can be used to optimize routes for delivery vehicles in real-time, reducing fuel consumption and improving delivery times.
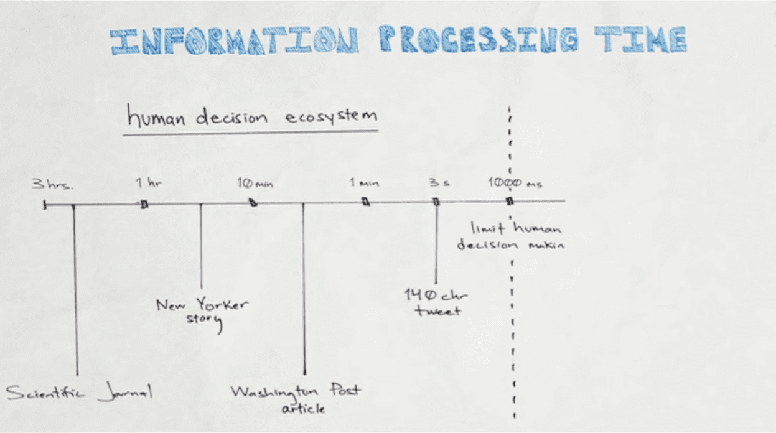 source: https://www.youtube.com/watch?v=V43a-KxLFcg
source: https://www.youtube.com/watch?v=V43a-KxLFcg
Approaches
Real-time machine learning can be facilitated through online learning, but also with more traditional approaches where the model is trained offline and then the data pre-processing and inference happens in real-time. A diagram of each of the approaches is shown below. Streaming processing is core to both of these approaches. Online learning, which we discussed in a prior post allows the model to update itself in real-time as new data is received, stream processing makes this possible by maintaining the model representation in memory and updating it with each new datum as shown in the diagram below, it is relatively straightforward, but is limited in the algorithms that can be used to train the model and provide good results. Live inference with an offline trained model often requires stream processing because you need to process the data in a pre-processing and/or feature transformation step prior to using the features in your model in the inference step. The simplified version architecture of the version is shown below. Essentially, the complexity arises in that whatever processing you did to the data in your offline training step, you need to do it in real-time in order to make an inference that is also in real-time. The features often include windowed calculations (avg, min, max, etc.) and aggregations (counts, sums, etc.), which require a stateful stream processor like Flink or Bytewax.
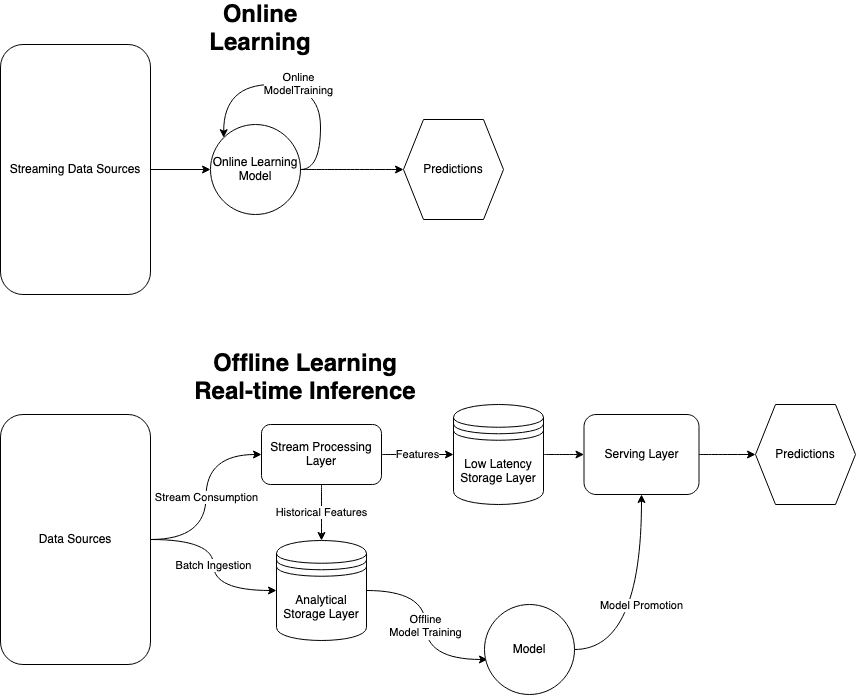
There are complexities that arise with moving your inference from batch to real-time. Complexities such as specialized hardware to facilitate high volumes and low latency as well as different processing technology to handle the transformation steps and storage mechanisms that allow for low latency, guaranteed ordering, and the ability to replay. This is a tradeoff from processing in batch, which has its own complexities around job dependencies and long-running jobs failing with no way to restart from mid-job.
In conclusion, real-time machine learning is a powerful tool that can be used to make predictions in near real-time, which can be crucial in a variety of industries. However, it requires specialized hardware and the ability to handle large amounts of data in real time for data pre-processing and feature engineering as well as inference. With the increasing availability of powerful hardware and the development of new techniques, we can expect to see real-time machine learning becoming more prevalent in the future.
Learn More
To get started with online machine learning with Bytewax, check out the google colab notebook from the talk I gave at pyData 2022 that uses the Python library river and stream processing techniques to detect wildfires. If you are looking for an example of using stream processing for feature transformation, a member of the Bytewax community has created a full ML stack built on Bytewax and Feast with example code that predicts crypto prices in real-time.
Are you looking to incorporate real-time ML into your organization? Join our slack community to share your use case and get feedback on what you are building. Also check out bytewax.
How to Handle Missing Values in Real-Time ML & AI in Python?

Zander Matheson
CEO, FounderZander is a seasoned data engineer who has founded and currently helms Bytewax. Zander has worked in the data space since 2014 at Heroku, GitHub, and an NLP startup. Before that, he attended business school at the UT Austin and HEC Paris in Europe.

